
使用idea编译spark2.2.0和解决运行sparkPi遇到的问题(详细)
目录:
1.使用阿里云的Maven仓库加速Spark编译过程
2.使用idea导入spark源码
3.解决几处build报错问题
4.使用idea编译spark生成部署包
5.jar包位置
6.运行源码example的sparkPi.scala遇到的问题解决
7.调试spark core源码
改动pom.xml文件的两处:(能用国内网网站镜像,就不用国外的,可以大大减少下载资源的等待时间,也可以避免很多错误)
1)修改下载maven仓库的网站
<name>Maven Repository</name>
<!--<url>https://repo1.maven.org/maven2</url>-->
<url>http://maven.aliyun.com/nexus/content/groups/public/</url>
2)maven插件也参考这个修改
<id>central</id>
<!--<url>https://repo1.maven.org/maven2</url>-->
<url>http://maven.aliyun.com/nexus/content/groups/public/</url>
3)参考:http://www.kekeyun.com/thread-3385-1-1.html?spm=a2c4e.11153940.blogcont578775.14.571f5eb5HJ8Du5
2.使用idea导入spark源码
目录在sparkCom\spark511\spark-2.2.0-ali,导入步骤如下。
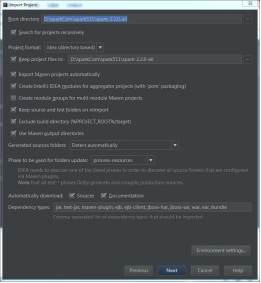
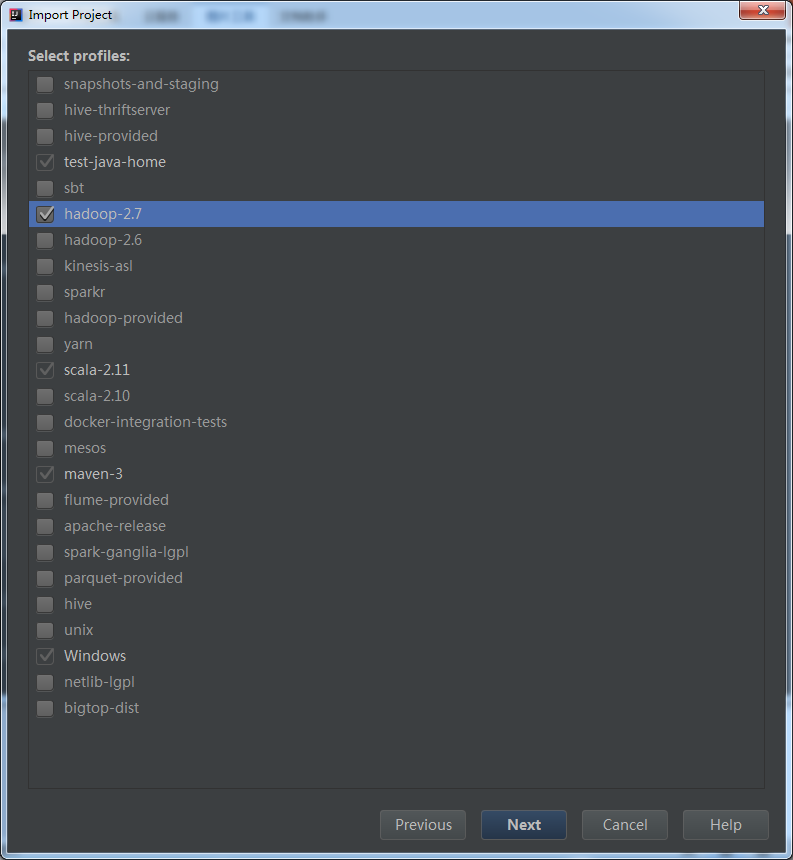
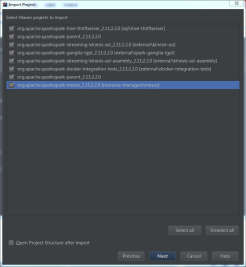
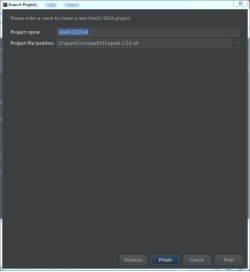
3.解决几处build报错问题
1)使用idea,2分钟导入成功。build,报错1:现在解决iml文件重复的问题,删除目录下重复的文件即可。
2)报错2:
Error:(45, 66) not found: type SparkFlumeProtocol
val transactionTimeout: Int, val backOffInterval: Int) extends SparkFlumeProtocol with Logging {
重新下载D:\spark-home\external\flume-sink\src\main\scala\org\apache\spark\streaming\flume\sink资源文件即可。(一分钟)
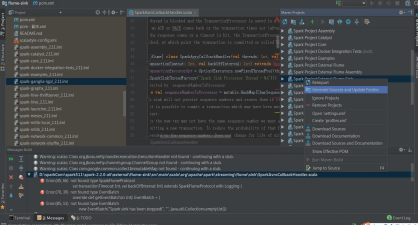
3)报错3:
Error:(36, 45) object SqlBaseParser is not a member of package org.apache.spark.sql.catalyst.parser
import org.apache.spark.sql.catalyst.parser.SqlBaseParser._
先reimport,build还报这个错,就重新下载所有资源文件。
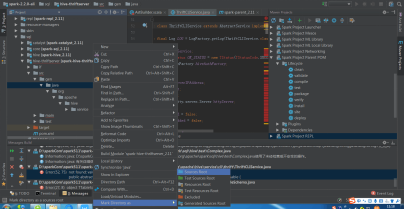
4)报错4:Error:(52, 75) not found: value TCLIService
public abstract class ThriftCLIService extends AbstractService implements TCLIService.Iface, Runnable {
解决完报错的信息,再次build,就可以成功。
此处具体可以参考:https://blog.csdn.net/He11o_Liu/article/details/78739699
4.使用idea编译spark生成部署包
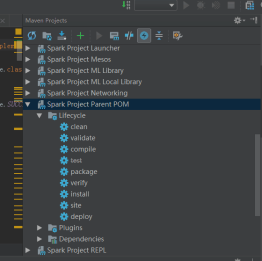
1)在maven projects视图选择Spark Project Parent POM(root),然后选中工具栏倒数第四个按钮(ship Tests mode)按下,这时Liftcycle中test是灰色的。
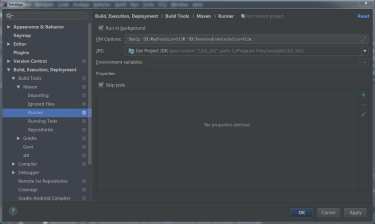
2)接着按倒数第一个按钮进入Maven设置,在runner项设置VM option:
-Xmx2g -XX:MaxPermSize=512M -XX:ReservedCodeCacheSize=512m
按OK 保存。
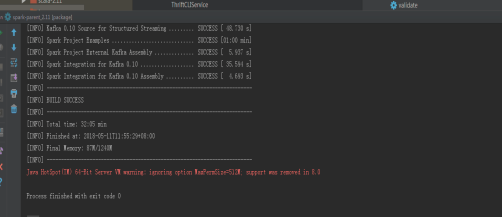
3)回到maven projects视图,点中Liftcycle中package,然后按第5个按钮(Run Maven Build按钮),开始编译。其编译结果和Maven编译是一样的。
好感动,之前好多次用idea+maven编译没有成功,编译终于成功了。
5)整个项目编译的时间较长,如果之后的开发中,只改动了某个包下的源码,就只需要重新编译对应的jar包,然后替换对应源码目录的jars包,这样就可以在自己二次开发后的源码进行调试、运行了。
参考:https://blog.csdn.net/book_mmicky/article/details/25714445
5.jar包位置
编译出来的是一个完整的包,存放在./assembly/target/scala-2.10下,这个包包含了Spark编译得到的jar包,以及编译过程中所依赖的包。
6.直接运行源码example的sparkPi.scala
解决几处error。
1)报错1:
Exception in thread "main" java.lang.NoClassDefFoundError: scala/collection/Seq
at org.apache.spark.examples.SparkPi.main(SparkPi.scala)
Caused by: java.lang.ClassNotFoundException: scala.collection.Seq
原因是:scala的jar包未导入。
解决方法:project structure->libraries->+ scala sdk
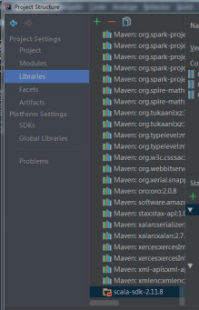
再右键点击sdk->add to modules:
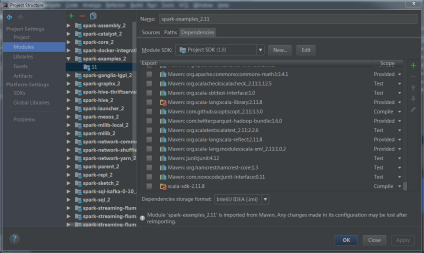
2)报错2:
Exception in thread "main" java.lang.NoClassDefFoundError: org/apache/spark/sql/SparkSession$
at org.apache.spark.examples.SparkPi$.main(SparkPi.scala:28)
at org.apache.spark.examples.SparkPi.main(SparkPi.scala)
Caused by: java.lang.ClassNotFoundException: org.apache.spark.sql.SparkSession$
原因是:spark 的jar包未引入。
解决:project structure->libraries->+java->刚才编译好的jar包位置
3)报错3:
ERROR SparkContext: Error initializing SparkContext.
org.apache.spark.SparkException: A master URL must be set in your configuration
at org.apache.spark.SparkContext.<init>(SparkContext.scala:376)
解决办法:设置本地运行模式。在edit configuratios下设置
VM option:-Dspark.master=local
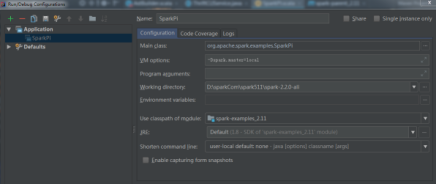
4)解决完之前的错误,可以运行sparkPi,控制台输出计算的π值。
7.调试spark core源码
这个部分可以参考:通过打印调用堆栈进行spark源码跟读
posted on 2018-05-14 11:37 moonlight.ml 阅读(2862) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号