
快学scala
快学scala
标签(空格分隔): scala
第五章 类
5.1 类中属性的定义
-
属性的声明:
scala类的属性有4种方法定义:var,val,private var, 同类对象私有字段private[this] varclass Person{ var varage = 0 // 类中所有var产生公有的setter和getter val valage = -1 // 类中所有val产生公有的getter private var age1 = 0 // 产生私有的setter和getter private[this] var age2 = 3 // 不产生setter,getter // 通过复写setter和getter def age = age2 // getter def age_=(newAge:Int) = { // setter : field_= this.age2 = newAge } } -
scala的setter和getter调用
val p = new Person p.varage_=(2) // setter p.age // getter
5.2 类的构造器
-
主副构造器
(1)如果一个类没有显示的声明主构造器,则会自动加入无参构造
(2)辅助构造器名称为this(避免修改类名时要修改多个辅助构造器的名称)'
(3)辅助构造器的开头必须以主构造器开始
(4)主构造器中的字段会自动被解析成类中的属性class Person(var name:String,var age:Int){ def this(name:String){ this(name,-1) } def update(name:String,age:Int) = { print("update function is called") this.age = age } } -
伴生对象
(1)伴生对象适用于既有实例方法,又有静态方法的时候
(2)伴生对象中的apply方法可以用来不带new产生对象,apply的方法体要调用伴生类的主/辅助构造器方法
(3)伴生对象中的unapply方法,可以在模式匹配中用于属性匹配object Person{ def apply(name: String): Person = new Person(name) def unapply(arg: Person): Option[Int] = Option(arg.age) } // 继承的写法 class Student(name:String,age:Int,val sid:String) extends Person(name){ } object Main extends App{ val p = Person("lj") // 利用伴生对象的apply方法产生对象 p match { // 模式匹配相当于手动调用了下面的unapply方法 case Person(-1) => println("match success") } if (Person.unapply(p).get == -1) println("unapply match success") val s1 = new Student("lj",26,"09101306") p("lj") = 27 // update function }
5.3 枚举类型
- 声明枚举类型
(1)object继承Enumeration
(2)枚举的属性调用Value方法
(3)枚举的name自动设置为属性名object Color extends Enumeration{ val Red = Value val Yellow = Value } object Test1 extends App{ println(Color.Yellow.toString) // Yellow println(Color.Yellow.id) // 1 }
5.4 Option类
- Option的子类有Some和None。
- 通过Some的构造器,讲一个cal转换为Option类型的字段
def getOptval(aaa:Person):Option[Person] = Some(aaa)
print(getOptval(new Person(1,2)).get) //Person@7921b0a2
第十三章 集合
13.1 scala的集合继承层级
(1)所有集合继承自Iterable特质,因此,访问所有集合的通用代码为:
val coll = ... // 某种集合
val iter = coll.iterator
while(iter.hasnext)
iter.next
(2)scala的集合大致分为3类:
i) Seq:按照插入顺序排序的序列
ii) Set:每次插入一个元素,都会根据某种经排序方法决定元素在集合中所处的位置。set中没有重复的元素
iii) Map:键值对对偶
13.2 Seq类型的集合
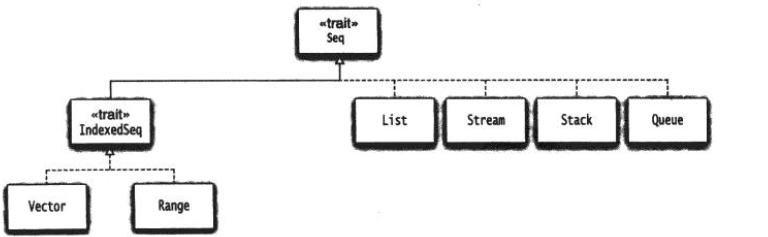
一. Seq的继承层级
-
不可变序列:
![1.png-62.4kB]()
(1)Vector是ArrayBuffer的不可变版本,它拥有下标,以树型结构存储节点,支持快速的随机访问。每个节点最多可存放32个子节点。因此,对于一个100万个元素的向量,只需要四层节点(\(10^6 \approx32^4\)),访问任意一个元素,最多只需要4眺
(2)Range是一个整数序列,比如1,2,3,4,5,6,7,8,9 它不存储所有元素,只存储起始值,结束值和增值 -
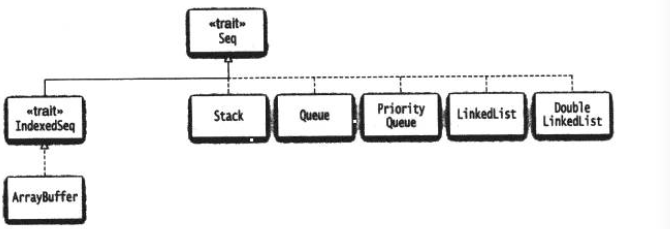
可变序列:
![bb.png-56.3kB]()
二. 列表
-
scala中的列表要么是Nil(空表),要么是一个head元素加上一个tail(列表)。以下列表的声明等价
scala> 9::4::2::Nil res5: List[Int] = List(9, 4, 2) scala> List(9,4,2) res6: List[Int] = List(9, 4, 2) scala> 9::List(4,2) res7: List[Int] = List(9, 4, 2) -
集合操作
(1)向后追加元素(:+),向前追加元素(+:) (只用于向插入顺序有关的集合中追加)scala> val v1 = Vector(1,2,3,4) scala> v1 :+ 8 res27: scala.collection.immutable.Vector[Int] = Vector(1, 2, 3, 4, 8) scala> 9 +: v1 res28: scala.collection.immutable.Vector[Int] = Vector(9, 1, 2, 3, 4)
(2)+操作符,向Set等与插入顺序无关的集合中追加元素
scala scala> val s1 = Set(1,2,3,4) scala> s1 +9 res31: scala.collection.immutable.Set[Int] = Set(1, 9, 2, 3, 4)
(3)++与--分别为向集合中追加多个元素
三. 化简,折叠,扫描
-
reduceLeft和reduceRight
(1)coll.reduceLeft(op)表达式,将op函数相继应用到集合中的元素,如图形成一个树形结构
(2)reduceLeft是从集合的左端开始,reduceRight是从集合的右端开始scala> List(1,7,2,9).reduceLeft(_-_) // 1-7-2-9 scala> List(1,7,2,9).reduceRight(_-_) // 1-(7-(2-9)) res31: Int = -13 -
foldLeft和foldRight
(1)折叠方法让调用者可以自定义集合计算的初始元素,进行树型结构的计算scala> List(1,7,2,9).foldRight(5)(_-_) // 1-(7-(2-(9-5))) = -8 scala> List(1,7,2,9).foldLeft(5)(_-_) // 5-1-7-2-9 res33: Int = -14
(2)foldLeft和foldRight的简写形式:/:和:\
```scala
scala> (5 /: List(1,2,3))(_-_) // 5-1-2-3
res35: Int = -1
```
(3)利用折叠方法计算词频
初始化一个空Map[Char,Int],每一步将频率映射和新遇到的字母结合在一起
scala scala> (Map[Char,Int]() /: "Mississippi"){(m,c) => m + (c -> (m.getOrElse(c,0)+1))} res43: scala.collection.mutable.Map[Char,Int] = Map(M -> 1, s -> 4, p -> 2, i -> 4)
3. scanLeft和scanRight将折叠和映射组合在一起,得出每一次计算的中间结果
```scala
scala> List(1,2,3,4).scanLeft(0)(_-_)
res46: List[Int] = List(0, -1, -3, -6, -10)
```
13.3 流
-
定义:
(1)Stream是一个尾部被懒计算的不可变列表,通过操作符#::可以构造一个流
(2)Strea的尾部懒计算后会缓存起来scala> val tenMore = numsFrom(10) tenMore: Stream[BigInt] = Stream(10, ?) scala> tenMore.tail.tail res51: scala.collection.immutable.Stream[BigInt] = Stream(12, ?) res52: Stream[BigInt] = Stream(10, 11, 12, ?) // 10,11,12已经过缓存
(3)用take获得多个答案,然后用force强制求值
scala scala> tenMore.take(5).force res54: scala.collection.immutable.Stream[BigInt] = Stream(10, 11, 12, 13, 14)
(4)不要不经take直接调用force,否则会一次计算出stream的所有尾值,知道内存溢出
13.4 懒试图
-
所有的集合都能通过view方法转换为懒计算的视图,视图不同于流,连第一个元素也不去计算
scala> (0 to 5) res55: scala.collection.immutable.Range.Inclusive = Range(0, 1, 2, 3, 4, 5) scala> (0 to 5).view // 视图 res56: scala.collection.SeqView[Int,scala.collection.immutable.IndexedSeq[Int]] = SeqView(...) scala> (0 to 5).view.map(_*2) // SeqView(....):所有元素全不计算 res57: scala.collection.SeqView[Int,Seq[_]] = SeqViewM(...) scala> (0 to 5).view.map(_*2).force res58: Seq[Int] = Vector(0, 2, 4, 6, 8, 10)
第十五章 高级类型
本章要点:
- 列表项
18.1 单例类型
1. 定义:
对于任意一个引用对象v,可以得到一个类型v.type。这个类型有两个可能的值:v(对象本身,但以类型的形式出现) 和 null
2. 用法:
对于那种返回this的方法,通过this.type把这些方法串接起来
(1)错误写法:Document类的setter方法最后返回了this,而该方法的返回值类型如果直接写成Document,虽然可以串联调用setTile和setAuthor,但是一旦出现Document的子类Book,则Book产生的对象调用setatile后返回的类型被写成Document,也就不能串联调用setATitle和setAuthor
// 错误示例
class Document {
def setTitle(title: String):Document = {
println("set title:" + title)
this
}
def setAuthor(author:String):Documente = {
println("set author:" + author)
this
}
}
val doc = new Document()
doc.setAuthor("lj").setTitle("scala Education") // setAuthor返回的Document类型,可以串联调用setTitle
class Book extends Document{
def addChgapter(chapter:String) :Book = {
println("add chapter:" + chapter)
this
}
}
val book = new Book()
book.setTitle("another book").addChgapter("1 chapter") // 编译报错,因为setTitle返回的类型是Document,而Document类没有addChapter方法
(2)正确写法:为了使继承Document的Book类的对象也能串联调用,可以改造这些setter方法的返回值为this.type,这样,Book类的对象book在调用setTitle方法时,返回的类型就是book.type,而由于book对象有一个addChapter方法,因此可以串接起来
class Document {
def setTitle(title: String):this.type = {
println("set title:" + title)
this
}
def setAuthor(author:String):this.type = {
println("set author:" + author)
this
}
}
class Book extends Document{
def addChgapter(chapter:String) :this.type = {
println("add chapter:" + chapter)
this
}
}
val book = new Book()
book.setTitle("another book").addChgapter("1 chapter")
(3)其次,如果想要定义一个接收object实例作为参数的方法,也可以使用单例类型。那么为什么对于单例对象的方法不直接调用,还要传进一个object对象作为参数在调用呢?因为有人喜欢构造那种调用起来像是一句话的代码
book set Title to "Scala for the impatient"
object Title
class Document {
private var useNextArgAs:Any = null
// 用Title.type声明传入的是Title单例对象, 用this.type声明返回值使得集成类的setter方法也能串联调用
def set(obj:Title.type):this.type = {
useNextArgAs = obj
this
}
def to(arg:String) : Unit={
if (this.useNextArgAs==Title)
println("set finish")
else
""
}
}
object Test extends App{
val doc = new Document()
doc set Title to "scala for the impatient" // 构造英文语句
}
18.2 类型投影
一. 内部类的细粒度控制
-
scala中,嵌套类属于它包含的外部对象,即每个实例都有自己的内部类
如下,chatter.member和myFace..member是不同的类。不能讲任何一个网络(NetWork)的成员(Member)加到另一个网络中class NetWork{ class Member(val name:String) { val contacts = new ArrayBuffer[Member] // 这个泛型Member,指的是[对象.Member] } private val members = new ArrayBuffer[Member] def join(name:String) :Member= { val m = new Member(name) members += m m } } val chatter = new NetWork val myFace = new NetWork val Fred = chatter.join("Fred") val Barney = myFace.join("Barney") Fred.contacts += Barney -
内部类从属于每个对象这种约束是默认存在的,如果不想要这种约束,应该把Member类挪到NetWork类的外面。更好的选择是在Network的伴生对象中。如果想使用更为松散的定义,可以用
类型投影NetWork#Member,表示任何Network的Memberclass NetWork{ class Member(val name:String) { val contacts = new ArrayBuffer[NetWork#Member] //val contacts = new ArrayBuffer[Member] // 这个泛型Member,指的是[对象.Member] } ... }
18.3 类型别名
- 对于复杂类型,eg:
HashMap[String,(Int,Int)],可以使用type关键字创建一个简单别名,eg:index。 - 类型别名必须嵌套在类或对象中,他不能出现在scala文件的顶层
class Book{
import scala.collection.mutable._
type index = mutable.HashMap[String,(Int,Int)]
}
18.5 结构类型
1. 定义:
结构类型是一组关于抽象方法,字段和类型的规格说明,这些抽象方法,字段,类型是该规格类型必须具备的。
写法上:用大括号包围这些抽象方法,字段,类型
2. 可以用结构类型声明函数的形参类型
下例所示,appendlines方法的形参是任何具有append方法的对象和一个string泛型的iterater,appendlines会调用这个对象的append方法
def appendLines(target: {def append(str:String): Any},lines:Iterable[String]): Unit ={
for(l <- lines){
target.append(l);target.append("\n")
}
}
3. 结构类型也称作鸭子类型
鸭子类型就像python这种动态类型语言,变量没有类型,当你写下obj.quack()时,运行时回去检查obj指向的对象在那一刻是否具有quack方法。换句话说:你不需要把obj声明为Duck类型,只要它运行时有Duck的方法(走起来,叫起来像鸭子一样)
18.6 符合类型
1. 定义:
符合类型的定义形式如下: \(T_1\) with \(T_2\) with \(T_3\) ...,表示要成为该复合类型的实例,必须满足每一个类型的要求(比如实现了这几个特质的方法),因此,符合类型也称作交集类型
val images = new ArrayBuffer[java.awt.Shape with java.io.Serializable]
val rect = new Rectangle(5,10,20,30) // Rectangle extends Rectangle2D implements Shape,java.io.Serializable
images += rect
2. 符合类型的后面可以加上结构类型
new ArrayBuffer[java.awt.Shape with java.io.Serializable {def setBounds(x: Int, y: Int, width: Int, height: Int):Unit}]
表示这个ArrayBuffer里的对象既要满足Shape和Serializable接口,还要存在setBounds方法
18.7 中置类型的写法
1. 写法:
(1)scala提供了一种让类型的描述趋于数学中置表达式形式的写法:用中置表达式组合多个泛型。eg:用String Map Int来表示Map[String,Int]
(2)写法:泛型1 类 泛型2
(3)中置表达式也可以用来模式匹配,eg:
case class Person[S,T](val name:S,val age:T)
val p : String Person Int= Person("摇摆少年梦",19)
p match {
case "摇摆少年梦" Person 18=> println("matching is ok")
case name Person age=> println("name:"+name+" age="+age)
}
18.8 存在类型
1. 定义
(1)scala的存在类型是为了与java的类型统配符兼容
(2)写法:在类型表达式后面跟上forSome{},里面包含了type和val的声明,这些声明是对被forSome修饰的类型做一个限制。
2. type限制
下例中,t1的存在类型和t2的类型通配符是等价的,类型通配符是存在类型的语法糖
type t1 = Array[T] forSome { type T<:JComponent}
type t2 = Array[_<:JComponent]
// 存在类型允许使用更复杂的类型关系
type t3 = Map[T,U] forSome {type T,type U<:T}
3. val限制
有的嵌套类通过类型投影NetWork#Member,扩大了泛型范围。但一些方法又想把嵌套类局限于每个对象的嵌套类,就是用存在类型加以限定
val chatter = new NetWork
val myFace = new NetWork
val Fred = chatter.join("Fred") // 同一个网络下的成员
val Fred2 = chatter.join("Fred2") // 同一个网络下的成员
val Barney = myFace.join("Barney") // 不同网络
Fred.contacts += Barney
def process[M <: n.Member forSome { val n:NetWork }](m1:M,m2:M) = (m1,m2)
process(Fred,Fred2) //process(Barney,Fred2) => 错误:process方法通过forSome里面的val n:NetWork限制了n.Member为对象自身的嵌套类,使得方法接收相同网络的成员,拒绝不同网络的成员
18.9 自身类型
1. 定义
(1)自身类型是对特质自身的一种限制,它指出该特质只能被混入哪个类中,或智能被混入哪个类的子类中
(2)形式:this: 类型 =>
trait Logged{
def log(msg:String)
}
trait LoggerException extends Logged{
this:Exception => // 这个this指代混入特质后的对象
def log(){
log(getMessage()) // getMessage方法来自于this,而this又是Exception的子类
}
}
object Test extends App{
type f = JFrame with LoggerException // 定义类型时不报错,创建对象时会因为LoggerException的自身类型限制而报错
// val v1 = new f // 报错:f类型是JFrame混入LoggerException,而JFrame不是Exception的子类
}
2. 继承带有自身类型特质的特质
(1)如果自带有自身类型限制的特质被另一个特质集成,则子特质必须重复写出自身类型,表示自己和父特质一样也有混入的限制
trait ManagedException extends LoggerException{
this:ArrayIndexOutOfBoundsException => // 这里的类型限制要定义成Exception或其子类
def say(){print("aaa")}
}
18.11 依赖注入
1. 场景
(1)设想一个应用,他需要日志和验证功能,当然,验证功能也需要用到日志。
(2)设计:因此,可以把日志和验证设为2个特质Logger和Auth,这两个特质分别有自己不同的实现。而真正的应用类App,只要混入这些不同的实现组合,就能使得App拥有日志和验证功能。而Auth需要用到Logger,所以在Auth特质中,通过自身类型调用Logger类型的方法
trait Logger{
def log(msg:String)
}
trait Auth{
this:Logger => // 自身类型调用Logger特质的方法
def login(id:String,passwd:String):Boolean
}
trait FileLogger extends Logger{
override def log(msg: String): Unit = {
println(msg)
}
}
trait MockAuth extends Auth{
this:FileLogger =>
override def login(id: String, passwd: String): Boolean = {
if(id.equals("guest")) {
log("guest login fail..")
false
}else
true
}
}
object App extends FileLogger with MockAuth{ // 此处通过依赖注入变换实现
def main(args: Array[String]): Unit = {
login("guest","123456")
}
}
(3)这种方法的怪异之处在于,一个App并非是验证器和文件日志器的组合。更自然地表述方式是使用成员变量来实现功能组件,而不是把App通过混入特质变成一个巨大的类型。
trait LogComponent{ // 最外层的大组件
trait Logger{
def log(msg:String)
}
val logger:Logger // 抽象变量
class FileLogger extends Logger{
override def log(msg: String): Unit = {
println("write in file: "+msg)
}
}
}
trait AuthCompnonent{ // 最外层的大组件
this:LogComponent => // 使用抽象变量logger
trait Auth{
def login(id:String,passwd:String):Boolean
}
val auth:Auth // 抽象变量
class MockAuth extends Auth{
override def login(id: String, passwd: String): Boolean = {
if (id.equals("guest")){
logger.log("guest cannot login") // 这个logger变量来自于LoggerComponent,到底是哪个实现取决于继承的特质
false
}else
true
}
}
}
object App extends LogComponent with AuthCompnonent{
override val logger = new FileLogger // 成员变量
override val auth = new MockAuth // 成员变量
def main(args: Array[String]): Unit = {
auth.login("guest","123456")
}
}
18.12 抽象类型
1. 定义
(1)类或特质中,定义一个在子类中被具体化的抽象类型。eg:如下的Reader特质:
trait Reader{
type Contents
def read(fileName:String):Contents
}
class StringReader extends Reader{
override type Contents = String
override def read(fileName: String):Contents = Source.fromFile(fileName,"UTF-8").mkString // mkString method return string, corresponding with TYPE contents
}
class ImageReader extends Reader{
override type Contents = BufferedImage
override def read(fileName: String): Contents = ImageIO.read(new File(fileName))
}
(2)当然,在需要子类给出抽象类型的实现这种方法,还可以通过类型参数实现
trait Reader[C]{
def read(fileName:String):C
}
class StringReader extends Reader[String]{
override def read(fileName: String) = Source.fromFile(fileName,"UTF-8").mkString
}
class ImageReader extends Reader[BufferedImage]{
override def read(fileName: String) = ImageIO.read(new File(fileName))
}
2. 抽象类型和类型参数的好坏对比
(1)如果类型是在创建对象时给出时(不存在继承该类的子类),就应当使用类型参数。比如构建HashMap[String,Int]
(2)如果类型是在子类中给出,则使用抽象类型。比如上面的Reader就是子类中给出。
(3)当然还有一种情况是,在子类中给出类型参数。这种方法没什么不好,但是一旦父类或父特质中有多个类型参数,子类的定义就会变得冗长。eg:Reader[File,BufferedImage],这样会使得伸缩性变差
3. 抽象类型可以有类型界定
trait Listener{
type Event <: java.util.EventObject
}
trait ActionListener extends Listener{
type Event = java.awt.ActiveEvent
}
第二十一章
21.1 隐士转换
1. 定义
(1)隐士转换:以implicit声明的带有单个参数的函数
(2)这个函数自动将一种类型转换成另一种类型
case class Fraction(a:Int,b:Int){
def *(second:Fraction) = Fraction(second.a*a,second.b*b)
}
object Test extends App{
implicit def int2Fraction(n:Int) = Fraction(n,1)
val result = 3*Fraction(4,5) // Int没有*(Fraction)的方法,但Fraction有*(Fraction)方法
println(result)
}
2. 利用隐士转换丰富现有类库
(1)你多想用new File(README"").read来读取一个文件,但是jdk的File并未提供这个方法。作为java,你只能向Oracle公司提交申请,但是scala却能通过一年隐士转换来丰富这个api
case class RichFile(filepath:String){
def read() = Source.fromFile(filepath).mkString("")
}
object Test extends App{
implicit def file2RichFile(from:File) = new RichFile(from.getAbsolutePath)
new File("README").read()
}
3.编译器什么时候会进行隐士转换
(1)当表达式所得值的类型,和所处位置的期待类型不一样时
(2)当访问一个不存在的成员或方法时。eg : File.read()。也就是说当调用a.fun(b)时,如果存在2个隐士转换使得:convert(a)的结果有fun方法,或者存在方法a.fun(convert(b)),则编译器会使用convert(a)隐士转换。因为编译器会把没有调用成员的对象隐士转换
4. 编译器不会进行隐士转换的情况
(1)如果在不进行隐士转换的情况下可以通过编译,则不进行隐士转换
(2)变量只能经过一次隐士转换,而不能进行形如convert1(convert2(a))这样的多次转换
(3)如果两个隐士转换都满足条件,编译器报错。即:convert1(a)b与convert2(a)b都成立
21.2 隐士参数
1. 定义
隐士参数是函数的参数列表中,带有implicit标记的形参。此时在调用该方法时,编译器会查询缺省值
case class Delimiters(left:String,right:String)
object Test extends App{
def quote(what:String)(implicit delims:Delimiters) = delims.left + what + delims.right
println(quote("impatient scala")(Delimiters("《","》"))) // 显式调用
implicit val quoteDelimiters = Delimiters("'","'") // 隐士调用
println(quote("hello world"))
}
2. 隐士转换为隐士参数传入方法
(1)隐士转换是一个隐士方法,当方法作为参数传入另一个方法,就形成了含有隐士参数的高阶方法
def smaller[T](a:T,b:T)(implicit order: T => Ordered[T]) = {
if(order(a) < b) a else b
}
println(smaller("a","b"))
(2)隐士转换作为隐士参数的简化声明
def smaller2[T](a:T,b:T)(implicit order: T=>Ordered[T]) = {
if(a<b) a else b // 隐士转换自动执行,因此不用显式调用
}
println(smaller2(2,4))
21.3 类上的隐式泛型:上下文界定
1. 定义
(1)形如T:M的泛型,表示程序的上下文中,存在一个类型为M[T]的隐式值。通常用于类的泛型限制
(2)类中的方法使用这个上下文界定的隐式值有两种方法:
(i.) 通过定义implicit隐士形参
(ii) 在函数体中使用Predef类的implicitly()方法,传入上下文界定类型还原出这个隐式值
// method 1
class Pair[T:Ordering](val first:T,val second:T){
def smaller(implicit ord:Ordering[T])=
if (ord.compare(first,second)<0) first else second
}
// method 2
class Pair1[T:Ordering](val first:T,val second:T){
def smaller =
if( implicitly[Ordering[T]].compare(first,second) < 0 ) first else second
}
object Test1 extends App{
println(new Pair1(24,35).smaller)
}
(3)用泛型定义的类,在实例化时,编译器会通过成员变量推断出泛型的类型。
21.4 类型证明
1. 定义
(1)类型证明是形如implicit ev T <:< U的一个隐士参数,其中<:<还可以是<=<,<%<.
(2)三个符号分别表示:T是否是U的子类型,T是否等于U,T是否可以通过隐士转换为U
2. 类型证明是如何实现的
(1)<:<,<=<,<%<3个符号并非是语言特性,而是定义在Predef中的三个类
(2)举例:<:<类的定义
下面的三行代码,解释了scala通过<:<类,实现类型证明的过程。
(i.) 首先:定义了一个带有泛型的抽象类<:<,这个类继承的(From=>To),实际上就是一个Function1(带有一个形参的函数)
(ii) 其次:初始化了一个singleton_<:<对象,这个对象的-From和+To泛型都是Any,而且复写了apply方法为传入一个Any类型的参数x,然后把x返回出去
(iii)最后:定义了一个隐士转换$conforms[A],它的返回值类型为 A <:< A(<:<[A,A]的中置写法)。该方法就是将<:<[Any,Any]强转为<:<[A,A](即:Function1[Any,Any]转换为Function1[A,A])。而这个泛型A到底能否让编译器推断出来,就是这个类型证明能否通过的关键
(v.)编译器推断:由于<:<类的泛型一个逆变,一个协变。eg:对于<:<[String,AnyRef],编译器就能推断出A是String(String逆变成String,AnyRef协变成String)
@implicitNotFound(msg = "Cannot prove that ${From} <:< ${To}.")
sealed abstract class <:<[-From, +To] extends (From => To) with Serializable
private[this] final val singleton_<:< = new <:<[Any,Any] { def apply(x: Any): Any = x }
implicit def $conforms[A]: A <:< A = singleton_<:<.asInstanceOf[A <:< A]
3. 使用举例
def firstLast[T,IR](it:IR)(implicit env: IR<:<Iterable[T]) = (it.head,it.last)
println(firstLast(List(1,2,3)))
21.5 @implicitNotFound注解
1. 定义
(1)@implicitNotFound注解加载类上,该类需要时隐士转换函数From->To的To类。意义在于告知编译器,再不能构建出这个To类时爆出错误信息
(2)例如:
@implicitNotFound(msg = "Cannot prove that ${From} <:< ${To}.")
sealed abstract class <:<[-From, +To] extends (From => To) with Serializable

 浙公网安备 33010602011771号
浙公网安备 33010602011771号