机器学习:卷积神经网络
和全连接神经网络的主要差别
全连接神经网络:
每个神经元的输入数据,都使用了上一层的所有神经元的输出数据,每个神经元的输出数据,都被作为下一层的所有神经元的输入数据,这容易导致参数数量膨胀、过拟合、容易陷入局部最优,尤其用于图像识别时,如果把每个像素当成一个特征,则会有大量的特征值,比如一副 32 * 32 * 3(3位 RGB)的图片,输入层就有 3072 个点,假设第一个变换层有 100 个点,则这一层就需要 3072*100+100 = 307300 个参数,如果是精度更高的图片,加上网络还有多层,参数太多了
对图像做一维化后,会失去位置信息,并且对颜色数据的处理不足
同一个元素在图片中的不同位置,(比如手机出现在图片的不同位置),应该共享相同的权重参数,但全连接做不到
为了找图片中某个很小的元素,(比如找出图片中的所有眼睛),只用很小的参数扫描即可,全连接做不到
卷积神经网络:
主要用于图像识别,其效果非常好,同时黑箱程度也非常著名(既数学上还无法解释证明)
在全连接神经网络的基础上增加了卷积层(注意这里说的卷积和数学上的卷积不是一个意思),卷积层之间采用局部连接,既每个输出数据只被下一层的部分数据使用,每个数据只使用上一层的部分输出数据,卷积层直接使用三维数据(比如图片的长、宽、颜色),而全连接网络需要将其转为一维数据,所以全连接层一般用一排圆圈表示,而卷积层一般用一个长方体表示,卷积层通过卷积核(也叫 filter、滤波器)对数据进行转换,产生二维数据,多个卷积核产生多个二维数据输出,最终输出的还是三维数据
卷积网络还可以采样缩小图片
卷积层相当于特征提取的作用,最后还是要通过全连接网络进行分类,实际上后面接其他分类算法也可以,只不过一般都是用全连接神经网络
卷积神经网络的训练过程与全连接神经网络基本一致
局部连接(Sparse Connectivity)& 权值共享(Shared Weights)
卷积的两个基本概念
看到一个有趣的比喻:就像我们看风景,由于视野有限,实际上我们一次只能看到一部分风景,为了看到完整的风景我们必须四处张望,然后得到对全景的感受。实际上完整地看一次可能还不够,可能还会看多次,这次关注点是人,下次关注点是树林,等等,但每次四处张望我们都用相同的思想分析看到的每一部分
在这里,视野有限就是局部连接,四处张望并得到对全景的感受就是卷积,使用的思想就是卷积核,同一次张望使用相同的思想观察全景就是权值共享,用不同的思想多次观察全景就是使用多个卷积核
更具体的说,卷积核是一个函数,一个卷积层有多个卷积核函数,不同卷积核的函数参数不一样,每次卷积核取上一层的一小部分三维数据作为输入,计算得出一个输出值,从左到右再从上到下扫一遍得到一个二维数据结果,多个卷积核的结果组成三维数据,每个卷积核的大小一样,卷积核的大小决定了输出的长度和宽度,卷积核的数量决定了输出的深度
局部连接和权值共享大大减少了参数的数量
经典数据集
MNIST
0~9 的手写体数据集,60000 张 28 x 28 的图片
FASHION MNIST
包、衣服、鞋等图片,60000 测试集,10000 训练集,像素为 32 x 32
CIFAR-10
60000 张 10 个不同种类的图片,像素为 32 x 32
CIFAR-100
60000 张 100 个不同种类的图片,像素为 32 x 32
100 个类被分成 20 个超类,每张图片即属于一个类又属于一个超类,比如鱼、鲨鱼
ImageNet
约 1500 万张图片,超过 20000 个分类,可以选择 32 x 32 或 64 x 64 的尺寸
卷积神经网络结构
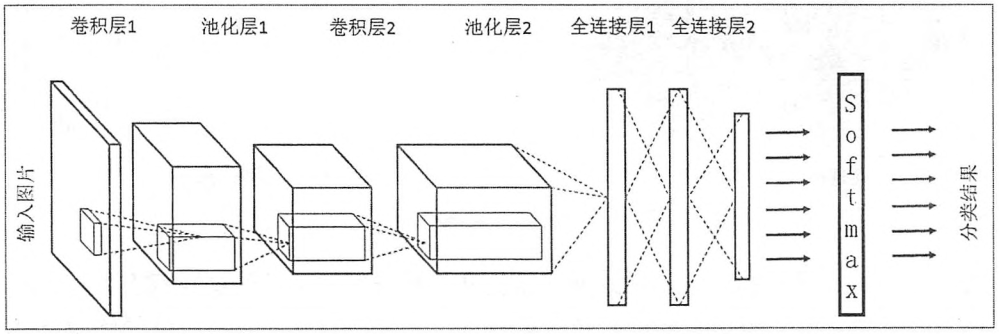
卷积神经网络一般包括了输入层、卷积层、池化层、全连接层、输出层
输入层
将原始数据以三维的形式输入
卷积层
结构上,和全连接网络的两点不同
1. 输入的形式不同(一维和三维)
2. 层与层之间的连接方式不同(全连接和局部连接)
每次计算一小块数据相当于获取抽象程度更高的特征
计算方法如下
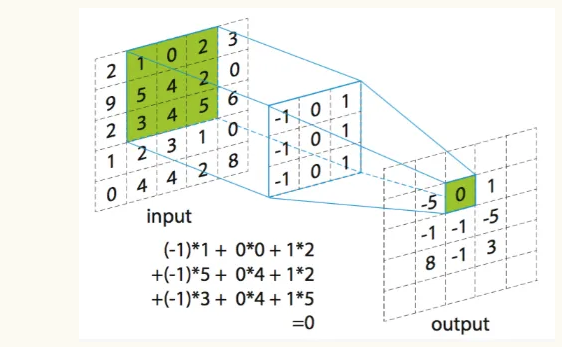
中间这个就是卷积核,按照这个卷积核的大小,对输入数据不断扫描,相同位置相乘,再把结果相加,得到的值,就是输出的一位,如果输入不是二维的,比如是 (5,5,3),那么卷积核的第三个维度也必须一样,必须是 (m,n,3) 维的,卷积核的第一个平面扫描输入的第一个平面,第二个平面扫描输入的第二个平面的相同位置,以此类推,最后全部相加,得到的还是一个值,就是说一个卷积核的输出肯定是二维的,通常会用多个卷积核,这样多个卷积核的输出就拼成多维的输出
假设一副 \(\small 3 \times 3 \times 3\) 的图像,其内容为
\(\small R = \begin{bmatrix} 11 & 12 &13 \\ 14 & 15 & 16 \\ 17 & 18 & 19 \end{bmatrix}\) \(\small G = \begin{bmatrix} 21 & 22 &23 \\ 24 & 25 & 26 \\ 27 & 28 & 29 \end{bmatrix}\) \(\small B = \begin{bmatrix} 31 & 32 &33 \\ 34 & 35 & 36 \\ 37 & 38 & 39 \end{bmatrix}\)
卷积网络直接接受这个三维数组作为输入
假设使用 2 个卷积核,每个卷积核的长宽深是 \(\small 2 \times 2 \times 3\) (深度必须和上一层的相同)
每个卷积核的假设参数如下
卷积核 1
\(\small W_{1R}= \begin{bmatrix} 0.1 & 0 \\ 0.1 & 0.1\end{bmatrix}\) \(\small W_{1G}= \begin{bmatrix} 0.2 & 0.2 \\ 0 & 0.2 \end{bmatrix}\) \(\small W_{1B} = \begin{bmatrix} 0 & 0.3 \\ 0.3 & 0 \end{bmatrix}\) \(\small b_{1} =4\)
卷积核 2
\(\small W_{2R}= \begin{bmatrix} 0 & 0.4 \\ 0.4 & 0.4 \end{bmatrix}\) \(\small W_{2G}= \begin{bmatrix} 0.5 & 0.5 \\ 0.5 & 0 \end{bmatrix}\) \(\small W_{2B} = \begin{bmatrix} 0.6 & 0 \\ 0 & 0.6 \end{bmatrix}\) \(\small b_{2}=7\)
卷积核从第 0 行第 0 列开始,从左到右,从上到下,取 \(\small 2 \times 2 \times 3\) 的数据计算
当处于第 i 行第 j 列时,将取得的数据转换为激活函数的输入
\(\large z = \sum_{k=R}^{B}\sum_{m=0}^{1}\sum_{n=0}^{1}W_{k}(m,n)\times X_{k}(i+m,\ j+n) + b\)
假设卷积核的激活函数为恒同函数
\(\small f(z) = z\)
则上面例子的输出为
\(\small f(0.1\times 11 + 0\times 12 + 0.1\times 14 + 0.1\times 15 +\)
\(\small 0.2\times 21 + 0.2\times 22 + 0\times 24 + 0.2\times 25 +\)
\(\small 0\times 31 + 0.3\times 32 + 0.3\times 34 + 0\times 35 + 4) = 41.4\)
\(\small f(0.1\times 12 + 0\times 13 + 0.1\times 15 + 0.1\times 16 +\)
\(\small 0.2\times 22 + 0.2\times 23 + 0\times 25 + 0.2\times 26 +\)
\(\small 0\times 32 + 0.3\times 33 + 0.3\times 35 + 0\times 36 + 4) = 42.9\)
\(\small f(0.1\times 14 + 0\times 15 + 0.1\times 17 + 0.1\times 18 +\)
\(\small 0.2\times 24 + 0.2\times 25 + 0\times 27 + 0.2\times 28 +\)
\(\small 0\times 34 + 0.3\times 35 + 0.3\times 37 + 0\times 38 + 4) = 45.9\)
\(\small f(0.1\times 15 + 0\times 16 + 0.1\times 18 + 0.1\times 19 +\)
\(\small 0.2\times 25 + 0.2\times 26 + 0\times 28 + 0.2\times 29 +\)
\(\small 0\times 35 + 0.3\times 36 + 0.3\times 38 + 0\times 39 + 4) = 47.4\)
\(\small f(0\times 11 + 0.4\times 12 + 0.4\times 14 + 0.4\times 15 +\)
\(\small 0.5\times 21 + 0.5\times 22 + 0.5\times 24 + 0\times 25 +\)
\(\small 0.6\times 31 + 0\times 32 + 0\times 34 + 0.6\times 35 + 7) = 96.5\)
\(\small f(0\times 12 + 0.4\times 13 + 0.4\times 15 + 0.4\times 16 +\)
\(\small 0.5\times 22 + 0.5\times 23 + 0.5\times 25 + 0\times 26 +\)
\(\small 0.6\times 32 + 0\times 33 + 0\times 35 + 0.6\times 36 + 7) = 100.4\)
\(\small f(0\times 14 + 0.4\times 15 + 0.4\times 17 + 0.4\times 18 +\)
\(\small 0.5\times 24 + 0.5\times 25 + 0.5\times 27 + 0\times 28 +\)
\(\small 0.6\times 34 + 0\times 35 + 0\times 37 + 0.6\times 38 + 7) = 108.2\)
\(\small f(0\times 15 + 0.4\times 16 + 0.4\times 18 + 0.4\times 19 +\)
\(\small 0.5\times 25 + 0.5\times 26 + 0.5\times 28 + 0\times 29 +\)
\(\small 0.6\times 35 + 0\times 36 + 0\times 38 + 0.6\times 39 + 7) = 112.1\)
最终是一个 \(\small 2\times 2\times 2\) 的输出
\(\small \begin{bmatrix} 41.4 & 42.9 \\ 45.9 & 47.4\end{bmatrix}\) \(\small \begin{bmatrix} 96.5 & 100.4 \\ 108.2 & 112.1\end{bmatrix}\)
同时也是下一个卷积层的输入,可以看到,下一层输入的大小,由上一层输入的长和宽,以及卷积核的个数,共同决定
可以看到,参数个数由核数、核的长宽、输入数据频道大小(或深度)决定,和输入数据的长宽没有关系,这就大大减少了需要的参数个数,卷积核大小可以远小于输入数据的大小,这就是局部视野,在由左到右,由上到下移动的过程中,使用的系数是一样的,这就是权值共享
参数个数 = (核长 x 核宽 x 输入数据频道+1) x 核数
上面的例子共需要 \(\small (2\times 2\times 3+1)\times2 = 26\)
卷积核的大小一般选择 \(\small 3\times 3\) 或 \(\small 5\times 5\) 居多
一般卷积层的输出数据的频道数会变得更多
Padding
卷积会导致输出数据的长宽变小,如果需要避免这个问题,可以采用填充(Padding)
即在外围再增加一层数据,比如用 0 填充,比如前面的数据中的 R 频道变为
\(\small R = \begin{bmatrix} 0 & 0 & 0 & 0 & 0\\ 0 & 11 & 12 & 13 & 0\\0 & 14 & 15 & 16 & 0\\ 0 & 17 & 18 & 19 & 0\\ 0 & 0 & 0 & 0 & 0\end{bmatrix}\)
此时用 2 x 2 卷积核,输出是 4 x 4,用 3 x 3 卷积核,输出是 3 x 3,避免了输出维度变小
Stride
此外还可以通过调整步长,改变输出数据的维度
步长既每次向左、向下移动的步数,前面使用的步长都是 1
假设卷积核使用步长 2,长宽为 3 x 3,系数 w 全是 1,偏移 b 是 0
不考虑 GB 频道,只对用 0 填充后的 R 使用,则输出为
\(\small f(1\times 0 + 1\times 0 + 1\times 0 + 1\times 0 + 1\times 11 + 1\times 12 + 1\times 0 + 1\times 14 + 1\times 15) = 52\)
\(\small f(1\times 0 + 1\times 0 + 1\times 0 + 1\times 12 + 1\times 13 + 1\times 0 + 1\times 15 + 1\times 16 + 1\times 0) = 56\)
\(\small f(1\times 0 + 1\times 14 + 1\times 15 + 1\times 0 + 1\times 17 + 1\times 18 + 1\times 0 + 1\times 0 + 1\times 0) = 64\)
\(\small f(1\times 15 + 1\times 16 + 1\times 0 + 1\times 18 + 1\times 19 + 1\times 0 + 1\times 0 + 1\times 0 + 1\times 0) = 68\)
既输出 2 x 2 的数据
\(\small \begin{bmatrix} 52 & 56 \\ 64 & 68\end{bmatrix}\)
TensorFlow 的 padding 有两种方式
VALID:
不会添加新元素
out_height = ceil((in_height - filter_height + 1) / stride) # ceil 为向上取整
out_width = ceil((in_width - filter_width + 1) / stride)
SAME:
TensorFlow 自动计算需要在四周添加的元素维度
(不一定需要四周都添加,优先添加上方和左方,添加元素为 0)
使得输出数据的长和宽为
out_height = ceil(in_height / stride)
out_width = ceil(in_width / stride)
需要添加的元素数量
pad_needed_height = (out_height – 1) * stride + filter_height - in_height
pad_top = pad_needed_height / 2
pad_down = pad_needed_height - pad_top
pad_needed_width = (out_width – 1) * stride + filter_width - in_width
pad_left = pad_needed_width / 2
pad_right = pad_needed_width – pad_left
空洞卷积
比如用 3x3 的卷积核去识别 5x5 的图像,
可以计算 1,3,5 行的第 1,3,5 例值,跳过 2,4 行和 2,4 列
其实相当于压缩
卷积核和步长的选择
一般不用偶数卷积核,一般是 (3, 3) 或 (5, 5) 之类的,原因是后面的 padding 之类的操作不方便
卷积核一般比较小,通常就是 (3, 3) 或 (5, 5),其中 (3, 3) 用的比较多
大卷积核
优点看到的视野大
缺点参数太多
卷积核一般用正方形,但也可以不是正方形,但用的比较少
一般用小步长,通常就是用 1 步长,大步长会漏信息
卷积还可以用于二维和一维数据
可以用于 3 维数据,比如彩色图片
也可以用于 2 维数据比如纯黑白图片
还可以用于 1 维数据,比如时序图 (Line Chart)
只要相应的调整卷积核的维度就可以(3维、2维、1维的卷积核)
注意,在 Keras 代码里,RGB 图片和黑白图片,都是二维卷积,深度叫频道 channel,不当作卷积的维度,就是说,RGB 图片用的是频道为 3 的二维卷积,黑白图片用的是频道为 1 的二维卷积,而一维卷积同样可以有多个频道,可以参考后面的例子
卷积层的激活函数
通常就是 ReLU 用的比较多
池化层(Pooling)
两个卷积层之间往往会有一个池化层,目的是缩小矩阵尺寸,以加快计算速度、防止过拟合
池化层和卷积类似,也有长、宽、Padding、Stride
区别在于,池化层不是加权求和激活,而是简单的取最大值或平均值,并且池化层不会横跨多个频道
取最大值的称为极大池化(Max Pooling),取平均值的称为平均池化(Average Pooling)
为什么取平均或最大:CNN 一般处理的是图像,像素级的差异很小,这为上述两种池化提供了一定的合理性
实际中池化层的长宽用的最多的是 2 x 2 或 3 x 3
假设某个卷积层的输出如下
\(\small \begin{bmatrix} 11 & 12 &13 \\ 14 & 15 & 16 \\ 17 & 18 & 19 \end{bmatrix}\) \(\small\begin{bmatrix} 21 & 22 &23 \\ 24 & 25 & 26 \\ 27 & 28 & 29 \end{bmatrix}\) \(\small \begin{bmatrix} 31 & 32 &33 \\ 34 & 35 & 36 \\ 37 & 38 & 39 \end{bmatrix}\)
池化层为 2 x 2 采用平均池化,各输出为
avg(11,12,14,15) = 13 avg(12,13,15,16) = 14 avg(14,15,17,18) = 16 avg(15,16,18,19) = 17
avg(21,22,24,25) = 23 avg(22,23,25,26) = 24 avg(24,25,27,28) = 26 avg(25,26,28,29) = 27
avg(31,32,34,35) = 33 avg(32,33,35,36) = 34 avg(34,35,37,38) = 36 avg(35,36,38,39) = 37
最终输出 3 x 2 x 2 的数据
\(\small \begin{bmatrix} 13 &14 \\ 16 & 17\end{bmatrix}\) \(\small \begin{bmatrix} 23 & 24 \\ 26 & 27\end{bmatrix}\) \(\small \begin{bmatrix} 33 &34 \\ 36 &37\end{bmatrix}\)
可以看到池化层起压缩的作用
现在用最大池化层的多,因为卷积层是提取特征的,取平均反而破坏特征的提取识别
另一方面,池化层也不再是标配
实际上可以通过改步长,来压缩,而不需要池化层
池化层导致信息损失
Dropout 是更好的防止过拟合的正则化方法
实际应用中,图片信息大,更怕欠拟合
但是由于池化层计算简单,还是有些模型会使用
全连接层
将池化层或卷积层的输出铺平,然后再接全连接层,全连接层同样可以有多层,进行分类或预测值
可以将输入层和卷积层当作是特征提取,全连接层和输出层根据提取的特征作分类或预测
全连接层一般不会有太多层
理论上讲后面的分类可以用其他算法比如 SVM 等,但一般都是用的全连接神经网络
损失函数
全连接的输出会跟损失函数
分类的话通常就是交叉熵 Cross Entropy
回归的话通常就是 MSE
反向传播算法
原理和全连接神经网络是一样的,也是从输出层开始,计算误差,求梯度,通过梯度更新参数
公式推导可能复杂了点,就不列出来了
卷积计算的解决方案
1 变换成比较大规模的矩阵相乘
2 利用快速傅里叶变换(Fast Fourier Transform,FFT)
TensorFlow 提供了各种函数用于卷积网络的实现
CNN 对 GPU 的利用率可以达到百分之 80,90
数据准备
实践中,AI 项目,数据处理这部分比较繁琐麻烦
像收集数据,归一化,数值化,one-hot 处理,剔除异常值,打标签
此外还有如何令样本多样化的问题
比如使用 shuffle 函数实现随机化,举个例子,动物数据集,有可能出现猫都在前面连续出现而狗都在后面连续出现,这种情况会不利于训练,甚至有可能划分后变成训练集都是猫,而验证集都是狗
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(images, labels, test_size=0.1, shuffle = True)
比如通过数据增强,从一张图片产生多张图片,比如旋转,翻转,缩放,偏移,改变亮度,剪切,颜色变化
from tensorflow.keras.preprocessing.image import ImageDataGenerator
实践证明,这种数据增强的方法,有效使样本更多样化,而且技术简单,效果好
代码例子
import matplotlib.pyplot as plt
import numpy as np
from tensorflow import keras
from tensorflow.keras import models
from tensorflow.keras import Sequential
from tensorflow.keras.layers import BatchNormalization
from tensorflow.keras.layers import Conv2D
from tensorflow.keras.layers import Dense
from tensorflow.keras.layers import Dropout
from tensorflow.keras.layers import Flatten
from tensorflow.keras.layers import MaxPool2D
from tensorflow.keras.optimizers import Adam
# 读入训练集,和测试集
(train_x, train_y), (val_x, val_y) = keras.datasets.cifar100.load_data()
# <class 'numpy.ndarray'>
# <class 'numpy.ndarray'>
print(type(train_x))
print(type(train_y))
# (50000, 32, 32, 3)
# (50000, 1)
print(train_x.shape)
print(train_y.shape)
# (10000, 32, 32, 3)
# (10000, 1)
print(val_x.shape)
print(val_y.shape)
# 可以把图片画出来
plt.figure()
plt.imshow(train_x[500])
plt.colorbar()
plt.show()
# [[[255 255 255]
# [255 255 255]
# [255 255 255]
# ...
# [195 205 193]
# [212 224 204]
# [182 194 167]]
#
# ...
#
# [[ 87 122 41]
# [ 88 122 39]
# [101 134 56]
# ...
# [ 34 36 10]
# [105 133 59]
# [138 173 79]]]
print(train_x[0])
# 归一化
train_x = train_x.astype('float32') / 255
val_x = val_x.astype('float32') / 255
# [[[1. 1. 1. ]
# [1. 1. 1. ]
# [1. 1. 1. ]
# ...
# [0.7647059 0.8039216 0.75686276]
# [0.83137256 0.8784314 0.8 ]
# [0.7137255 0.7607843 0.654902 ]]
#
# ...
#
# [[0.34117648 0.47843137 0.16078432]
# [0.34509805 0.47843137 0.15294118]
# [0.39607844 0.5254902 0.21960784]
# ...
# [0.13333334 0.14117648 0.03921569]
# [0.4117647 0.52156866 0.23137255]
# [0.5411765 0.6784314 0.30980393]]]
print(train_x[0])
# 构建模型
model = Sequential()
# 卷积层提供 Conv1D, Conv2D, Conv3D 三种
# 注意这里的 1D, 2D, 3D 不包含 channel
# 一张 RGB 图片是一个 2D 的面,有 3 个 channel,所以应该用 Conv2D
# 指定输入数据大小为 (32, 32, 3)
# 指定 64 个大小为 (3,3) 的卷积核 (可以只填一个 3 默认正方形),每个核的 channel 自动取输入的 channel 也就是 3
# 使用 ReLU 作为激活函数
# 填充模式使用 same,这样输出的大小也是 32 * 32,输出的 channel 数则是 64 和卷积核个数一样
model.add(Conv2D(64, (3, 3), activation='relu', padding='same', input_shape=(32, 32, 3)))
# 再做一层卷积 (可以连续做卷积)
# 卷积核 channel 数自动取 64
# 输入大小自动取上一层的输出大小,也就是 (32, 32, 64)
model.add(Conv2D(64, (3, 3), activation='relu', padding='same'))
# 做归一化
model.add(BatchNormalization())
# 最大池化层,大小是 2*2 (也是默认值),也可以只指定一个 2,两个方向的步长都是 2 (默认值是和 pool_size 一致)
# 输出大小是 (16, 16, 64)
model.add(MaxPool2D(pool_size=(2, 2), strides=(2, 2)))
# 可以加 Dropout
# model.add(Dropout(0.2))
# 再继续下一个卷积层
# 用 128 个卷积核,channel 数据自动取 64
# 输入自动取 (16, 16, 64)
model.add(Conv2D(128, (3, 3), activation='relu', padding='same'))
# 再做一层卷积
# 卷积核 channel 数自动取 128
# 输入大小自动取上一层的输出大小,也就是 (16, 16, 128)
model.add(Conv2D(128, (3, 3), activation='relu', padding='same'))
# 做归一化
model.add(BatchNormalization())
# 最大池化层,大小是 2*2 (也是默认值),也可以只指定一个 2,两个方向的步长都是 2 (默认值是和 pool_size 一致)
# 输出大小是 (8, 8, 128)
model.add(MaxPool2D(pool_size=(2, 2), strides=(2, 2)))
# 可以加 Dropout
# model.add(Dropout(0.2))
# 拍平, 变成大小为 8*8*128 的一维数据
model.add(Flatten())
# 接全连接层
model.add(Dense(4096, activation='relu'))
model.add(Dropout(0.2))
# 继续全连接层
model.add(Dense(2048, activation='relu'))
model.add(Dropout(0.2))
# 输出层,因为是分类,激活函数用 softmax,共 100 个分类,所以节点是 100
model.add(Dense(100, activation='softmax'))
# 输出模型 (debug 用)
model.summary()
# 编译模型
# 因为是分类,损失函数用交叉熵
model.compile(loss='sparse_categorical_crossentropy', optimizer=Adam(), metrics=['accuracy'])
# 训练模型
# 在比较旧的机器,把第一个全连接层改成 2048 后,训练了 2.5 小时
# 训练集的准确率有 0.88 但测试集的准确率只有 0.45,模型还有待提高
model.fit(train_x, train_y, batch_size=500, epochs=100, validation_data=(val_x, val_y))
# 预测
index = 1001
print(train_y[index])
result = model.predict(train_x[index:index+1]) # 输入必须是列表,哪怕只有一个元素
print(result.shape) # (1, 100)
max_type = np.where(result == np.max(result)) # 取最大值的下标
print(max_type) # (array([0]), array([30])) 预测结果是分类 30
# 获取测试集的损失值,和准确度
loss, accuracy = model.evaluate(val_x, val_y, verbose=0)
# 保存模型
model_name = 'my_cnn_model_' + str(loss) + '_' + str(accuracy)
model.save(model_name)
# 读入模型
my_model = models.load_model(model_name)
有 4000 多万个参数,其中大多数都是全连接层的,占 90% 多,卷积层的参数并不是很多
经典模型
LeNet-5
1998 年提出,在 MNIST 数据集上达到 99.2% 的正确率
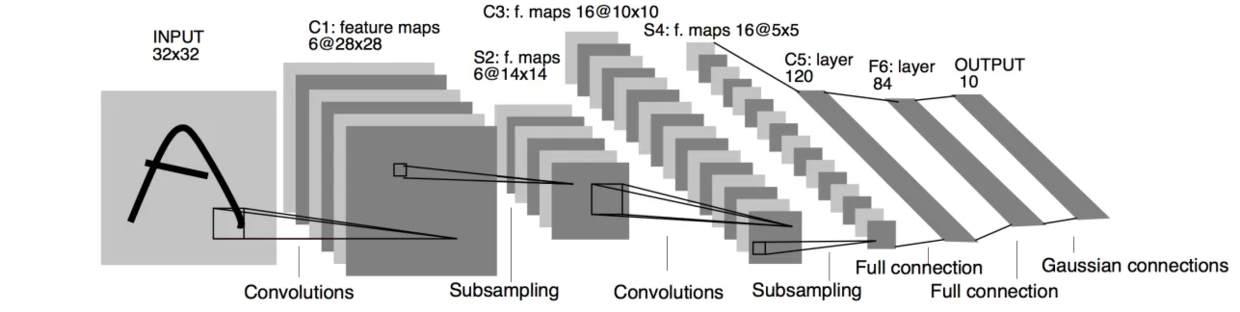
第一层:卷积层,32 x 32 x 1 输入,6 个步幅为 1 的 5 x 5 的卷积核,不用填充,输出矩阵为 28 x 28 x 6
第二层:池化层,过滤器 2 x 2,步长 2,输出 14 x 14 x 6
第三层:卷积层,16 个步幅为 1 的 5 x 5 的卷积核,不用填充,输出矩阵为 10 x 10 x 16
第四层:池化层,过滤器 2 x 2,步长 2,输出 5 x 5 x 16
第五层:全连接层,将输入铺平,得到 5 x 5 x 16 = 400 个输入,神经元个数 120
第六层:全连接层,神经元个数 84
第七层:全连接层,神经元个数 10
大约 6 万个参数,没有使用 ReLU 激活函数,也没有使用 GPU 训练
AlexNet
2012 的模型
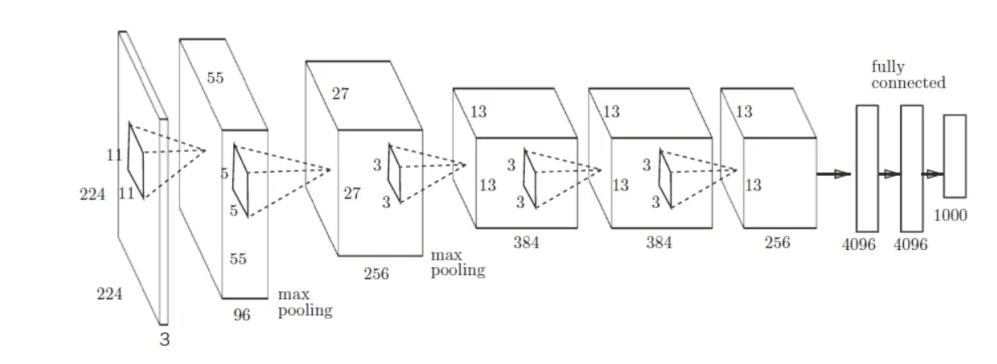
输入 227 x 227 x 3 (网上有说 224,估计一开始 224,后来为了计算方便,227 = 54 x 4 + 11 刚好不用 padding)
第一层:96 个步幅为 4 的 11 x 11 的卷积核 ,55 x 55 x 96 的输出
第二层:3 x 3 步幅为 2 的最大池化层,27 x 27 x 96 的输出
第三层:256 个步幅为 1 的 5 x 5 x 96 的采用 same 填充机制的卷积核,27 x 27 x 256 的输出
第四层:3 x 3 步幅为 2 的最大池化层,13 x 13 x 256 的输出
第五层:384 个步幅为 1 的 3 x 3 x 256 的采用 same 填充机制的卷积核,13 x 13 x 384 的输出
第六层:384 个步幅为 1 的 3 x 3 x 384 的采用 same 填充机制的卷积核,13 x 13 x 384 的输出
第七层:256 个步幅为 1 的 3 x 3 x 384 的采用 same 填充机制的卷积核,13 x 13 x 256 的输出
第八层:3 x 3 步幅为 2 的最大池化层,6 x 6 x 256 的输出
第九层:全连接层,把卷积层直接拍平,变成 9216 维输出,4096 个神经元的全连接层
第十层:再接一个 4096 个神经元的全连接层
第十一层:1000 个神经元的 Softmax 输出层
大约 6000 万个参数,卷积层只有大概 200 万个参数,其他的都是全连接层的
参数数量计算参考 https://blog.csdn.net/my_share/article/details/106599760
使用 ReLU 作为激活函数
使用 GPU 训练
在全连接层,加入 Dropout 防止过拟合
ZFNet
2013 年的模型
和 AlexNet 几乎一样,只是有些小的改动
第一层的卷积核由 11 x 11 步幅 4 改为 7 x 7 步幅 2
第二个卷积层的步幅由 1 改为 2,使得经过池化后和 AlexNet 的输出一样,后面的就都一样了
通过反卷积可视化 feature map (就是可视化卷积的结果)
通过可视化的 feature map 可以看到,前面的层学习轮廓、边缘、颜色、纹理等,后面层学习抽象特征
小卷积核,小步长,能学习更多特征,效果更好
通过遮挡图片的不同部位,可以发现决定图片类别的关键部位
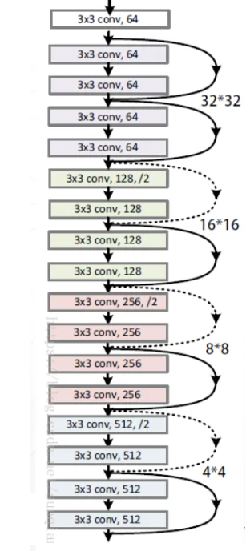
VGGNet
2014 年的模型,错误率 7.3%,前面的模型都不再使用了,但 VGGNet 还在用
全部用 3 x 3 的步幅为 1 的采用 same 填充的卷积核
全部用 2 x 2 的步幅为 2 的最大值池化层
有 A 到 E 的多个版本,以 D 版本,也叫 VGG-16 为例子
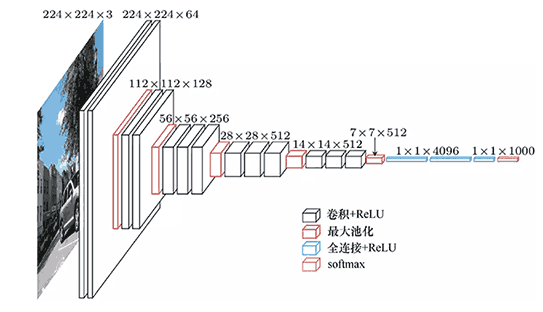
输入是 224 x 224 x 3
第一层:64 个 3 x 3 x 3 卷积核,输出 224 x 224 x 64
第二层:64 个 3 x 3 x 3 卷积核,输出 224 x 224 x 64
第三层:2 x 2 步幅为 2 的池化层,输出 112 x 112 x 64
第四层:128 个 3 x 3 x 64 卷积核,输出 112 x 112 x 128
第五层:128 个 3 x 3 x 64 卷积核,输出 112 x 112 x 128
第六层:2 x 2 步幅为 2 的池化层,输出 56 x 56 x 128
第七层:256 个 3 x 3 x 128 卷积核,输出 56 x 56 x 256
第八层:256 个 3 x 3 x 128 卷积核,输出 56 x 56 x 256
第九层:256 个 3 x 3 x 128 卷积核,输出 56 x 56 x 256
第十层:2 x 2 步幅为 2 的池化层,输出 28 x 28 x 256
第十一层:512 个 3 x 3 x 256 卷积核,输出 28 x 28 x 512
第十二层:512 个 3 x 3 x 256 卷积核,输出 28 x 28 x 512
第十三层:512 个 3 x 3 x 256 卷积核,输出 28 x 28 x 512
第十四层:2 x 2 步幅为 2 的池化层,输出 14 x 14 x 512
第十五层:512 个 3 x 3 x 512 卷积核,输出 14 x 14 x 512
第十六层:512 个 3 x 3 x 512 卷积核,输出 14 x 14 x 512
第十七层:512 个 3 x 3 x 512 卷积核,输出 14 x 14 x 512
第十八层:2 x 2 步幅为 2 的池化层,输出 7 x 7 x 512
第十九层:拍平,接 4096 个神经元的全连接层
第二十层:再接 4096 个神经元的全连接层
第二十一层:再接 1000 个神经元的 Softmax 输出层
13 个卷积层 + 3 个全连接层共 16 层需要计算参数
可以看到都是几个卷积层加一个池化层,长宽不断变小,厚度不断变大
Inception-v3
2014 年的模型,错误率 6.7%,可以做到 20 多层,也叫 Google Inception Net
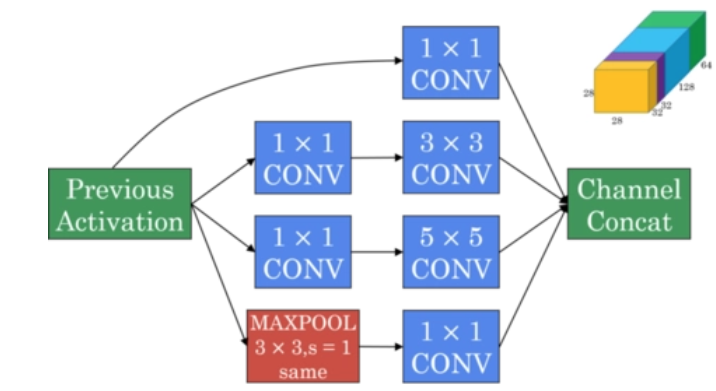
1 x 1 卷积:相当于只做通道融合
特征有大有小,但前面的模型的卷积层只选取某个长宽和核数
而 Inception-v3 的卷积层用多个不同的长宽和核数的卷积核,同时提取不同大小的特征
虽然使用不同的卷积核尺寸,但都使用 SAME 模式,使用相同的步长
这样输出数据的频道数可能不同但长宽相同,可以拼接成更大的频道作为输出
上图可以看到,每个卷积层使用了四组卷积核,分别是
第一组:1 x 1 卷积
第二组:1 x 1 卷积 + 3 x 3 卷积
第三组:1 x 1 卷积 + 5 x 5 卷积
第四组:3 x 3 步幅 1 的池化 + 1 x 1 卷积
4 个输出拼成更大的输出
比如分别输出 28 x 28 x 64、28 x 28 x 128、28 x 28 x 32、28 x 28 x 32
最终拼接成 28 x 28 x (32+32+64+128) = 28 x 28 x 256
这个模块叫 Inception Module
Inception-v3 由多层 Inception Module 串联,像下图这样
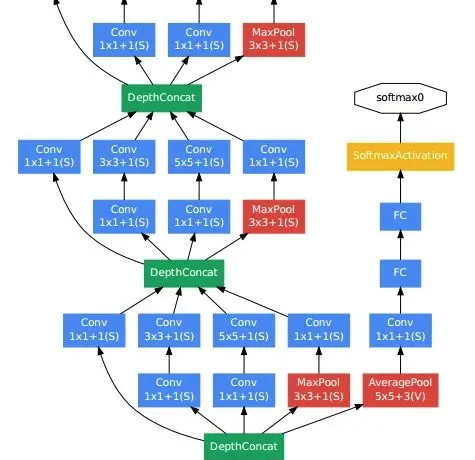
Inception Module 之间同样会有池化层
最后同样接全连接层
中间有的层会额外添加一个全连接层输出,因为有时不需要那么多层就可以判断结果了
ResNet (残差网络)
2015 年的模型,错误率 3.5%
像 VGG,GoogleNet,就做到十几二十层
如果层数进一步加深,到一定程度后错误率反而变大,这也叫网络退化问题
可能是因为梯度衰减的原因
而残差网络,能随着层数变多而错误率不断下降,可以做到 150 多层
其基本结构是残差块
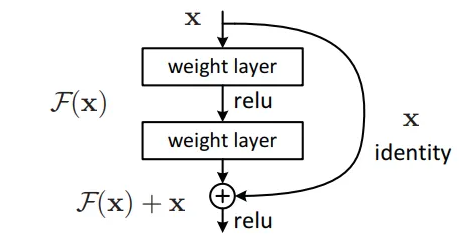
残差块使得可以跳过一些层 (按不同输入数据会跳不同的层)
正常的网络
\(\small x_{i+1} = g(\ f(x_{i}, \ w_{i+1})\ )\) -- f 是变换函数,g 是激活函数
\(\small x_{i+2} = g(\ f(x_{i+1}, \ w_{i+2})\ )\)
残差块 (以跳过一层为例子)
\(\small x_{i+1} = g(\ f(x_{i}, \ w_{i+1})\ )\)
\(\small x_{i+2} = g(\ f(x_{i+1}, \ w_{i+2})\ + x_{i})\)
可以看到在计算第 i+2 层的时候,把第 i 层的数据也直接拿进来了,这样使得梯度不会消失
\(\small \frac{\partial (f+x)}{\partial x} = \frac{\partial f}{\partial x} + 1 \ \ \ \ \ ?\)
残差网络由一层层残差块组成
代码 (网上摘抄来的,没验证过)
def res_block(x, input_filter, output_filter):
res_x = BatchNormalization()(x)
res_x = Activation('relu')(res_x)
res_x = Conv2D(kernel_size=(3,3), filters=output_filter, strides=1, padding='same')(res_x)
res_x = BatchNormalization()(res_x)
res_x = Activation('relu')(res_x)
res_x = Conv2D(kernel_size=(3,3), filters=output_filter, strides=1, padding='same')(res_x)
if input_filter == output_filter:
identity = x
else: #需要升维或者降维
identity = Conv2D(kernel_size=(1,1), filters=output_filter, strides=1, padding='same')(x)
output= keras.layers.add([identity, res_x])
return output
def resnet(x):
x = Conv2D(kernel_size=(3,3), filters=16 , strides=1, padding='same', activation='relu')(x)
x = res_block_v2(x, 16, 16)
x = res_block_v2(x, 16, 32)
x = BatchNormalization()(x)
y = Flatten()(x)
outputs = Dense(10, activation='softmax', kernel_initializer='he_normal')(y)
return outputs
(注意是没验证过的)
由于 F 像是当前输入和上一个输入的差值,所以叫残差
从拓扑图上看,就相当于在每若干层之间,拉一条线过去
Dense Net (稠密网络)
2018 年的模型
Dense Block:多个串行卷积层的长宽相同的输出,再拼成一个更厚的输出
通道变多了怎么办?再用卷积将其变小
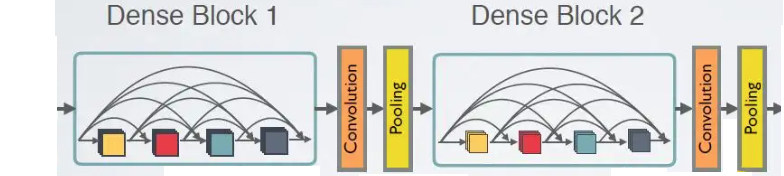
这模型可能用的少
Keras 直接使用经典模型
from tensorflow.keras import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.applications.densenet import DenseNet121
from tensorflow.keras.applications.resnet50 import ResNet50
from tensorflow.keras.applications.inception_v3 import InceptionV3
from tensorflow.keras.applications.vgg16 import VGG16
# 稠密网络
#
# include_top:
# True:自动加 avg pool,自动加全连接层,自动使用 softmax,并且输入为 (224, 224, 3)
# False:自己设计全连接层,自己定义 input_shape,pool 类型,激活函数,分类总数
# 默认是 True
# weights:
# imagenet:代表使用系统已经训练好的 weight,且如果 include_top 为 True,那么分类总数就是 1000
# path:使用自己训练好的 weight,path 是这个 weight 的存储路径
# None:随机初始化,模型建好后需要进行训练
model = Sequential()
model.add(DenseNet121(include_top=False, pooling='avg', weights=None, input_shape=(224, 224, 3)))
model.add(Dense(10, activation='softmax'))
# 指定分类总数
# 不使用训练好的 weight
# 自动加 avg pool,自动加全连接层,自动使用 softmax,并且输入为 (224, 224, 3)
model = DenseNet121(weights=None, classes=10)
# 直接使用系统训练好的模型
model = DenseNet121(weights='imagenet')
# 残差网络
model = Sequential()
model.add(ResNet50(include_top=False, pooling='avg', weights=None, input_shape=(224, 224, 3)))
model.add(Dense(10, activation='softmax'))
model = ResNet50(weights=None, classes=10)
model = ResNet50(weights='imagenet')
# inception v3 网络
model = Sequential()
model.add(InceptionV3(include_top=False, pooling='avg', weights=None, input_shape=(299, 299, 3)))
model.add(Dense(10, activation='softmax'))
model = InceptionV3(weights=None, classes=10)
model = InceptionV3(weights='imagenet')
# VGG 网络
model = Sequential()
model.add(VGG16(include_top=False, pooling='avg', weights=None, input_shape=(299, 299, 3)))
model.add(Dense(10, activation='softmax'))
model = VGG16(weights=None, classes=10)
model = VGG16(weights='imagenet')
可以直接使用预先设计好的模型
卷积神经网络的迁移学习
训练一个卷积网络,需要大量的标注图片(可能达到百万级别),实际上很难收集到如此大的数据量,即使能,也要花费大量的人力物力,而且训练过程可能需要几天甚至几周的时间
迁移学习就是将一个训练好的模型,通过简单的调整使其适用于一个新的问题
可以保留训练好的 Inception-v3 模型中所有卷积层的参数,只是替换全连接层
卷积层起特征提取的作用,如果一个训练好的系统可以区分很多种图片(比如1000种)的话,有理由认为这个系统的特征提取能力很强,可以直接用于新的分类问题,只需要训练分类即可
迁移学习的效果虽然没有重新学习的好,但所需要的训练样本和训练时间能大大减少

 浙公网安备 33010602011771号
浙公网安备 33010602011771号