机器学习:循环神经网络
传统的机器学习算法非常依赖人工提取特征,使得图像识别、语音识别、自然语音处理等问题存在特征提取的瓶颈
基于全连接神经网络的方法存在参数太多、无法利用时间序列信息等问题
卷积神经网络(CNN)解决图像的特征提取问题、参数太多问题
循环神经网络(RNN)解决利用时间序列信息的问题
RNN 主要用于语音识别、语言模型、机器翻译、判断语句的意思、判断视频的场景、时序分析、等等
这些应用比如翻译都需要考虑上下文关系,也就是说受时序的影响,和语言无关的时序问题也可以用 RNN
网络结构
下图是最简单的 RNN 模型,一个输入层 X,一个隐藏层 S,一个输出层 O
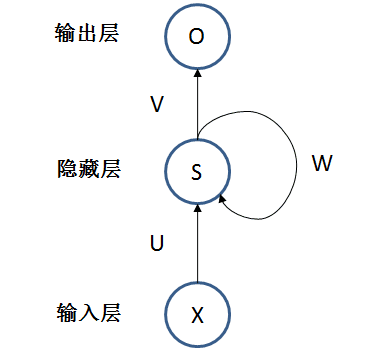
X 接受当前时刻的输入
S 相当于某个时刻的状态,由上一个时刻的 S 和当前时刻的 X 决定
O 是当前时刻的输出
如果将其按时序展开,逻辑上看起来是这样
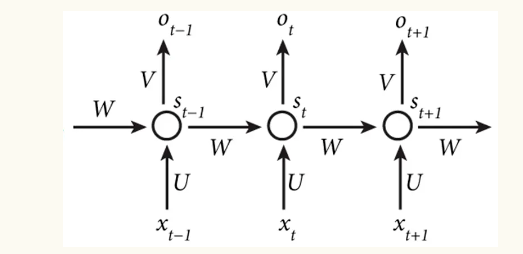
(注意这个横向的展开是逻辑上的,实际上就只有一个 X/S/O,多个也没啥用,因为无法并行计算)
X(t):是 t 时刻的输入,例如单词向量
S(t):是 t 时刻的状态,由上一个时刻的状态和当前输入得到
\(\large S(t) = f( X(t) \times U + S(t-1) \times W + b\_state)\)
其中 \(\small f\) 是非线性激活函数(一般是 \(\small tanh\)),设 \(\small S(-1)\) 为 0
正切函数 Tanh
\(\large f(x) = tanh(x) = \frac{1-e^{-2x}}{1+e^{-2x}}\)
\(\large f^{'}(x) = \frac{4e^{-2x}}{(1+e^{-2x})^{2}} = 1 - f(x)^{2}\)
\(\small S(t)\) 的算法公式
网上有的不是 \(\large X(t) \times U + S(t-1) \times W\)
而是 \(\large (X(t), S(t-1)) \times W\)
这里其实是把 X 和 S 拼成一个矩阵,再把 U 和 W 拼成一个新的 W 矩阵
一个 (1, n) 矩阵和一个 (1, m) 矩阵拼起来就是 (1, n+m) 矩阵
其实只是写法不同,本质上是一样的,即
\(\large X(t) \times U + S(t-1) \times W = (X(t), S(t-1)) \times (U, W)\)
O(t):是 t 时刻的输出
\(\large O(t) = softmax( S(t) \times V + b\_output )\)
Softmax
\(\large f(x) = \frac{e^{x_{i}}}{\sum_{j=1}^{n}e^{x_{j}}}\)
用于多分类,每个节点的输出代表样本属于该分类的概率
可以看到对于一个样本,输出层所有节点的输出的和等于 1
\(\large f^{'}(x) = (e^{x_{i}})^{'}(\sum_{j=1}^{n}e^{x_{j}})^{-1} + (e^{x_{i}})((\sum_{j=1}^{n}e^{x_{j}})^{-1})^{'} = f(x)(1-f(x))\)
预测词汇、翻译之类的,输出类似分类,所以一般用 Softmax
如果是回归类的时序分析,就用其他激活函数
每个时刻都使用相同的 U、V、W 参数,反应出 RNN 中每步都在做相同的事,大大减少了参数
假设输入 X 的维度是 (1, n),状态 S 的维度是 (1, h),输出的维度是 (1,m),则
U 的维度是 (n, h)
W 的维度是 (h, h)
b_state 的维度是 (1, h)
V 的维度是 (h, m)
b_output 的维度是 (1, m)
共需要参数为 (n x h) + (h x h) + h + (h x m) + m = (n+h+m+1) x h + m
假设 X 维度 4,S 维度 3,O 维度 2,把神经元也画出来,那么模型看起来就是
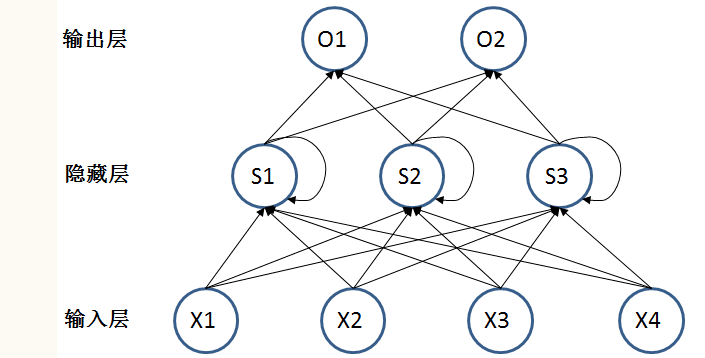
O 本质上是个全连接层,可以有多层 (一般 2,3层),比如一个激活函数为 ReLU 的层,加一个 Softmax 层
S 也可以有多层
RNN 要求每个时刻都有输入,但不是每个时刻都要有输出(比如接收完整的一句话才会有输出)
RNN 的输入可以有重叠,比如 (a, b, c) 一个序列,后面跟着 (b, c, d) 序列
RNN 的输入数据序列可以很长,可以几百几千个,比如判断一个几百个字的文章段落在表达什么情绪
RNN 的输入输出可以有多种情况
1. 一个输入比如一张图像,输出是单词序列
2. 输入序列比如一个句子,输出一个值,比如判断句子的分类或预测下一个单词
3. 输入输出都是序列,比如翻译
训练算法
参数训练通过随时间进行反向传播(Backpropagation Through Time,BPTT)算法
基本原理和 BP 算法一样,也包含三个步骤:
1. 前向计算每个神经元的输出值
2. 反向计算每个神经元的误差项值,它是误差函数对神经元的加权输入的偏导数
3. 计算每个权重的梯度,最后再用随机梯度下降算法更新权重
LSTM(Long Short Term Memory,长短时记忆)
传统 RNN 在实际中很难处理长期依赖问题,比如 "I grew up in France ...... I speak fluent ()" 要预测 () 中该填哪个词,跟很久之前的 "France" 有密切关系
另一方面,简单的 RNN 可能出现梯度衰减或爆炸
LSTM 就是为了解决这两个问题,RNN 被成功应用的关键就是 LSTM,很多任务采用 LSTM 比标准的 RNN 表现要好
LSTM 网络结构如下
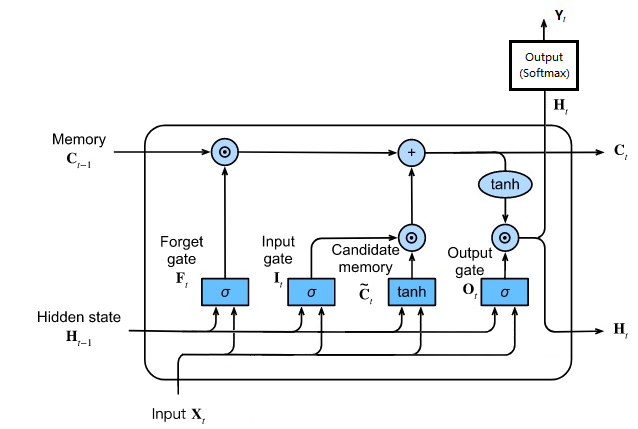
其中 \(\large \sigma\) 是 sigmoid 函数,值在 0~1 之间,代表了对输入值的取舍,起门的作用
而 \(\odot\) 符号代表矩阵对应元素直接相乘,又叫 Hadamard Product(哈达玛乘积)
(m,n) \(\odot\) (m,n),结果还是 (m,n) 矩阵,两个矩阵对应位置的值直接相乘
LSTM 有两个内部变量,C 和 H
C 是 Cell Memory,代表当前拥有的记忆,通常改变得比较慢
H 是 Hidden State,代表当前的隐藏状态,有可能变化比较大
LSTM 拥有三个门结构,分别是遗忘门、输入门、输出门
遗忘门根据隐藏状态 H 和当前输入 X 决定如何让 C 忘记之前没有用的记忆
比如有文章写了某地碧水蓝天,但后来被污染了,于是 C 应该忘记之前碧水蓝天的状态
忘记部分历史信息后,应该依据隐藏状态 H 和当前输入 X 补充新信息,这就是输入门
比如把环境被污染这个信息写进去
经过遗忘门和输入门后产生了新的记忆 C
输出门根据新的记忆 C 和当前输入 X 决定新的隐藏状态 H
根据新的隐藏状态 H 产生当前时刻的输入 Y
比如当前状态为污染,那么天空的颜色可能就是灰色的
公式如下
\(\large F_{t} = \sigma(X_{t}W_{xf} + H_{t-1}W_{hf} + b_{f})\)
\(\large I_{t} = \sigma(X_{t}W_{xi} + H_{t-1}W_{hi} + b_{i})\)
\(\large O_{t} = \sigma(X_{t}W_{xo} + H_{t-1}W_{ho} + b_{o})\)
\(\large \widetilde{C}_{t} = tanh(X_{t}W_{xc} + H_{t-1} W_{hc} + b_{c})\)
\(\large C_{t} = F_{t} \odot C_{t-1} + I_{t} \odot \widetilde{C}_{t}\)
\(\large H_{t} = O_{t} \odot tanh(C_{t})\)
\(\large Y_{t} = softmax( H_{t} \times W_{hy} + b_{y} )\) (通常应该先过一层普通的全连接层,再接 Softmax)
LSTM 有效解决了长期记忆问题和梯度问题
LSTM 有一些其他变体,这里就不展开了
GRU (Gated Recurrent Unit,门控循环单元)
GRU 是在 2014 年提出来的,而 LSTM 是 1997 年
GRU 门控循环神经网络和 LSTM 同样,也是为了解决长期记忆和反向传播中的梯度衰减或爆炸等问题而提出
GRU 的效果和 LSTM 类似,但更易于计算
GRU 网络结构如下
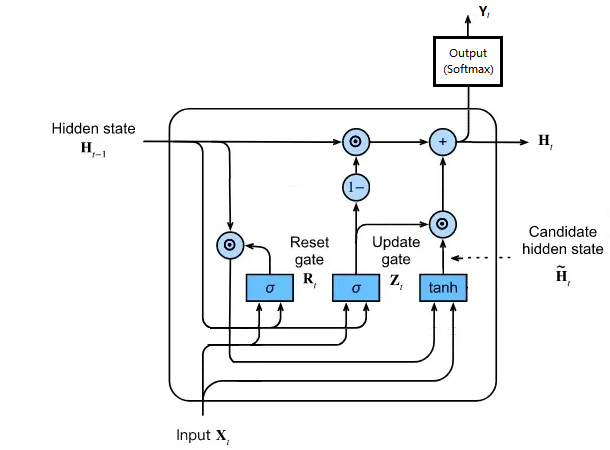
其中 \(\small \sigma\) 是 sigmoid 函数,值在 0~1 之间,代表了对输入值的取舍,起门的作用
而 \(\odot\) 符号代表矩阵对应元素直接相乘,又叫 Hadamard Product(哈达玛乘积)
(m,n) \(\odot\) (m,n),结果还是 (m,n) 矩阵,两个矩阵对应位置的值直接相乘
重置门,依据 \(\small H_{t-1}\) 和 \(\small X_{t}\) 决定 \(\small H_{t-1}\) 有多少信息保留下来
tanh 计算,由输入的 \(\small X_{t}\) 和经过重置门后的 \(\small H_{t-1}\) 保留信息产生候选 \(\small \widetilde{H}_{t}\)
更新门,依据 \(\small H_{t-1}\) 和 \(\small X_{t}\) 决定 \(\small H_{t-1}\) 和 \(\small \widetilde{H}_{t}\) 间的取舍
公式如下
\(\large R_{t} = \sigma(X_{t}W_{xr} + H_{t-1}W_{hr} + b_{r})\)
\(\large Z_{t} = \sigma(X_{t}W_{xz} + H_{t-1}W_{hz} + b_{z})\)
\(\large \widetilde{H}_{t} = tanh(X_{t}W_{xh} + R_{t} \odot H_{t-1} W_{hh} + b_{h})\)
\(\large H_{t} = (1-Z_{t}) \odot H_{t-1} + Z_{t} \odot \widetilde{H}_{t}\)
\(\large Y_{t} = softmax( H_{t} \times W_{hy} + b_{y} )\) (通常应该先过一层普通的全连接层,再接 Softmax)
重置门可能相当于把历史信息中和当前输入有关的内容拿出来,可能相当于有短期关系的记忆
tanh 再把这部分短期记忆和当前输入结合产生新的状态信息
更新门则同时起到选择当前有用信息 (选择门) 又起到放弃没用的历史信息保留长期记忆 (遗忘门) 的作用
与 LSTM 相比,GRU 少了一个门,而且只有一个状态量 H,参数比 LSTM 少,却能够达到与 LSTM 相当的功能
有一种简化版的 GRU,就是不要重置门,计算 \(\small \widetilde{H}_{t}\) 的时候,直接用 \(\small H_{t-1}\) 而不是 \(\small R_{t} \odot H_{t-1}\)
LSTM 代码例子
import numpy as np
import pandas as pd
from sklearn.model_selection import TimeSeriesSplit
from sklearn.preprocessing import LabelEncoder
from sklearn.preprocessing import MinMaxScaler
from tensorflow.keras import Sequential
from tensorflow.keras.layers import LSTM
from tensorflow.keras.layers import Dense
from tensorflow.keras.layers import Dropout
from tensorflow.keras.optimizers import Adam
# 打印 pd 数据的时候,如果列太多,会隐藏部分列,设置成不隐藏
pd.set_option('expand_frame_repr', False)
# 读数据
# 假设数据列分别是 日期、温度、湿度、气压、风速、风向、降水量、云量、空气质量
# 假设空气质量不是独立的,而是和前面的天气情况有关
# 然后希望能用前 10 天每天的 (温度、湿度、气压、风速、风向、降水量、云量、空气质量) 预测第 11 天的空气质量
# index_col=[0] 将第一列也就是 date 设置成 index
# 通过 parse_dates 转换日期
data = pd.read_csv('air_condition.csv', index_col=[0], parse_dates=True)
data.head()
'''
如果没指定 index 也没指定 parse_dates 那数据如下,会自动添加行号作为 index
date temperature humidity pressure wind_speed wind_direction rain cloud air_condition
0 2020/1/1 12:00 20 60 1000 2.1 W 0 50 50
1 2020/1/1 13:00 21 50 1010 1.4 E 0 60 60
2 2020/1/1 14:00 22 55 1020 1.0 SE 10 90 85
3 2020/1/1 15:00 20 65 1030 2.5 S 5 70 77
4 2020/1/1 16:00 21 60 1010 2.0 W 0 50 65
如果指定 index 和 parse_dates 那数据如下,使用 date 做 index,并转换日期
temperature humidity pressure wind_speed wind_direction rain cloud air_condition
date
2020-01-01 12:00:00 20 60 1000 2.1 W 0 50 50
2020-01-01 13:00:00 21 50 1010 1.4 E 0 60 60
2020-01-01 14:00:00 22 55 1020 1.0 SE 10 90 85
2020-01-01 15:00:00 20 65 1030 2.5 S 5 70 77
2020-01-01 16:00:00 21 60 1010 2.0 W 0 50 65
'''
# 将风速转换成数值
encoder = LabelEncoder()
data["wind_direction"] = encoder.fit_transform(data["wind_direction"])
data.head()
'''
temperature humidity pressure wind_speed wind_direction rain cloud air_condition
date
2020-01-01 12:00:00 20 60 1000 2.1 3 0 50 50
2020-01-01 13:00:00 21 50 1010 1.4 0 0 60 60
2020-01-01 14:00:00 22 55 1020 1.0 2 10 90 85
2020-01-01 15:00:00 20 65 1030 2.5 1 5 70 77
2020-01-01 16:00:00 21 60 1010 2.0 3 0 50 65
'''
'''
# 也可以用 one-hot 转
data = pd.get_dummies(data)
data.head()
temperature humidity pressure wind_speed rain cloud air_condition wind_direction_E wind_direction_S wind_direction_SE wind_direction_W
date
2020-01-01 12:00:00 20 60 1000 2.1 0 50 50 0 0 0 1
2020-01-01 13:00:00 21 50 1010 1.4 0 60 60 1 0 0 0
2020-01-01 14:00:00 22 55 1020 1.0 10 90 85 0 0 1 0
2020-01-01 15:00:00 20 65 1030 2.5 5 70 77 0 1 0 0
2020-01-01 16:00:00 21 60 1010 2.0 0 50 65 0 0 0 1
'''
'''
# 或者通过 values 处理
values = data.values
values[:, 4] = encoder.fit_transform(values[:, 4])
array([[20, 60, 1000, 2.1, 3, 0, 50, 50],
[21, 50, 1010, 1.4, 0, 0, 60, 60],
[22, 55, 1020, 1.0, 2, 10, 90, 85],
[20, 65, 1030, 2.5, 1, 5, 70, 77],
[21, 60, 1010, 2.0, 3, 0, 50, 65]], dtype=object)
data = pd.DataFrame(values, index=data.index, columns=data.columns)
'''
# 再做归一化
scaler = MinMaxScaler(feature_range=(0, 1))
data_scaled = scaler.fit_transform(data)
data = pd.DataFrame(data_scaled, index=data.index, columns=data.columns)
data.head()
'''
# 也可以这样
scaler = MinMaxScaler().fit(data.values)
data_scaled = scaler.transform(data.values)
data = pd.DataFrame(data_scaled, index=data.index, columns=data.columns)
data.head()
'''
'''
temperature humidity pressure wind_speed wind_direction rain cloud air_condition
date
2020-01-01 12:00:00 0.0 0.666667 0.000000 0.733333 1.000000 0.0 0.00 0.000000
2020-01-01 13:00:00 0.5 0.000000 0.333333 0.266667 0.000000 0.0 0.25 0.285714
2020-01-01 14:00:00 1.0 0.333333 0.666667 0.000000 0.666667 1.0 1.00 1.000000
2020-01-01 15:00:00 0.0 1.000000 1.000000 1.000000 0.333333 0.5 0.50 0.771429
2020-01-01 16:00:00 0.5 0.666667 0.333333 0.666667 1.000000 0.0 0.00 0.428571
'''
##########
# pandas 还可以做很多其他操作,比如去掉有异常值的数据,去掉有丢失值的数据,对丢失值做插值补全等等
##########
##########
# 下面取每 10 天的所有特征数据作为一个样本,第 11 天的 air_condition 作为标签
# 假设共 n 天数据,那么 x 的大小是 (n-10, 10, 8), 而 y 的大小是 (n-10, 1)
##########
x, y = list(), list()
values = data.values
value_length = len(values)
for i in range(value_length):
# 每个样本需要 10 天的 x 和 1 天的 y 共 11 天数据
if i + 10 > value_length - 1:
break
x_slice = [ix for ix in range(i, i + 10)]
# 获取每个样本的输入序列 seq_x 和标签 seq_y
seq_x = values[x_slice, :]
seq_y = values[i + 10, 7]
x.append(seq_x)
y.append(seq_y)
x = np.array(x)
y = np.array(y)
print(x.shape)
print(y.shape)
print(type(x))
print(type(y))
'''
(1000, 10, 8)
(1000,)
<class 'numpy.ndarray'>
<class 'numpy.ndarray'>
'''
# 下面构建 LSTM 模型
model = Sequential()
# units 代表隐藏层的神经元数量,也是隐藏层的输出维度
# input_shape 代表输入的维度,这里是连续 10 天,每天 8 个指标,所以是 (10, 8)
# activation 代表激活函数,默认是 tanh,可以通过 activation='relu' 改变激活函数
# return_sequences 为 true 表示每输入一天的数据,都要有对应的输出
# 为 false 表示要输入 10 天的数据,才有对应的输出
# 由于这里设置多层 LSTM,所以第一层设置为 true,要求每天的输入都有对应输出
# 如果只有一层,或者是最后一层,就设置为 false (默认就是 false),表示输入 10 天数据,才有对应的输出
model.add(LSTM(units=20, return_sequences=True, input_shape=(10, 8)))
# 可以在两层 LSTM 之间加入 Dropout 层
model.add(Dropout(rate=0.1))
# 第二层不用指定 input,会自动按照第一层的输出设置,这里应该是 (10, 20),
# 10 是因为第一层每天都有对应输出,20 是因为第一层 units 是 20
model.add(LSTM(units=10))
# 和全连接层间也可以加入 Dropout 层
model.add(Dropout(rate=0.2))
# 后面接全连接层,不需要指定输入维度,自动按上层的输出设置,这里是 (1, 10),
# 因为第二层的 units 是 10,并且 10 天输入数据只对应一个输出
model.add(Dense(units=5, activation='relu'))
# 最后是一维输出,只预测第 11 天的空气质量一个值,如果是分类的输出,这里的 units 就是分类数,激活函数就是 softmax
model.add(Dense(units=1, activation='relu'))
# 编译模型
model.compile(optimizer=Adam(learning_rate=0.005), loss='mae', metrics=['accuracy'])
model.summary()
# 训练模型
model.fit(x, y, epochs=100, verbose=1, shuffle=False)
# 预测,注意这里每个数据,比如 x[5] 都是一个 (10, 8) 维的数据,每个返回是一个值,这里 predict 是 (5,1) 维数据
predict = model.predict(x[5:10], verbose=1)
print(type(predict))
'''
<class 'numpy.ndarray'>
'''
可以把样本数据拆成多个数据集
KFold:比如把数据划分成 4 分,其中一个做验证集,其他3个合成做训练集,然后换一个做验证集,剩下3个做训练集,如此可以训练出 4 个模型,预测的时候,如果预测值,就取4个模型的平均,如果分类,就按多数取胜
TimeSeriesSplit:用于 RNN,类似 KFold 但要考虑顺序,比如分成 4 分,用第一分做训练,第二份做验证,然后用第一份和第二份合成做训练,用第3份做验证,再用 1~3 份做训练集,用第 4 份做验证集,这样可以训练出 3 个模型
timeSeriesSplit = TimeSeriesSplit(n_splits=4)
model_list = []
predict_list = []
for train, test in timeSeriesSplit.split(x, y):
# 构建模型
model = Sequential()
model.add(LSTM(units=20, input_shape=(10, 8)))
model.add(Dense(units=1, activation='relu'))
model.compile(optimizer=Adam(learning_rate=0.005), loss='mae', metrics=['accuracy'])
# 用训练集训练
model.fit(x[train], y[train], epochs=100, verbose=1, shuffle=False)
# 用测试集验证
predict = model.predict(x[test], verbose=1)
# 保存模型和验证结果
model_list.append(model)
predict_list.append(predict)
# 预测
predict = None
for model in model_list:
predict_y = model.predict(x[5:10], verbose=1)
if predict is None:
predict = predict_y
else:
predict = predict + predict_y
predict = predict/len(model_list)
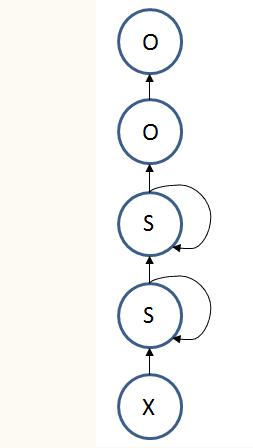
上面的模型按时间序列展开是这样的
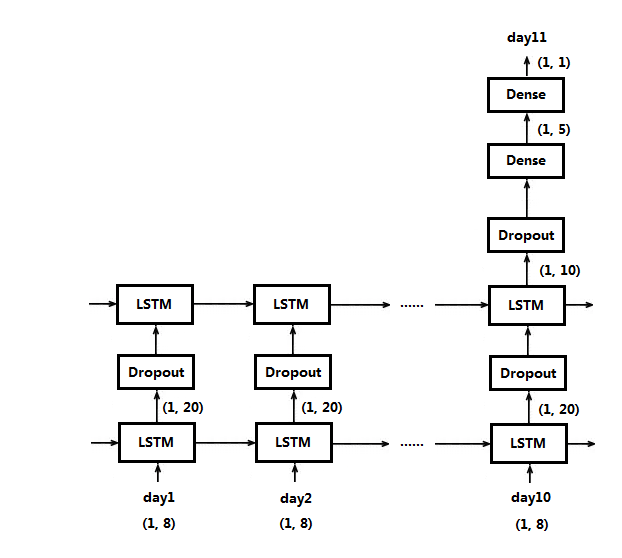
注意这是逻辑上的,实际上还是只有两个的 LSTM
Embedding 层
One-Hot 这种模式,有一个缺点,就是太稀疏,如果一个词典,有 10000 个词,那么意味着每个输入值,有 9999 个空值,只有一个真正有值,造成空间和计算的浪费
有了改善这个问题,可以给输入层会加一个 Embedding 层,作用是使稀疏的矩阵变稠密
比如一个 50 个分类的 one-hot,我们希望变成 5 个输入值就好,那么用了 Embedding 后,Embedding 相当于产生一个 (50, 5) 的列表,接受输入后,就在列表找对应的位置,找到后输出 5 个值
from tensorflow.keras import Sequential
from tensorflow.keras.layers import Embedding
model = Sequential()
# 50 就是 one-hot 的个数,5 就是转换后输出的个数,input_length 是多少个样本,可以是 None
model.add(Embedding(50, 5, input_length=7))
这个 Embedding 必须是第一层,他的内部参数也是训练出来的
保存多个模型
前面的例子中,可以训练多个模型,在保存模型的时候,把 迭代次数 和 loss 也作为模型名字的一部分保存,这样方便以后选最好的模型使用
RNN 的变种
双向循环神经网络:有些问题中,当前的输出不仅和之前的状态有关,也和之后的状态相关
深层循环神经网络:在每个时刻上将循环体结构复制了多次
RNN 的应用例子
序列判断:比如输入一句话,判断这句话的情绪是正面、负面、还是中性
序列预测:输入一个序列,预测后面一个或多个序列的输出
视图描述:图片或视频经过 CNN 提取特征,再输入 RNN 得到一句话,描述图片或视频的内容
异步序列转换:输入序列,得到输出序列,但输入输出之间没相同顺序,比如某个先输入的值,对应的输出位置在后面,这种通常用两个 RNN,一个编码,一个解码,比如机器翻译,机器聊天等,其实视图描述也是这种类型,只是用 CNN 替代了第一个 RNN
机器翻译:输入一句话,经过一个 RNN 做编码,将编码后的内容传给另一个 RNN 解码成另一种语言的语句
机器聊天:同样是两个 RNN,一个对输入做编码,另一个接收编码后,产生回复的语句
同步序列转换:输入序列,得到输出序列,输入输出顺序没变化,比如输入句子,删除多余内容,输入一段没有标点的话,给它分段,加标点符号,等等
RNN 的不足
RNN 缺点是并发度不行,因为是串行输入的
这样导致 GPU 利用率低,如果是 CNN 的话,GPU 利用率很高,可以取到百分之 80,90

 浙公网安备 33010602011771号
浙公网安备 33010602011771号