

机器学习:Transformer
简介
Transformer 由 Google 在 2017 提出,是基于注意力机制的模型 https://arxiv.org/pdf/1706.03762.pdf
Transformer 抛弃了 RNN 和 CNN
RNN:顺序执行,无法并行处理,每个时刻的输出,都依赖上一个时刻的输出,对长期依赖不容易处理
CNN:可以并行处理,但难以处理距离远的数据之间关联信息,需要更多操作,更多层卷积
Transformer 使用的 Self-Attention 机制,直接关联序列中的任意两个数据,相当于任意两个数据的距离变成一个常量,这样变成可以并行计算,可以利用 GPU,训练速度和计算速度快,效果好
用 Transformer 搭建的编解码器,在机器翻译中,取得了非常好的效果,比 RNN 模型好很多
也可以用于计算机视觉的处理
Self Attention (自注意力机制)
(以下图片来源于网络)

上图左边的是 RNN,a 是输入 b 是输出,需要等 a1 计算了,再计算 a2,然后再计算 a3
而右边的是 Attention,可以直接对 a1~a4 做并行计算
之所以可以并行计算,是因为它直接计算所有输入之间的关系,而不用等前面的计算完成,如下图
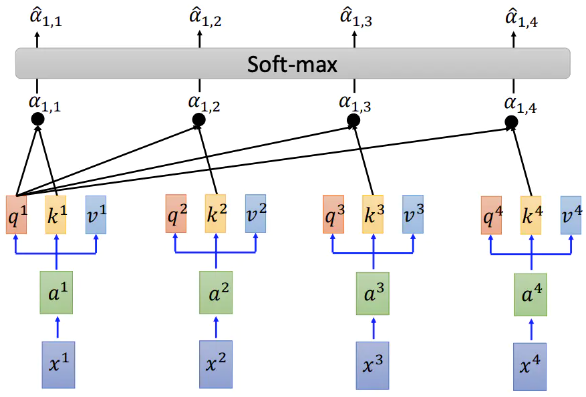
其中
x 是输入比如 10000 维的词向量,a 是转换后的向量比如 512 维向量
q 用于关联别的数据
k 用于被别的数据关联
v 代表该数据的信息
代表 i 和 j 的关联度,q 和 k 是点乘操作,d 是 q 和 k 的维度,比如 512 维就是
通过 softmax 做归一化
根据当前数据和其他数据的关联,计算对应的输出值
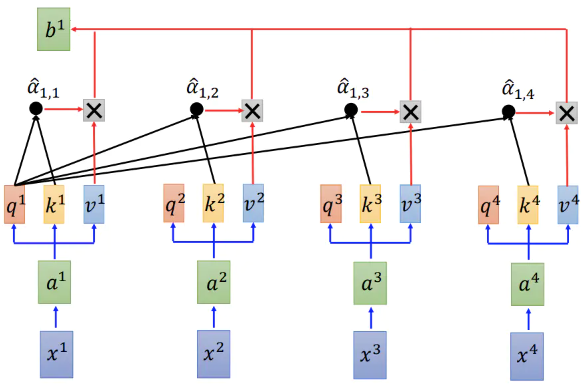
关联度和信息值相乘,累计得到结果
会计算和自己的关联度 a(i,i),既 i 的语义有多少是自己决定的,多少是其他单词决定的
可以看到,这种方式,可以并行计算,可以用矩阵,利用 GPU 计算
Multi-Head Self Attention
多个 header,就是每个 x 有多个 q,k,v
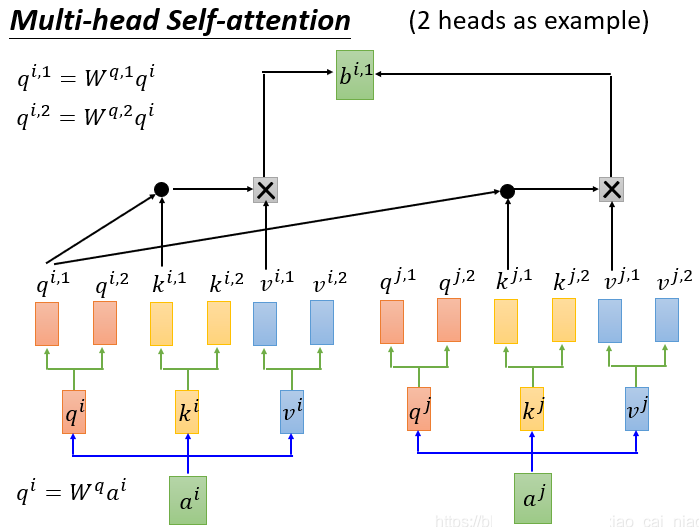
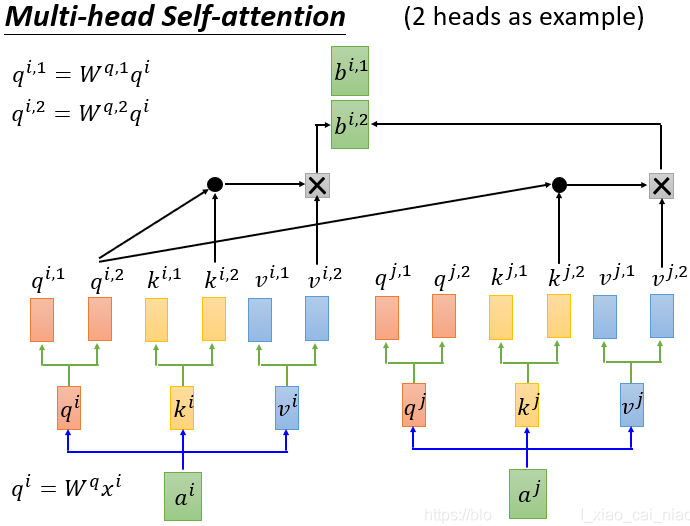
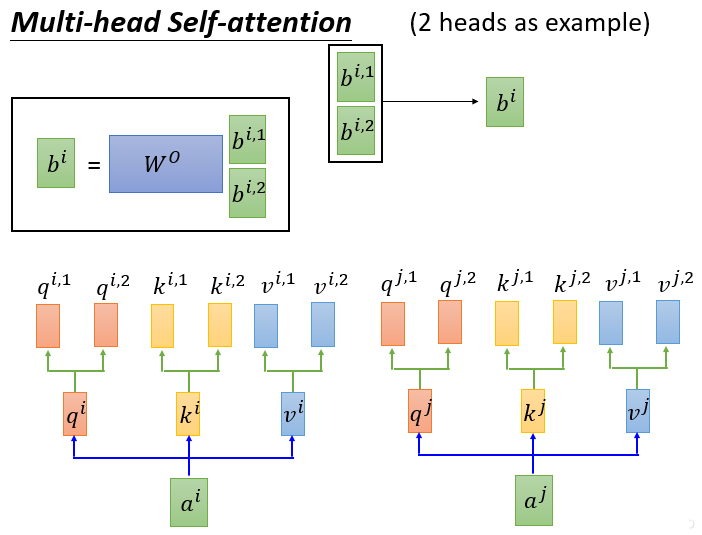
多个 Header 的作用,类似于同一个词汇,会有多个含义
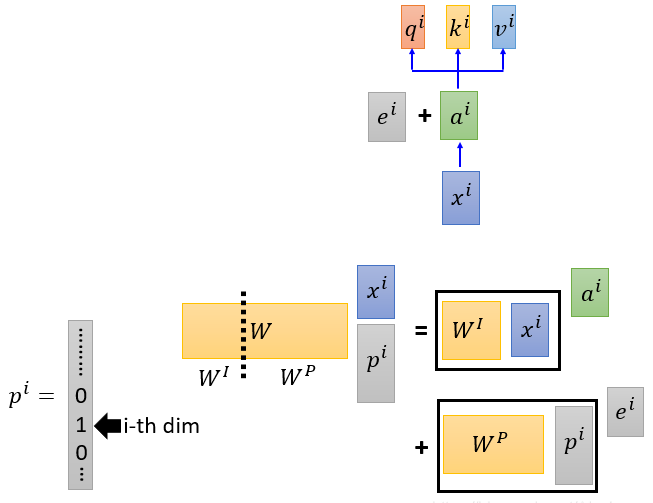
位置编码
可以看到,并行计算失去了顺序信息,会导致 x 在不同的顺序上,输出可能是一样的,这是不合理的
可以把位置信息添加到 a 的前面,或者加在 x 的前面,效果一样,对应的 w 也有位置部分的权值
Transformer
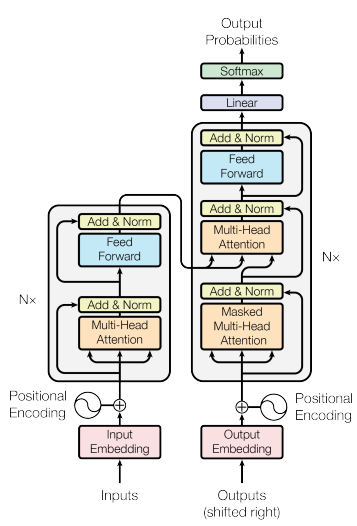
Transformer 是使用了 Self-Attention 的模型,这里以通过编解码做翻译为例子
编码器:Input 经过 embedding 转换变成 ,再加上位置编码 ,然后送到 Attention,将 Attention 的输入和输出相加并作 Norm 归一化处理,再用 Feed Forward 处理得到输出,Nx 意思是这里实际上是重复 N 次
解码器:有两部分输入,一部分是编码器的输出,另一部分是解码器的输出,同样作 Attention,Add,Norm,Feed Forward 等操作,重复 N 次然后输出
简化一下看起来就是下图这样
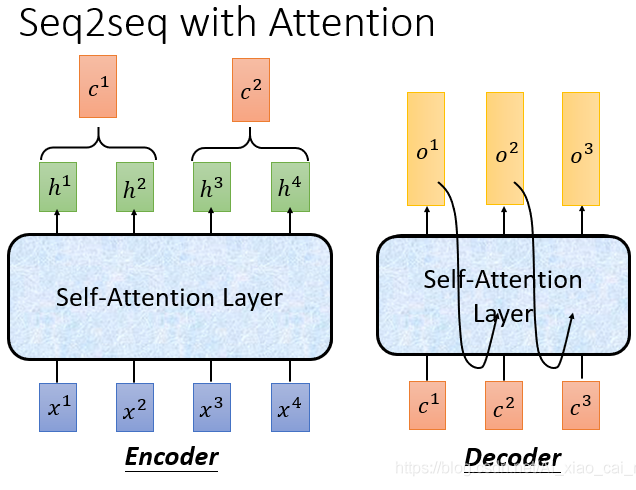
输入的长度是超参,一般自己给定的
预测的时候,比如翻译一般是把一段句子丢进去
模型能接受的最大输入大小,和支持的最大输出大小,和实际输出可能不一样,这样就需要特殊标记比如 EOL,来表示输入输出的结束,比如接受 1000 输入,1000 输出的模型,但要翻译的句子只有 100 个单词,翻译结果就 90 个单词,这样输入就是 100 + EOL,然后输出是 90 + EOL
输入可以是单词用于翻译,对于其他应用,输入也可以是其他序列化的东西,比如一序列的图片,比如图片的一块一块,比如某个基于时间序列的监控数据,等等
(比如图片某块是车轮,但单独有可能看不出来,结合其他图片块比如车门车头等,可能就容易判断这块是个车轮)
BERT
BERT 是预训练语言模型,全称 Bidirectional Encoder Representations from Transformers
下面 github 上一个用 BERT 做异常日志检测的项目
https://github.com/HelenGuohx/logbert
import math
import torch
import torch.nn as nn
import torch.nn.functional as F
class TokenEmbedding(nn.Embedding):
def __init__(self, vocab_size, embed_size=512):
super().__init__(vocab_size, embed_size, padding_idx=0)
class SegmentEmbedding(nn.Embedding):
def __init__(self, embed_size=512):
super().__init__(3, embed_size, padding_idx=0)
class TimeEmbedding(nn.Module):
def __init__(self, embed_size=512):
super().__init__()
self.time_embed = nn.Linear(1, embed_size)
def forward(self, time_interval):
return self.time_embed(time_interval)
class PositionalEmbedding(nn.Module):
def __init__(self, d_model, max_len=512):
super().__init__()
# Compute the positional encodings once in log space.
pe = torch.zeros(max_len, d_model).float()
pe.require_grad = False
position = torch.arange(0, max_len).float().unsqueeze(1)
div_term = (torch.arange(0, d_model, 2).float() * -(math.log(10000.0) / d_model)).exp()
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0)
self.register_buffer('pe', pe)
def forward(self, x):
return self.pe[:, :x.size(1)]
class BERTEmbedding(nn.Module):
"""
BERT Embedding which is consisted with under features
1. TokenEmbedding : normal embedding matrix
2. PositionalEmbedding : adding positional information using sin, cos
2. SegmentEmbedding : adding sentence segment info, (sent_A:1, sent_B:2)
sum of all these features are output of BERTEmbedding
"""
def __init__(self, vocab_size, embed_size, max_len, dropout=0.1, is_logkey=True, is_time=False):
"""
:param vocab_size: total vocab size
:param embed_size: embedding size of token embedding
:param dropout: dropout rate
"""
super().__init__()
self.token = TokenEmbedding(vocab_size=vocab_size, embed_size=embed_size)
self.position = PositionalEmbedding(d_model=self.token.embedding_dim, max_len=max_len)
self.segment = SegmentEmbedding(embed_size=self.token.embedding_dim)
self.time_embed = TimeEmbedding(embed_size=self.token.embedding_dim)
self.dropout = nn.Dropout(p=dropout)
self.embed_size = embed_size
self.is_logkey = is_logkey
self.is_time = is_time
def forward(self, sequence, segment_label=None, time_info=None):
x = self.position(sequence)
# if self.is_logkey:
x = x + self.token(sequence)
if segment_label is not None:
x = x + self.segment(segment_label)
if self.is_time:
x = x + self.time_embed(time_info)
return self.dropout(x)
class Attention(nn.Module):
"""
Compute 'Scaled Dot Product Attention
"""
def forward(self, query, key, value, mask=None, dropout=None):
scores = torch.matmul(query, key.transpose(-2, -1)) \
/ math.sqrt(query.size(-1))
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)
p_attn = F.softmax(scores, dim=-1)
if dropout is not None:
p_attn = dropout(p_attn)
return torch.matmul(p_attn, value), p_attn
class MultiHeadedAttention(nn.Module):
"""
Take in model size and number of heads.
"""
def __init__(self, h, d_model, dropout=0.1):
super().__init__()
assert d_model % h == 0
# We assume d_v always equals d_k
self.d_k = d_model // h
self.h = h
self.linear_layers = nn.ModuleList([nn.Linear(d_model, d_model) for _ in range(3)])
self.output_linear = nn.Linear(d_model, d_model)
self.attention = Attention()
self.dropout = nn.Dropout(p=dropout)
def forward(self, query, key, value, mask=None):
batch_size = query.size(0)
# 1) Do all the linear projections in batch from d_model => h x d_k
query, key, value = [l(x).view(batch_size, -1, self.h, self.d_k).transpose(1, 2)
for l, x in zip(self.linear_layers, (query, key, value))]
# 2) Apply attention on all the projected vectors in batch.
x, attn = self.attention(query, key, value, mask=mask, dropout=self.dropout)
# 3) "Concat" using a view and apply a final linear.
x = x.transpose(1, 2).contiguous().view(batch_size, -1, self.h * self.d_k)
return self.output_linear(x)
class GELU(nn.Module):
"""
Paper Section 3.4, last paragraph notice that BERT used the GELU instead of RELU
"""
def forward(self, x):
return 0.5 * x * (1 + torch.tanh(math.sqrt(2 / math.pi) * (x + 0.044715 * torch.pow(x, 3))))
class PositionwiseFeedForward(nn.Module):
"Implements FFN equation."
def __init__(self, d_model, d_ff, dropout=0.1):
super(PositionwiseFeedForward, self).__init__()
self.w_1 = nn.Linear(d_model, d_ff)
self.w_2 = nn.Linear(d_ff, d_model)
self.dropout = nn.Dropout(dropout)
self.activation = GELU()
def forward(self, x):
return self.w_2(self.dropout(self.activation(self.w_1(x))))
class LayerNorm(nn.Module):
"Construct a layernorm module (See citation for details)."
def __init__(self, features, eps=1e-6):
super(LayerNorm, self).__init__()
self.a_2 = nn.Parameter(torch.ones(features))
self.b_2 = nn.Parameter(torch.zeros(features))
self.eps = eps
def forward(self, x):
mean = x.mean(-1, keepdim=True)
std = x.std(-1, keepdim=True)
return self.a_2 * (x - mean) / (std + self.eps) + self.b_2
class SublayerConnection(nn.Module):
"""
A residual connection followed by a layer norm.
Note for code simplicity the norm is first as opposed to last.
"""
def __init__(self, size, dropout):
super(SublayerConnection, self).__init__()
self.norm = LayerNorm(size)
self.dropout = nn.Dropout(dropout)
def forward(self, x, sublayer):
"Apply residual connection to any sublayer with the same size."
return x + self.dropout(sublayer(self.norm(x)))
class TransformerBlock(nn.Module):
"""
Bidirectional Encoder = Transformer (self-attention)
Transformer = MultiHead_Attention + Feed_Forward with sublayer connection
"""
def __init__(self, hidden, attn_heads, feed_forward_hidden, dropout):
"""
:param hidden: hidden size of transformer
:param attn_heads: head sizes of multi-head attention
:param feed_forward_hidden: feed_forward_hidden, usually 4*hidden_size
:param dropout: dropout rate
"""
super().__init__()
self.attention = MultiHeadedAttention(h=attn_heads, d_model=hidden)
self.feed_forward = PositionwiseFeedForward(d_model=hidden, d_ff=feed_forward_hidden, dropout=dropout)
self.input_sublayer = SublayerConnection(size=hidden, dropout=dropout)
self.output_sublayer = SublayerConnection(size=hidden, dropout=dropout)
self.dropout = nn.Dropout(p=dropout)
def forward(self, x, mask):
x = self.input_sublayer(x, lambda _x: self.attention.forward(_x, _x, _x, mask=mask))
x = self.output_sublayer(x, self.feed_forward)
return self.dropout(x)
class BERT(nn.Module):
"""
BERT model : Bidirectional Encoder Representations from Transformers.
"""
def __init__(self, vocab_size, max_len=512, hidden=768, n_layers=12, attn_heads=12, dropout=0.1,
is_logkey=True, is_time=False):
"""
:param vocab_size: vocab_size of total words
:param hidden: BERT model hidden size
:param n_layers: numbers of Transformer blocks(layers)
:param attn_heads: number of attention heads
:param dropout: dropout rate
"""
super().__init__()
self.hidden = hidden
self.n_layers = n_layers
self.attn_heads = attn_heads
# paper noted they used 4*hidden_size for ff_network_hidden_size
self.feed_forward_hidden = hidden * 2
# embedding for BERT, sum of positional, segment, token embeddings
self.embedding = BERTEmbedding(vocab_size=vocab_size, embed_size=hidden, max_len=max_len,
is_logkey=is_logkey, is_time=is_time)
# multi-layers transformer blocks, deep network
self.transformer_blocks = nn.ModuleList(
[TransformerBlock(hidden, attn_heads, hidden * 2, dropout) for _ in range(n_layers)])
def forward(self, x, segment_info=None, time_info=None):
# attention masking for padded token
# torch.ByteTensor([batch_size, 1, seq_len, seq_len)
mask = (x > 0).unsqueeze(1).repeat(1, x.size(1), 1).unsqueeze(1)
# embedding the indexed sequence to sequence of vectors
x = self.embedding(x, segment_info, time_info)
# running over multiple transformer blocks
for transformer in self.transformer_blocks:
x = transformer.forward(x, mask)
return


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 提示词工程——AI应用必不可少的技术
· 地球OL攻略 —— 某应届生求职总结
· 字符编码:从基础到乱码解决
· SpringCloud带你走进微服务的世界