1、应用程序直接操作的是文件,对文件进行的所有的操作,都是向操作系统发送系统调用,然后再由操作将其转换成具体的硬盘操作
2、控制文件的读写内容的模式:t和b
t文本(默认的模式):
- 读写都以str(unicode为单位)
- 文本文件
- 必须指定encoding='utf-8'
b(二进制/bytes)
3、
f = open(r"....../scarlett/0427/oldboy/a.txt",mode='rt',encoding='utf-8')
用内置函数 open() 用于打开一个文件,并返回“文件”对象,我们操作的就是这个对象;f的值是一种变量,占用应用程序的资源
res = f.read()
系统调用,然后由操作系统控制硬盘把输入读入内存,或者写入硬盘
f.close()
关闭文件,回收操作系统的资源,操作系统的资源是有限的,操作文件之后必须及时关闭
f.read()
会报错,变量存在,但是不能再读了
4、with...as...
会自动执行f.close()
![]()
注意:
必须加上encoding='utf-8'的编码(没有指定encoding参数操作系统会使用自己默认的编码,linux默认是utf-8,windows默认gbk)
内存:utf-8格式的二进制--解码--unicode
硬盘:(b.txt的内容,utf-8的二进制文件)
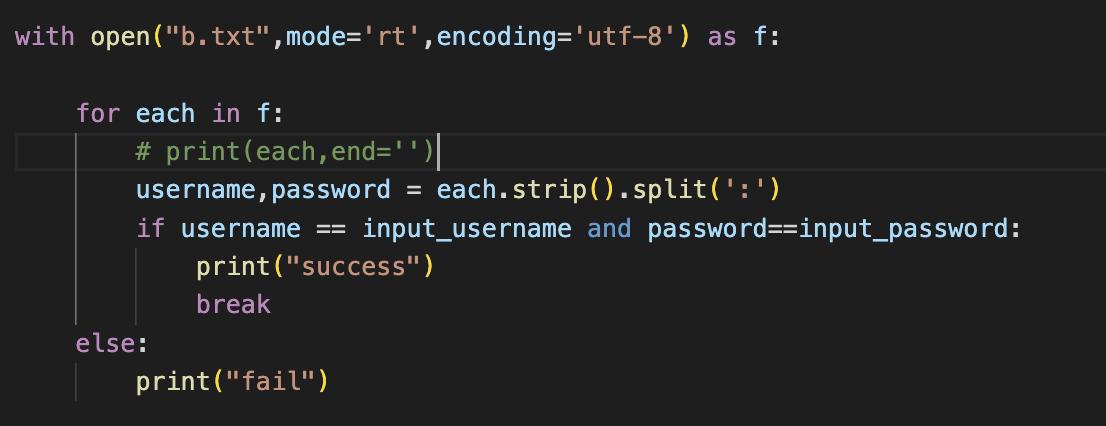
5、with open("b.txt",mode='rt',encoding='utf-8') as f:
r模式:只读模式,当文件不存在时报错,当文件存在时指针跳到开始的位置
f.read:把文件所有的内容从硬盘读入内存,读完之后指针会到末尾
for each in f : 每行每行的去读取,优势在于内存不会过大
不能进行写操作f.write
w模式:只写模式,当文件不存在时创建空新文件,当文件存在会清空文件,指针再最开始的位置。
不能进行读操作 f.read
with open("peng.txt",encoding='utf-8',mode='wt') as f:
f.write("哈哈哈哈\n")
f.write('砰砰砰\n')
a模式:只追加写,在文件不存在时会创建空文档,在文件存在是文件指针会直接跳到末尾
f.read()会报错
with open('a.txt',mode='at',encoding='utf-8') as f:
f.write('11111\n')
f.write('22222\n')
w和a的差别
相同的:在打开的文件不关闭的情况下,连续的写入,新写的内容会跟在前写的内容之后
不同点:以a的模式重新打开文件,不糊清空原文件的内容,会将文件指针直接移动到文件末尾
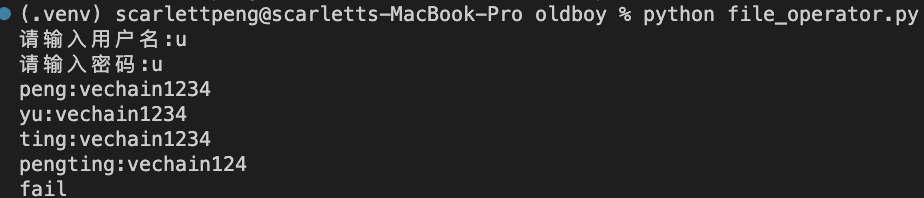
案例:a模式用于案例,w用于拷贝功能
![]()
+模式
![]()
x模式-文件不存在时新建,文件存在时报错,不可读可写
b模式-binary模式
1、读写都是以bytes为单位
2、可以针对所有文件
3、一定不能指定字符编码,即一定不能指定encoding
![]()
总结:
1、在操作纯文本文件方面t模式帮我们省去了编码和解码的环节,b模式则需要我们自己解码
2、针对非文本文件(如图片,视频,音频等)只能使用b模式
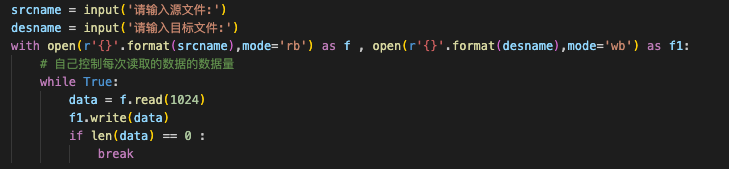
6、循环读取文件,防止内存占用过大
1、自己控制每次读取的数据的数据量,t模式下,read(n),n代表的是字符个数。但是r模式下,n代表的是字节个数。
![]()
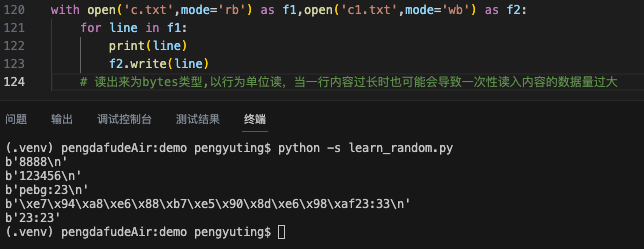
2、读出来为bytes类型,以行为单位读,当一行内容过长时也可能会导致一次性读入内容的数据量过大
![]()
7、readline readlines writeline writelines 以及文件其他操作方法
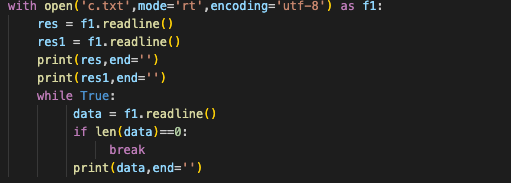
1、 f1.readline() 一次读一行
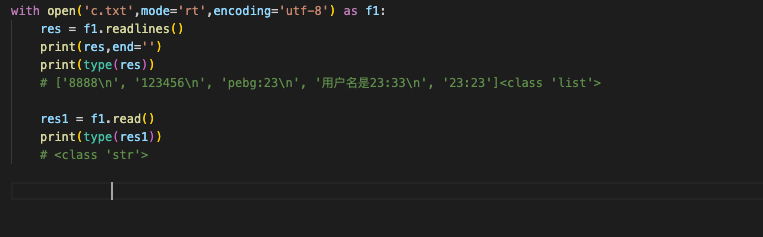
# 2、 f2.readline() 一次读取多行,读出来的返回值是数组形式
![]()
3、writeline
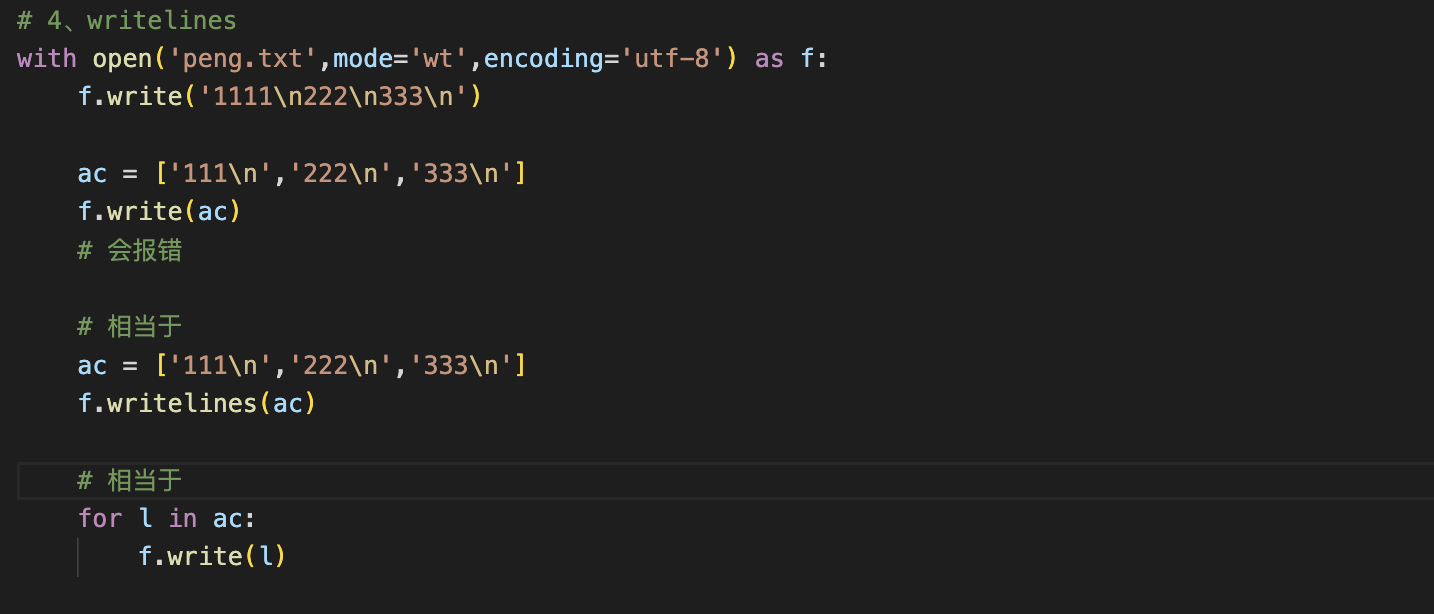
4、writelines,写进去的参数为数组
![]()
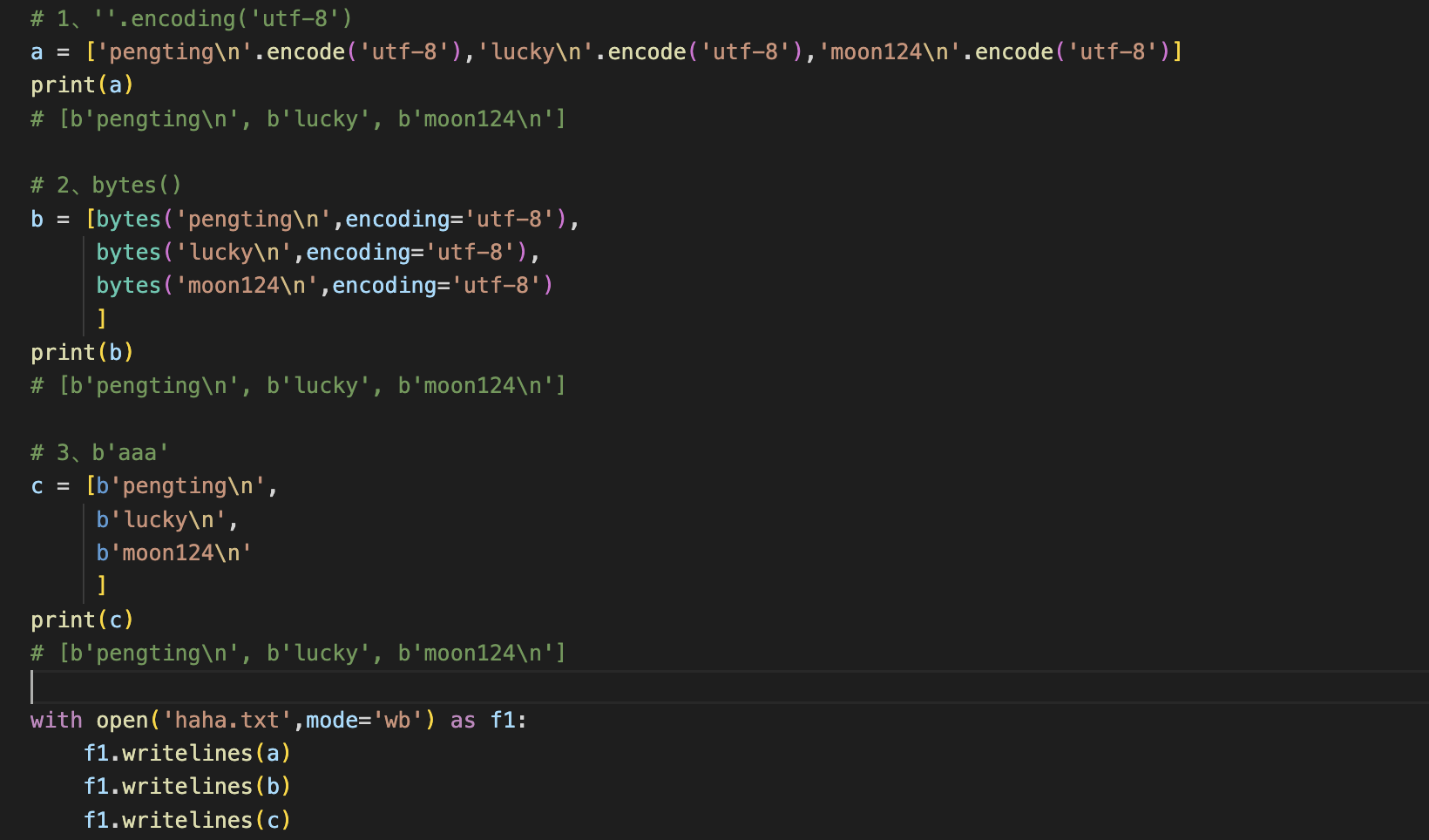
5、字节编码的三种方式
''.encoding('utf-8'),
bytes()
b'aaa'这种方式只适合于纯英文字符
![]()
f1.readable() 文件是否可读
6、
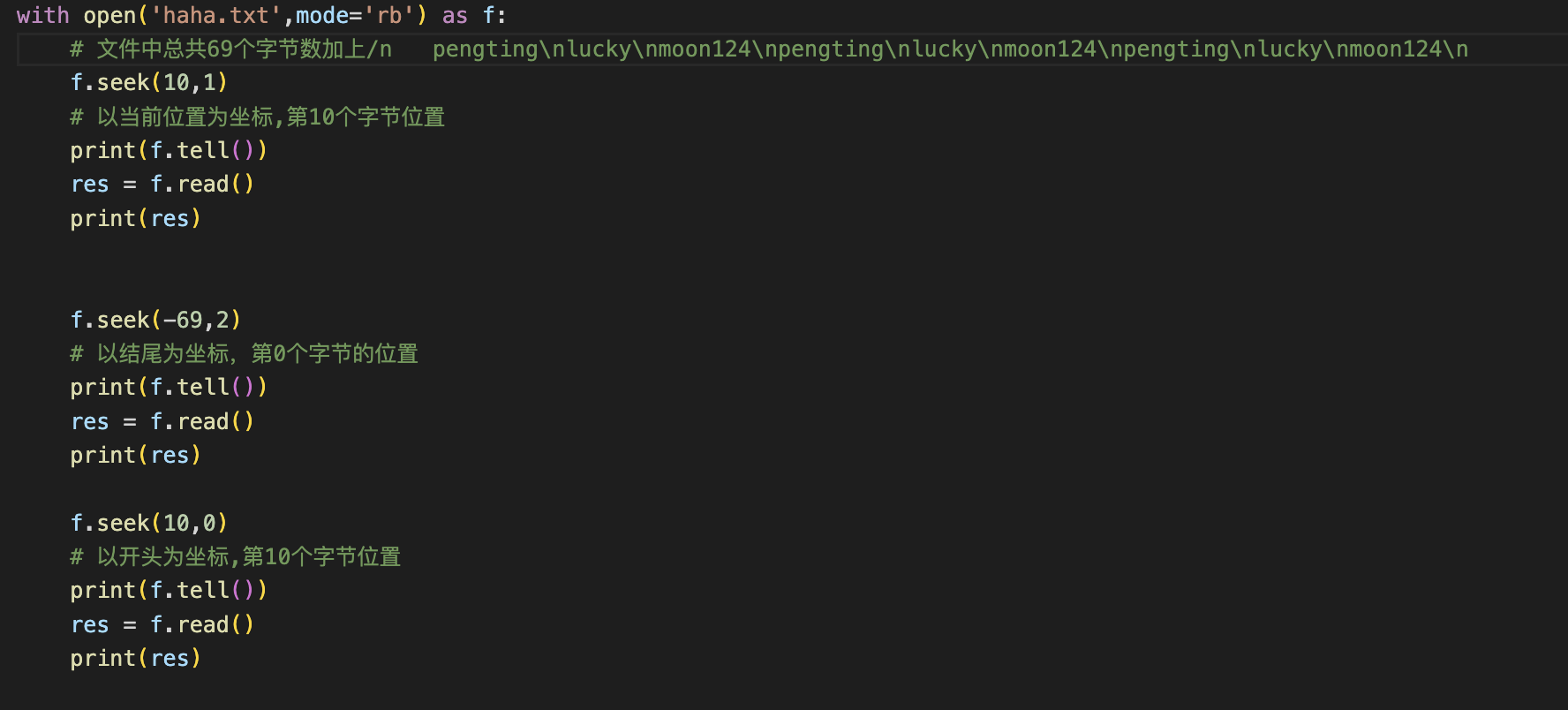
f.seek(n,m)
n代表移动的字节数,
m代表模式。0参照物是文件开头的位置,1参照物是当前指针所再的位置,2参照物是文件结尾的位置
f.tell() 获取文件指针当前的位置
特殊情况:
f.read(n) t模式下,n代表字符个数,其他都是以字节数为单位
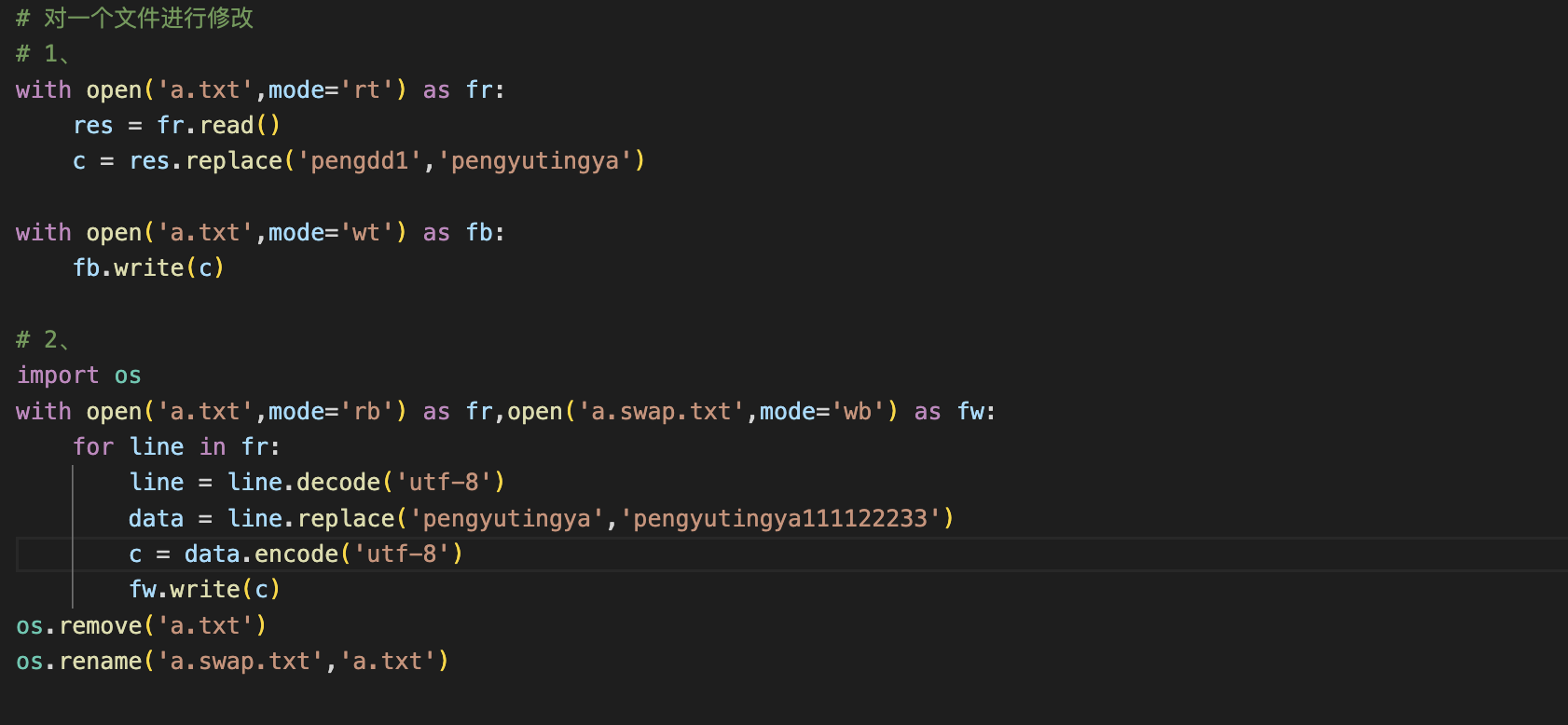
7、对文件进行修改






 浙公网安备 33010602011771号
浙公网安备 33010602011771号