从开源工程看LLM文本类应用架构
开源项目
FastGPT(star 6.2k)
基于 LLM 大语言模型的知识库问答系统,提供开箱即用的数据处理、模型调用等能力。同时可以通过 Flow 可视化进行工作流编排,从而实现复杂的问答场景
Dify(star 44.2k)
一款开源的大语言模型(LLM) 应用开发平台。它融合了后端即服务(Backend as Service)和 LLMOps 的理念,使开发者可以快速搭建生产级的生成式 AI 应用。即使你是非技术人员,也能参与到 AI 应用的定义和数据运营过程中。
Langchain-Chatchat(star 31.1)
一种利用 langchain 思想实现的基于本地知识库的问答应用,目标期望建立一套对中文场景与开源模型支持友好、可离线运行的知识库问答解决方案。
项目实现原理
以上项目原理大体相同
如下图所示,过程包括加载文件 -> 读取文本 -> 文本分割 -> 文本向量化 -> 问句向量化 -> 在文本向量中匹配出与问句向量最相似的 top k个 -> 匹配出的文本作为上下文和问题一起添加到 prompt中 -> 提交给 LLM

中文版解释
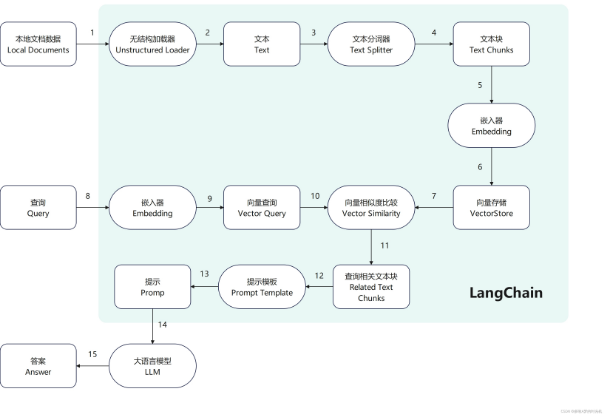
从文档处理角度来看,实现流程如下:

从架构设计角度看
几个项目各有异同,但是大概分为4层
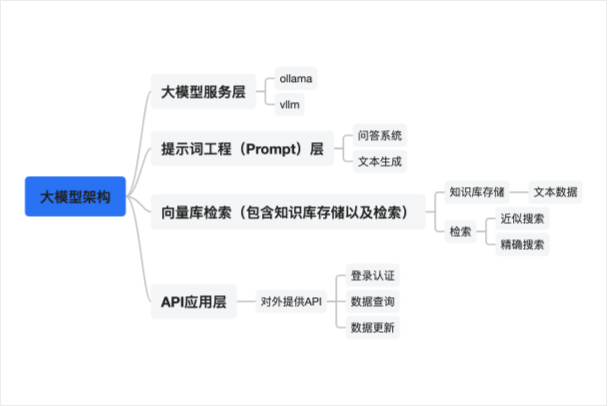
模型服务层
目前的架构趋向于将模型服务视为一个独立的服务,通过API进行集成。这种集成方式不仅可以通过OLLMA的API实现,还可以调用OpenAI的在线接口。这种设计将大型模型服务视为一个基础且可集成的功能,以便于在不同场景下实现灵活的应用。
这种架构的优势在于,它将模型服务与其他服务分离,使得各个服务可以独立进行升级和维护。同时,通过API进行集成,可以方便地实现不同服务之间的交互和协作。例如,在一个智能对话系统中,可以将模型服务与自然语言处理服务、知识图谱服务等集成,从而实现更丰富、更智能的对话功能。
此外,将模型服务视为一个可集成的能力,还有助于推动模型技术的快速发展。随着模型技术的不断进步,可以通过替换或升级模型服务来实现系统的升级,而无需对整个系统进行大规模的改动。这将极大地提高系统的可扩展性和可维护性。
总之,当前的架构将模型服务作为一个单独且可集成的功能,通过API进行集成,以实现更高效、灵活的系统设计和应用。这种设计不仅有利于各个服务的独立升级和维护,还可以推动模型技术的快速发展,提高系统的可扩展性和可维护性。
提示词工程
提示工程(Prompt Engineering)是一门较新的学科,关注提示词开发和优化,帮助用户将大语言模型(Large Language Model, LLM)用于各场景和研究领域。 掌握了提示工程相关技能将有助于用户更好地了解大型语言模型的能力和局限性。
研究人员可利用提示工程来提升大语言模型处理复杂任务场景的能力,如问答和算术推理能力。开发人员可通过提示工程设计、研发强大的工程技术,实现和大语言模型或其他生态工具的高效接轨。
提示工程不仅仅是关于设计和研发提示词。它包含了与大语言模型交互和研发的各种技能和技术。提示工程在实现和大语言模型交互、对接,以及理解大语言模型能力方面都起着重要作用。用户可以通过提示工程来提高大语言模型的安全性,也可以赋能大语言模型,比如借助专业领域知识和外部工具来增强大语言模型能力。
从当前应用看,目前大部分ai大模型应用方案基本是通过,提示词和有限的知识库检索实现
而提示词的生成也是各个应用核心
示例

向量检索层
目标是通过查询语句为提示词工程提供更精准的上下文信息。
目前方案一般有两种
倒排索引:使用类似es分词搜索方案,主要通过关键字检索
向量检索:能理解部分同义词,langchain或者llmindex 均会提供一定基础函数
向量检索嵌入式模型(Embedding):主要通过训练好的Embedding模型理解自然语言更精确,但需考虑模型对中文的支持
向量库存储对比
全文搜索数据库(例如ElasticSearch和OpenSearch)
能支持比较全面的文本检索和高级分析功能。但是当涉及到执行向量相似性搜索和处理高维度数据时,它们与专门的向量数据库相比就不够强了。这些数据库往往需要与其他工具搭配使用才能实现语义搜索,因为它们主要依赖于倒排索引而不是向量索引。根据Qdrant的测试结果,Elasticsearch在与Weaviate、Milvus和Qdrant等向量数据库相比时,性能有所落后。
pgvector
SQL数据库通过它们的向量支持扩展,提供了一种将向量数据整合到现有数据存储系统中的方式,但与专用的向量数据库相比,它们也又一些明显的缺点。
最明显的缺点是,传统SQL数据库的关系模型与非结构化向量数据的本质之间存在不匹配。这种不匹配导致了涉及向量相似性搜索的操作效率低下,这类数据库在构建索引和处理大量向量数据时性能表现并不理想,详见ANN测试。此外,pgvector支持的向量维度上限(2000维)与像Weaviate这样的专用向量数据库相比显得较低,后者能够处理高达65535维的向量数据。在可扩展性和效率方面,专用向量数据库也更有优势。支持向量的SQL数据库扩展,例如pgvector,更适合于向量数据量较小(少于10万个向量)且向量数据仅作为应用程序的一个补充功能的场景。相反,如果向量数据是应用的核心,或者对可扩展性有较高要求,专用向量数据库就会是更合适的选择。
Qdrant
1. 一个集合中可以存多种向量(图片、文字等)
2. 资源占用相当少
api 如果使用open api可能会出现联网获取许可问题
Weaviate
1. 性能相对不错
2. 支持内置嵌入
3. 支持文本搜索
4. GraphQL API
5. 支持S3备份
Milvus
1. 官方支持的可视化操作界面
2. 较高的搜索准确率
3. 丰富的SDK
- GPU加速

 浙公网安备 33010602011771号
浙公网安备 33010602011771号