① medium:中等策略。② random:随机策略。③ medium-replay:训到中等策略的整个 replay buffer。④ medium-expert:等量混合专家数据和次优数据(次优或随机策略)。
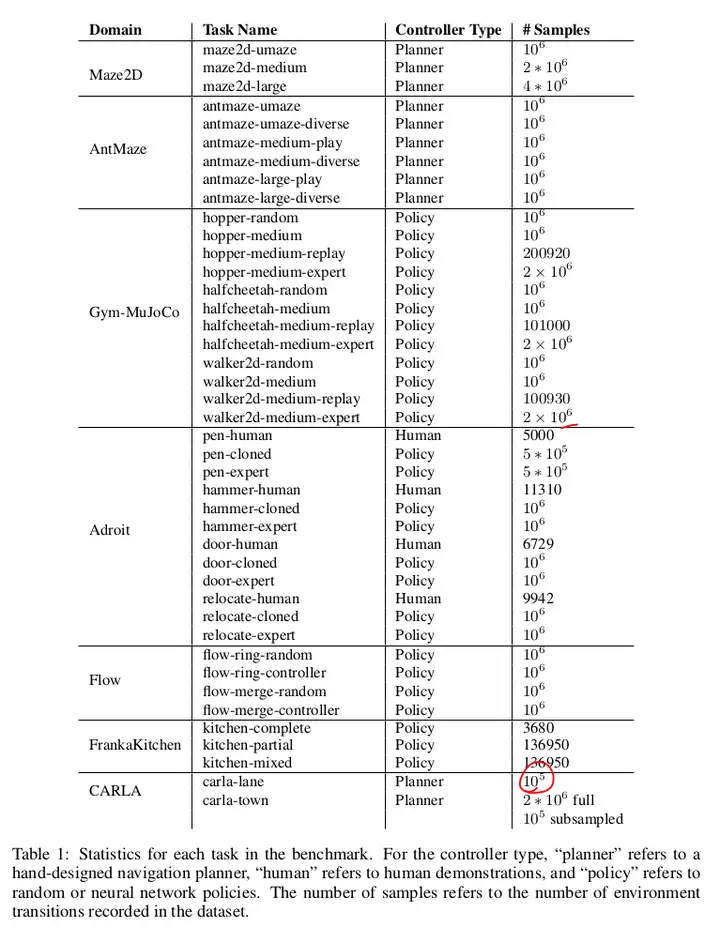
数据集简介
- Gym-MoJoCo(感觉是最常用的):
- medium:使用 online SAC 训练到一半,然后使用该策略收集 1M 的样本;
- random:利用随机初始化的策略,收集 1M 的样本;
- medium-replay:训练到中等质量水平,整个 replay buffer 收集的数据;
- medium-expert:等量混合专家数据集和次优数据集,次优数据通过次优策略或随机策略获得。
- Maze 系列:
- umaze / medium / large 是迷宫布局(迷宫形状与大小)。
- diverse 从随机起点到随机目标,play 起点和终点在一组固定点中随机选择。
- Adroit:
- 24 Dof 的灵巧手,非常困难。
- human:来自人类的少量 demo 数据(每个任务 25 个轨迹)。
- expert:使用训练良好的 RL 策略,生成大量数据。
- clone:通过在人类 demo 上训练模仿策略,运行策略,并以 1-1 的比例与人类 demo 数据混合。
- Franka Kitchen:
- 在包含几种常见家居用品(微波炉、水壶、顶灯、橱柜、烤箱)的厨房环境中,控制 9-DoF Franka 机器人。环境中具有多个任务,需要与不同的物品进行交互,以达成不同的任务目标。
- 难点(?):需要对 unseen state 泛化,而非完全依赖于 seen trajectory。貌似需要把 从先前任务中学到的 小段轨迹 拼接起来。
- complete:agent 按顺序执行所有所需任务,适用于 imitation learning。
- partial:agent 在做有意义的动作,但并不一定完成任务。partial 数据集的一个子集可以保证解决任务,这意味着,模仿学习 agent 可以通过有选择地选择正确的数据子集,来达成任务的学习。
- mixed:agent 在做有意义的动作,但并不一定完成任务。mixed 数据集不包含完全解决任务的轨迹,agent 必须学会组装相关的子轨迹。mixed 数据集需要最高程度的泛化才能成功。
- Flow 和 Carla,暂时不关注。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号