offline RL | 读读 Decision Transformer
- 论文标题:Decision Transformer: Reinforcement Learning via Sequence Modeling,NeurIPS 2021,6 6 7 9 poster(怎么才 poster)。
- pdf:https://arxiv.org/pdf/2106.01345.pdf
- html:https://ar5iv.labs.arxiv.org/html/2106.01345
- open review:https://openreview.net/forum?id=a7APmM4B9d
- 项目网站:https://sites.google.com/berkeley.edu/decision-transformer
- GitHub:https://github.com/kzl/decision-transformer
- 相关博客:
目录
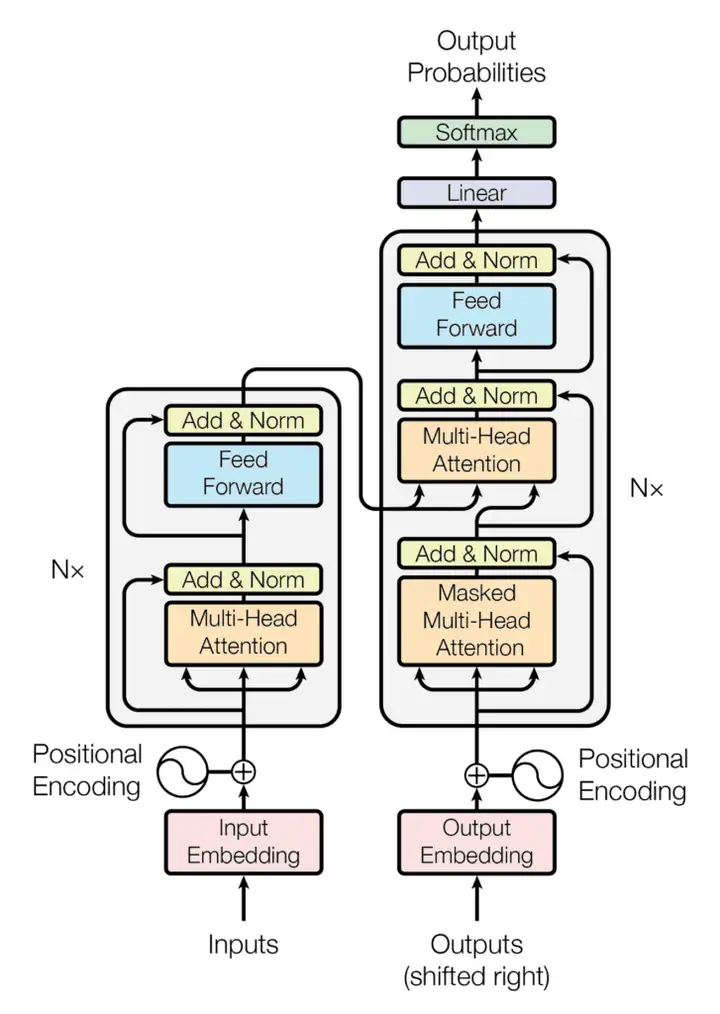
1 Transformer 是一种 seq2seq 建模方法
(著名的 GPT 的全称是 Generative Pre-trained Transformer)
学习 Transformer:
- 知乎问题 | 如何最简单、通俗地理解 Transformer?
- 知乎问题 | Transformer 的技术细节到底是怎么样的?
- 知乎问题 | 为什么我还是无法理解 Transformer?(回答 1)
- 知乎问题 | 为什么我还是无法理解 Transformer?(回答 2)
seq2seq 的输入输出:
- 在 nlp 领域貌似是 word embedding,然后再使用 word2vec 之类得到单词(?)
Attention 与 Transformer:
- attention:
- key query value:key 用来提取关键信息、query 用来提取查询、value 用来提取值。它们具有矩阵形式,用 k q v 矩阵去乘输入的 vector,得到 k q v 的 vector。
- k q v 举例:希望投票选举,query - 评委的重要程度、key - 评委的职称(?)、value - 评委的投票结果,最后按照 (query × key^T) × value 的形式,对投票结果进行加权计算。 multi-head-attention 就是使用多组 k q v,可能表示我们希望关注多个方面。
- encoder:
- 一个 encoder 块包含一个 attention + 一个 feed forward 层(大概就是全连接层)。
- 我们使用 k q v 的 attention 模块,一下对所有 token 的矩阵(维度 num of tokens × embedding size)得到一个 latent z(维度 num of tokens × latent size)。
- 然后对于每个原句子中的 token,各过各的全连接层(feed forward)(?)最后得到一个 维度 num of tokens × embedding size 的矩阵。
- 残差连接(Res):将输入和 多头注意力层 或全连接神经网络的输出 相加,再传递给下一层,避免梯度递减的问题。
- decoder:
- 一个 decoder 块包含两个 attention + 一个 feed forward 层。
- attention 1 用来处理自己输出的信息,因此它在说第 n 个单词之前,只能以自己说出的前 n-1 个单词作为输入,使用一个掩码(?)来实现:掩码多头自注意力(Masked-Multi-head self attention)。
- attention 2 用来处理 encoder 给出的 num of tokens × embedding size 的 embedding,attention 1 的输出也是其输入的一部分。
- 这样,看图应该就能看懂了。
2 建模 RL 的 sequence
我们的 sequence:{reward-to-go, state, action, reward-to-go, ...}
- 形式类似于 \(\{s_t,a_t,r_t,s_{t+1},\cdots\}\) 。
- reward-to-go: \(\hat R_t=\sum_{t'=t}^Tr_{t'}\) ,是从此刻 t 到 episode 结束的,in-discounted reward 的加和。
- 感觉 reward-to-go 类似于 HER 的预期目标,比较 hindsight。
3 如何训练 DT
对 sequence {s, a, R, s, a, R, ...} 进行处理:
- 对每个 modality(s a R),都学习了将它们转换为 embedding 的线性层。
- 对于具有视觉输入的环境,状态被输入到卷积编码器而不是线性层中。
- 此外,每个时间步的 embedding 都会被学习并添加到每个 token 中 —— 这与 transformer 使用的 positional embedding(三角函数?)不同,因为一个时间步对应于三个 token。
(搬图,搬运文字说明)
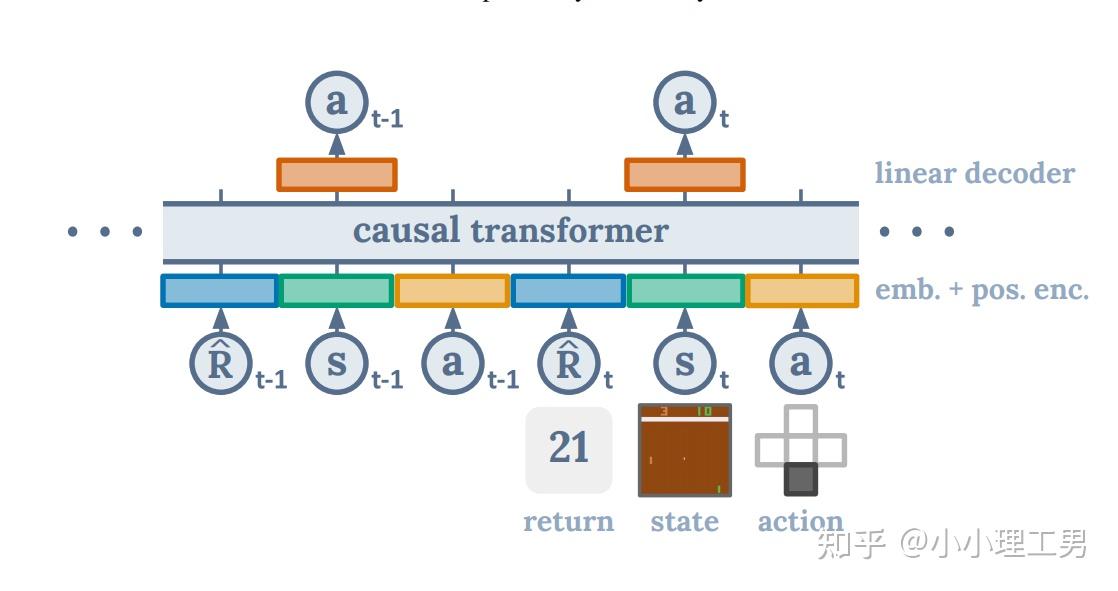
- 一条轨迹按照 s a R 顺序排列好后,每个元素都是图 1 下部的一个小圆圈,类似于 NLP 中的一个个单词。
- 然后,每个元素经过一个 mlp 做 embedding 后,再加上 position encoding,就得到了 tokens,也就是图 1 下部的一个个五颜六色的小长方块。
训练:
- 使用 offline trajectory 的 dataset(D4RL 之类)。
- 从离线轨迹数据集中,抽取 sequence 长度为 K 的 minibatch。
- 训练:对 input token \(s_t\) 的那个 prediction head,再加一个 mlp 来预测 \(a_t\) (上图上部输出 \(a_t\) 的橙色方块)。
- 训 action 时,对离散动作使用 cross-entropy loss,连续则使用 MSE。
- DT 每隔三个 token 才 decode 一个,因为作为 policy 只需要输出 action。但其实,output tokens 由对应 reward-to-go、state、action 的 token 组成,所以自然只留下对应 action 的 tokens(?)
- 发现,去预测 state 或 reward-to-go 并不能提高性能,尽管在 DT 框架里,很容易这么做。
- 上述训练部分是想让 DT 学会,在某个特定状态 s 下,达到 reward-to-go R,所需要做的动作 a。
- 详见 Algorithm 1 伪代码,感觉写的很清楚。
4 如何部署 DT policy / 如何 inference
- inference 过程就是,首先提出一个 target return(我们希望 agent 在一个 episode 里能达到的 return),作为初始的 reward-to-go,然后 DT 按照训练过程中学到的 如何达成 reward-to-go 的方法,选择 action。
- 每走一步,就将上一步的 reward-to-go 减去这一步的 reward,得到下一个 reward-to-go,从而不断地更新我们期望 DT 达到的 return 目标,同时 DT 根据我们的目标,不断选择 action。
- 详见 Algorithm 1 伪代码。
- evaluate 时,只保留 length = K 的 context,对应于前面训练时 sequence length = K。
- 通常认为,当使用 frame stacking(Atari 的帧堆叠)时,K = 1 已经 MDP,足以用于 RL 算法。然而,当 K = 1 时,Decision Transformer 的性能明显更差,这表明过去的信息对 Atari 游戏有用(非 MDP?)。(具体实验中,Atari 的 K = 30 50,MuJoco 的 K = 5 20)
- 一个假设是,当我们表示 一些策略的分布时(例如序列建模),上下文允许 transformer 识别,哪个策略生成了该动作,从而实现更好的学习和 / 或改进训练动态。
5 技术细节
- 训练的一些超参数,encoder / decoder:可参见 Table 8 9。
- 在 inference 过程中,如何选择 reward-to-go:使用 dataset 中最大 return 的一倍或 5 倍。
- Warmup tokens 为 512 ∗ 20,是 <begin> <end> 这种 token 嘛?
6 一些讨论
- (Section 5.7)DT 为什么不需要 pessimistic value 或行为正则化?作者猜想:pessimistic value 和行为正则化是为了避免 value function approximation 带来的问题,但 DT 并不需要显式优化一个函数(?)
- (Section 5.8)声称 DT + Go-Explore(RL exploration 方法,感觉像打表)可以帮助 online policy。
- Credit assignment 貌似是一类工作,通过分解 reward function,使得某些“重要”状态包含了大部分 credit。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号