主要 trick:① 更新 A 时把 B stop-gradient,② 在 encoder 后添加神秘的 MLP 层。
算法思想
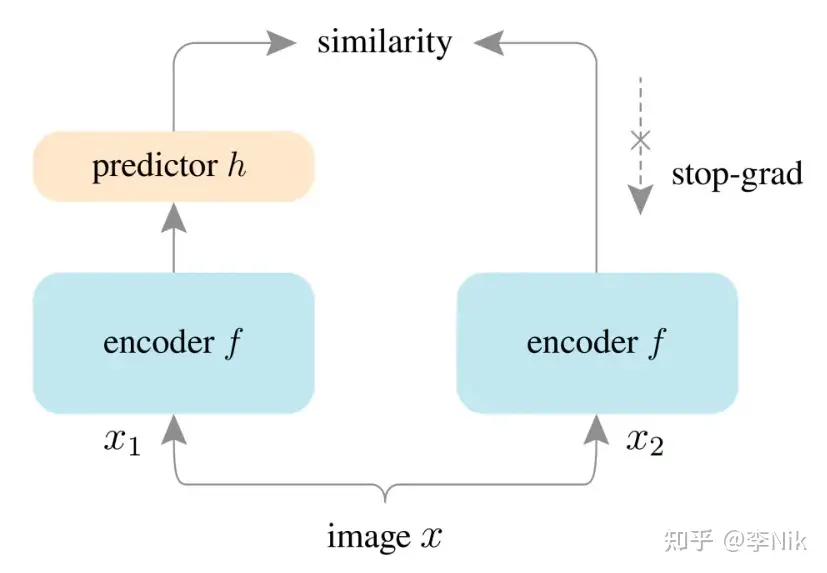
- 输入 x, x1, x2,其中 x 代表数据集中的一张图片,x1, x2 是数据增强(data augmentations)得到的两张图片。注意,原图片并不作为输入。
- 接下来,x1, x2 通过 同一个 编码器(encoder)编码,得到两个表征向量 z1=f(x1), z2=f(x2)。这个编码器一般使用经典卷积神经网络 ResNet。这一步的目的就是通过卷积神经网络提取特征,得到感受野大、维度较小的向量。
- 然后,我们将 z1 经过一个 MLP 映射得到 p1=h(z1) ,最大化 p1, z2 的 cosine similarity,作为目标函数去学习。其实,我们的目标函数是一个对称的(symmetric)函数,也就是不仅要算 p1, z2 的相似度,还要计算 p2=h(z2), z1 的相似度。
主要技术
- collapsing:
- 既然 loss function 只想让所有相似图片彼此接近,那么就把所有人映射到一起好了()
- 解决方案:设计不对称的 branch、训练负样本彼此远离、stop-gradient 等。
- stop-gradient:
- 神秘的 MLP 层 h :
- 作者发现,如果不添加 h,性能很差;如果 h 的参数无法学习,模型难以收敛。这个 MLP 层实际上是在 预测数据增强分布上的数学期望,从而试图矫正由数据增强带来的随机性而导致的误差。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号