机器学习:GAN 生成对抗网络
概述
机器学习算法多数是用于解决回归问题,分类问题,聚类问题,而 GAN 则是用于生成内容,比如生成图片
GAN(Generative Adversarial Nets,生成对抗网络)是 2014 年提出的理论 https://arxiv.org/pdf/1406.2661.pdf
GAN 由一个生成器 Generator 和一个判别器 Discriminator 组成,下面以生成图片为例子
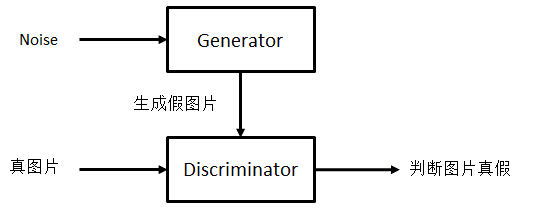
Generator 接收随机的噪声 x,生成图片,y = G(x)
Discriminator 接收图片,判断图片是真的还是生成的,z = D(y),样本 y 部分来自真实图片,部分由 G 生成
我们希望训练 G 使得它能生成尽可能真的图片,使得 D 无法区分真假
同时又训练 D 使得它能尽可能地区别真实图片和生成图片
可以看到 G 和 D 目标相反,互相对抗,所以叫生成对抗网络,在对抗训练中,G 和 D 的能力不断提升
理想情况下,最后 G 生成的图片,D 难以区分真假,即 D(G(x)) = 0.5
训练
轮流训练 G 和 D,可以先训练 G 再训练 D,也可以训练 D 再训练 G
以先训练 D 再训练 G 为例子
训练 D
固定 G 的参数不改变
取一批真实图片 xr,通过 G 生成一批假图片 xf = G(noise)
用 D 判定,yr = D(xr),yf = D(xf)
计算损失函数 Loss(yr, ones) (真图希望输出 1)、Loss(yf, zeros) (假图希望输出 0)
应用反向梯度传播算法,更新 D 的参数(G 不参与梯度传播,或者传播但不改变 G 的参数)
训练 G
固定 D 的参数不改变
通过 G 生成一批假图片 xf = G(noise)
用 D 判定,yf = D(xf)
计算损失函数 Loss(yf, ones) (希望假图能骗过 D 使其输出 1)
应用反向梯度传播算法,更新 G 的参数(D 参与梯度传播,但不改变 D 的参数)
训练 G 的迭代次数和训练 D 的迭代次数可以不一样,比如先用 5 个 batch 训练 D,再用 1 个 batch 训练 G,循环反复
DCGAN
https://arxiv.org/abs/1511.06434
最开始的 GAN,没有用 CNN 网络,训练不稳定,G 容易生成糟糕的结果
DCGAN(Deep Convolutional GAN)原理和 GAN 一样,但使用 CNN 构建 G 和 D
DCGAN 的 CNN 的特点
G 网络使用转置卷积(Transposed Convolutional Layer)做上采样
D 网络通过设置 stride 代替 Pooling 层
使用 Batch Normalization
G 网络使用 ReLU 激活函数,最后一层用 tanh 激活函数,不用全连接层,最后的卷积就是输出
D 网络使用 LeakyReLU 激活函数,最后一层用 sigmoid 激活函数,不用全连接层,最后的卷积就是输出
转置卷积
和正常的卷积反过来,也叫逆卷积或反卷积
就是将小的特征图,变换成大的特征图,将特征图变成图片,例如下图

G 模型用的就是转置卷积网络,可以看到接收 100 channel 的 noise 最终输出 96 x 96 的 RGB 图片
关于转置卷积如何计算,可以参考 https://zhuanlan.zhihu.com/p/327784795
里面介绍了,插值补零法、交错相加法、小卷积核法,等几种方法
要注意转置卷积是卷积的逆运算,不是卷积的逆过程
代码
参考 https://blog.csdn.net/weixin_45807161/article/details/123776427
import matplotlib.pyplot as plt
import torch
import torch.nn as nn
import torchvision
import tqdm
from torch.autograd import Variable
from torch.utils.data import DataLoader
"""
# 简单测试,理解反卷积
m = nn.ConvTranspose2d(3, 6, kernel_size=3, stride=1, padding=0, bias=False)
input = torch.ones(3, 3, 4)
print(input.shape) # torch.Size([3, 3, 4])
output = m(input)
print(output.shape) # torch.Size([6, 5, 6])
noises = Variable(torch.randn(50, 100, 1, 1))
print(noises.shape) # torch.Size([50, 100, 1, 1])
noises.data.copy_(torch.randn(50, 100, 1, 1))
print(noises.shape) # torch.Size([50, 100, 1, 1])
"""
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
self.model = nn.Sequential(
# 设置输入 channel 和输出 channel,以及 kernel size 和步长等
# 不会限制长和宽,由输入决定
# 后面我们用 1x1,这样输出就是 4x4
# (由输入大小, kernel 大小, stride, padding 决定)
# (out 大小通过卷积可以得到 in 的大小,由此可以通过 in 大小反推反卷积后的 out 大小)
# 结合 channel 就是 100 个 1x1 的输入,产生 512 个 4x4 的输出
# kernel_size, stride, padding 接收两个值(长和宽)组成的 tuple, 如果用 int, 就默认两个值是一样的
nn.ConvTranspose2d(in_channels=100, out_channels=512, kernel_size=4,
stride=1, padding=0, bias=False),
nn.BatchNorm2d(512),
nn.ReLU(True),
# 输入 512x4x4,输出 256x8x8 (stride = 2, padding = 1)
nn.ConvTranspose2d(in_channels=512, out_channels=256, kernel_size=4,
stride=2, padding=1, bias=False),
nn.BatchNorm2d(256),
nn.ReLU(True),
# 输入 256x8x8,输出 128x16x16
nn.ConvTranspose2d(in_channels=256, out_channels=128, kernel_size=4,
stride=2, padding=1, bias=False),
nn.BatchNorm2d(128),
nn.ReLU(True),
# 输入 128x16x16,输出 64x32x32
nn.ConvTranspose2d(in_channels=128, out_channels=64, kernel_size=4,
stride=2, padding=1, bias=False),
nn.BatchNorm2d(64),
nn.ReLU(True),
# 输入 64x32x32,输出 3x96x96
nn.ConvTranspose2d(in_channels=64, out_channels=3, kernel_size=5,
stride=3, padding=1, bias=False),
nn.Tanh()
)
def forward(self, x):
"""
nn.Module 定义了 __call__ 函数
__call__ : Callable[..., Any] = _call_impl
而这个 _call_impl 函数里面调用了 self.forward
由于定义了 __call__ 方法的类可以当作函数调用
所以下面代码就会调用到 forward
generator = Generator()
y = generator(torch.randn(10, 100, 1, 1))
# torch.randn(10, 100, 1, 1) 随机生成 10x100x1x1 的数据
# 因为模型是接收批数据的,所以需要指定 4 个值,代表 batch size 为 10,channel 为 100,长宽为 1
print(y.shape) # 输出 torch.Size([10, 3, 96, 96])
print(y.view(-1).shape) # 输出 torch.Size([276480])
# view 相当于 reshape,而 -1 代表由电脑自己计算
print(y.view(-1, 96, 96).shape) # 输出 torch.Size([30, 96, 96])
"""
return self.model(x)
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.model = nn.Sequential(
# 如果输入 3x96x96 的图片,输出是 64x32x32 的特征图
nn.Conv2d(in_channels=3, out_channels=64, kernel_size=5, stride=3, padding=1, bias=False),
nn.LeakyReLU(0.2, inplace=True),
# 输入 64x32x32,输出 128x16x16
nn.Conv2d(in_channels=64, out_channels=128, kernel_size=4, stride=2, padding=1, bias=False),
nn.BatchNorm2d(128),
nn.LeakyReLU(0.2, inplace=True),
# 输入 128x16x16,输出 256x8x8
nn.Conv2d(in_channels=128, out_channels=256, kernel_size=4, stride=2, padding=1, bias=False),
nn.BatchNorm2d(256),
nn.LeakyReLU(0.2, inplace=True),
# 输入 256x8x8,输出 512x4x4
nn.Conv2d(in_channels=256, out_channels=512, kernel_size=4, stride=2, padding=1, bias=False),
nn.BatchNorm2d(512),
nn.LeakyReLU(0.2, inplace=True),
# 输入 512x4x4,输出一个概率
nn.Conv2d(in_channels=512, out_channels=1, kernel_size=4, stride=1, padding=0, bias=False),
nn.Sigmoid()
)
def forward(self, x):
"""
d = Discriminator()
y = d(torch.randn(10, 3, 96, 96)) # 随机产生 10 个 channel 为 3,长宽为 96 的数据
# 如果不用 view(-1) 的话,输出会是 torch.Size([10, 1, 1, 1])
# 用了 view(-1) 后,输出是 torch.Size([10])
print(y.shape)
"""
return self.model(x).view(-1)
def train():
#########
# 批大小
#########
batch_size = 50
##########
# 导入数据
##########
# 定义如何转换图片
transform = torchvision.transforms.Compose(
[
torchvision.transforms.Resize(96),
torchvision.transforms.CenterCrop(96),
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
]
)
# 用 transformer 创建数据集,图片要放在 images 下的子目录,比如 images/anime-faces/*.png,有 20000 多张图片
dataset = torchvision.datasets.ImageFolder('./images', transform=transform)
# 用 dataset 创建 dataloader, 用于迭代,每次导入一批图片,批大小为 batch_size
dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True, num_workers=4, drop_last=True)
#######################
# 判定器和生成器相关设置
#######################
generator = Generator()
discriminator = Discriminator()
# 优化器,也用于更新参数
optimizer_g = torch.optim.Adam(generator.parameters(), lr=2e-4, betas=(0.5, 0.999))
optimizer_d = torch.optim.Adam(discriminator.parameters(), lr=2e-4, betas=(0.5, 0.999))
# 损失函数
loss = torch.nn.BCELoss()
# 标签,值为 1 的标签,和值为 0 的标签,大小为 batch_size
true_labels = Variable(torch.ones(batch_size))
fake_labels = Variable(torch.zeros(batch_size))
# 噪音,大小为 batch_size,channel 为 100
# fix_noises 不会变化,用于阶段性的测试效果,用于比较不同迭代次数后,同一个噪音输入所产生的图片质量
# noises 会改变,用于训练,每导入一批真实图片,就用新的噪音,产生新的假图片,每批真假图片的数量都是 batch_size
fix_noises = Variable(torch.randn(batch_size, 100, 1, 1))
noises = Variable(torch.randn((batch_size, 100, 1, 1)))
# CUDA 是否可用,如果可以则使用 CUDA,也就是用 GPU 计算
# CUDA(Compute Unified Device Architecture),是显卡厂商 NVIDIA 推出的运算平台
if torch.cuda.is_available():
print("cuda is available")
generator.cuda()
discriminator.cuda()
loss.cuda()
true_labels = true_labels.cuda()
fake_labels = fake_labels.cuda()
fix_noises = fix_noises.cuda()
noises = noises.cuda()
#######
# 迭代
#######
# i 代表第几次迭代
# 处理完所有的图片就是一次迭代
for i in range(300):
print("迭代 " + str(i))
###########
# 分批处理
###########
# j 代表第几批
# 前面创建 dataloader 的时候已经指定了每批拿多少张图片
# 由于用的真实图片有 20000 多张,如果 batch_size 设置为 50 的话,每次迭代就是分 400 多个批次处理
# image 不是一张图片,而是一批图片
for j, (image, _) in tqdm.tqdm(enumerate(dataloader)):
#####################
# 训练 discriminator
#####################
# 获取一批真实图片
real_image = Variable(image)
if torch.cuda.is_available():
real_image = real_image.cuda()
# 清零梯度,避免被前面的迭代批次影响
optimizer_d.zero_grad()
# 对真图片做判定,目标是 1
real_output = discriminator(real_image)
# 计算损失,目标是 1
d_loss_real = loss(real_output, true_labels)
# 产生一批噪音
noises.data.copy_(torch.randn(batch_size, 100, 1, 1))
# 生成假图片
# detach() 使得梯度不会传到 generator,因为训练 discriminator 时需要固定 generator 不变
fake_image = generator(noises).detach()
# 对假图片做判定,目标是 0
fake_output = discriminator(fake_image)
# 计算损失,目标是 0
d_loss_fake = loss(fake_output, fake_labels)
# 合成一个 loss
d_loss = (d_loss_real + d_loss_fake) / 2
# 反向梯度传播 (也可以两个 loss 分别做 backward() 然后 step() 更新)
d_loss.backward()
# 更新 discriminator 参数
optimizer_d.step()
#################
# 训练 generator
#################
# 每 5 个 batch 才训练一次 generator (而 discriminator 是每个 batch 都训练)
# g 模型和 d 模型的训练次数比例可以自己调,没要求一定这样,也没要求必须先训练 discriminator
if (j + 1) % 5 == 0:
# 清零梯度,避免被前面的迭代批次影响
optimizer_g.zero_grad()
# 产生噪音
noises.data.copy_(torch.randn(batch_size, 100, 1, 1))
# 生成假图片
fake_image = generator(noises)
# 对假图片做判断,目标是 1 (希望能欺骗 discriminator)
fake_output = discriminator(fake_image)
# 计算损失,目标是 1
g_loss = loss(fake_output, true_labels)
# 反向梯度传播
g_loss.backward()
# 更新 generator 参数
optimizer_g.step()
##############
# 观察训练效果
##############
if i in [1, 5, 10, 50, 100, 200]:
# 用一个在训练过程中保持固定不变的噪音,阶段性的产生图片,用于观察训练的效果
fix_fake_images = generator(fix_noises)
fix_fake_images = fix_fake_images.data.cpu()[:64] * 0.5 + 0.5
fig = plt.figure(1)
# 将生成的所有小图片放到一张大图中
k = 1
for fix_fake_image in fix_fake_images:
# 这个大图有 8 行 8 列,要添加的小图放到第 k 个位置(从左上角开始算)
fig.add_subplot(8, 8, eval('%d' % k))
plt.axis('off')
plt.imshow(fix_fake_image.permute(1, 2, 0))
k += 1
# 调整位置
plt.subplots_adjust(left=None, right=None, bottom=None, top=None, wspace=0.05, hspace=0.05)
# 设置标题
plt.suptitle('第%d次迭代结果' % i, y=0.91, fontsize=15)
# 保存图片
plt.savefig("./fake_image/%d-dcgan.png" % i)
if __name__ == '__main__':
train()
阶段性的生成效果保存在 ./fake_image
下面是第 1,5,10,50,100 次迭代的效果





可以看到,同一个输入噪音,生成的效果越来越好
关于 detect() 的作用,和不用 detect() 的做法,可以参考
https://zhuanlan.zhihu.com/p/525543542

 浙公网安备 33010602011771号
浙公网安备 33010602011771号