

机器学习:神经网络
神经元模型
神经元具有如下三个功能
1. 能够接收 n 个神经元模型传递过来的信号
2. 能够在信号的传递过程中为信号分配权重
3. 能够将得到的信号进行汇总、变换并输出
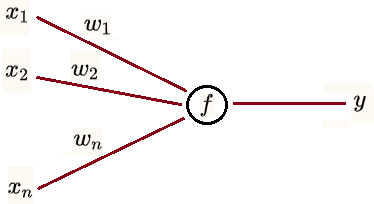
假设
,..., 为 n 个神经元的输出信号
,..., 为这 n 个信号对应的权值
为变换函数(也叫激活函数)
为神经元的输出
则有
可以看到神经元模型是将输入信号进行加权求和,再进行偏移,再进行变换输出
如果 为恒同映射,既 ,则有
可以看到此时神经元变成了线性回归方程,退化成了感知机
如果要处理非线性问题,就需要多层神经元
神经网络(Neural Network, NN)
许多神经元按照一定的层次结构进行连接即构成神经网络
一个非常自然的想法就是构建一个有向无环图(DAG 图)
遗憾的是现在我们对矩阵运算的依赖很大(因为矩阵运算是被高度优化了的)
所以目前主流的神经网络模型基本都是一类及其特殊的 DAG 图
神经网络是非线性模型
如下图

主流神经网络特点
以层(而不是以节点)为基本单位
一个输入层、多个变换层(也叫隐层)、一个输出层,一层接一层串行
每层由若干个并行的神经元模型组成
同一层的神经元使用相同的变换函数 ,使用不同的权值 和偏移量
所以程序的实现是以层为基本单位而不是节点
每个神经元的输入是上一层所有神经元的输出
假设上一层第一个神经元输出 ,第 n 个输出
则下一层第 j 个神经元输出为
每个神经元的输出会同时作为下一层所有神经元的输入
输入层的神经元个数等于样本数据 X 的维度
且不用加权求和及偏移
只需变换,比如每条输入数据为
则输入层需 n 个神经元,第 i 个神经元的输出为
输入层的变换函数通常取恒等变换 然后和第一个变换层合成一个输入层
输出层的神经元个数可以等于样本数据 Y 的维度,或是分类总数
one-hot representation:每次只有一个神经元输出 1 代表某类别,其余输出 0
可以在输出层后加一个损失层,或合并到输出层,用于反向传播算法的第一步
变换层不一定要有,甚至输出层也不一定要有,可以只有一层同时作为输入和输出
神经网络算法包含如下三个部分
通过将输入进行一层一层的变换来得到输出(前向传导算法)
通过输出与真值的比较得到损失函数的梯度(损失函数)
利用得到的这个梯度来更新模型的各个参数(反向传播算法)
前向传导算法(Forward Propagation,FP)
将输入进行一层一层的变换来得到输出
符号约定
第 i 层
第 i 层的神经元个数
第 i 层的变换函数(激活函数)
第 i 层的输入
第 i 层的输出
第 i 层和第 i+1 层之间的偏移量,为 维
第 i 层和第 i+1 层之间的权值矩阵,为 维
比如第 i 层 3 个节点,第 i+1 层 5 个节点
则 维度为 (3, 5), 维度为 (1, 5)
代表第 i 层第 n 个神经元和第 i+1 层第 m 个神经元之间的权值
代表第 i+1 层第 m 个神经元使用的权值向量
代表第 i+1 层第 m 个神经元使用的偏移量
计算输出
假设样本集为 (X,Y)
第 1 层 (输入层)
其中
X 是 (m, n) 矩阵,m 是样本数据量,n 是样本维度
通常取恒同映射 这样可以把输入层和第一个变换层合成一层
第 i 层 (包括输出层)
常见的激活函数及相应导数
逻辑函数 Sigmoid
正切函数 Tanh
线性整流函数 (Rectified Linear Unit, ReLU)
ELU 函数 (Exponential Linear Unit)
Softplus
恒同映射 (Identify)
Softmax
Softmax 被用于最后的输出层
用于多分类,每个节点的输出代表样本属于该分类的概率
可以看到对于一个样本,输出层所有节点的输出的和等于 1
激活函数的一个作用是实现去线性化
对应函数图
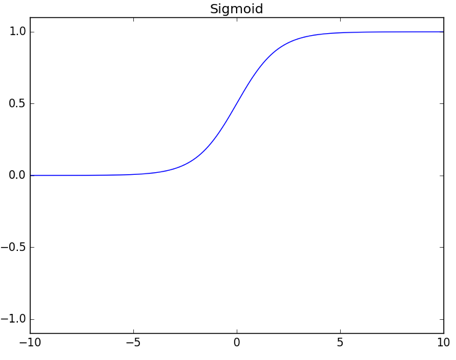

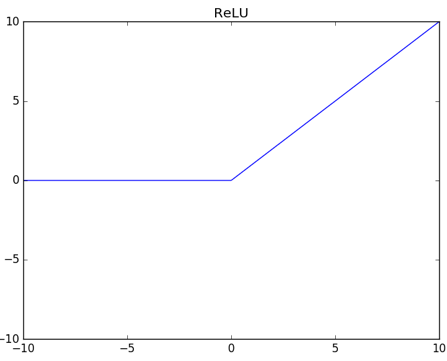

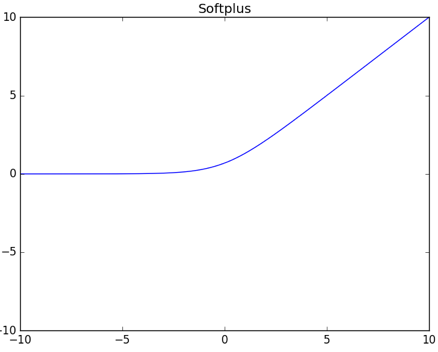
隐藏层激活函数的选择
激活函数作用是去线性
激活函数选择 ReLU 比较多,以前常用的 Sigmoid 效果也比较好
ReLU 优势:
计算简单、快
解决梯度消失问题
Sigmoid 的导数,在 x 偏大或偏小的时候会趋于 0,造成梯度消失
表现为靠近输出的神经元变化大,靠近输入的神经元变化慢甚至没有变化
ReLU 大于 0 的时候没这个问题
小于 0 的输入其输出都是 0,小于 0 的导数其结果也是 0
这种情况下,该神经元不会训练、不起作用,相当于产生稀疏矩阵
这样不同输入,起作用的神经元不同,可防止过拟合,不起作用、不训练同样防止梯度消失
ReLU 的变体
Leaky ReLU
Parametric ReLU
maxout 激活函数 (可学习的激活函数)
将神经元按若干个一组进行划分,每组只取最大值
注意 maxout 就是激活函数,就是说 WX + b 的结果不需要再变换,直接取一组结果的最大值
maxout 在训练出不同的 w 和 b 的情况下,其激活函数的函数图是不同的
作为比较, ReLU 不管训练出的 w 和 b 是什么值,其激活函数的函数图都是一样的
因为如此,所以称为可学习的激活函数
就是说激活函数是训练出来的 (Learnable Activation Function)
maxout 的缺点是模型比较复杂
ReLU 可以认为是一种特殊的 maxout
分组中,只有一个神经元的 W 和 b 有值,其他神经元的 W 和 b 都是 0
这样有值的神经元的输出大于 0 时就选该输出 (因为组内其他节点都是 0,此时 0 是小值)
有值的神经元的输出小于 0 时,就取 0 (因为组内其他节点都是 0,此时 0 是大值)
这就等效于 ReLU
输出层输出函数的选择
Softmax
如果是分类的话,那么最后一层通常用 Softmax
节点数是分类数,这样所有节点的总和是 1,节点输出是分类的概率
而且引入了指数可以拉开各节点差距
以前有加 SVM 的,现在多用 Softmax 不仅体现概率而且训练容易
Linear
如果是回归的话,最后一层通常用 Linear
就是 y=wx+b,不做其他转换,节点数通常是 1
损失函数(Cost Function/Loss Function)
假设把神经网络看做一个整体有 则有以下几种常见损失函数
距离损失函数 (MSE)
交叉熵 (Cross Entropy) 损失函数 (G(x) 每一位的取值都在 (0,1) 中,y 不是 1 就是 0)
以上是二分类的交叉熵,更一般性的 N 分类的交叉熵为
虽然是累加,但由于 y 只在一个分类上是 1,其他分类上是 0,所以每个输入其实只有一项有值
log-likelihood 损失函数
要求 G(x) 是一个概率向量,向量的每个值 代表 x 属于分类 k 的概率
该损失函数是样本的实际分类在预测结果中出现的概率的负对数
通常和 Softmax 激活函数配合使用
分类用的比较多的是交叉熵,通常配合输出层的 Softmax 使用
回归用的比较多的是距离损失函数
考虑到梯度下降法的应用,我们还期望,损失函数在函数值比较大时,它对应的梯度也比较大(亦即更新参数的幅度也要比较大)
对神经网络而言,梯度下降可谓是训练的全部,至今没能出现能与之抗衡的算法,最多只是研究出各式各样的梯度下降法的变体而已
反向传播算法 (Backpropagation, BP)
用于训练模型,利用梯度来更新结构中的参数以使得损失函数最小化,先从输出层开始,反向一层层更新
链式法则
设有
,
则有
注意
这里用的是点乘不是叉乘
如果是多元函数
则有
通过梯度调整参数
第 i 层的第 q 个神经元的输入和输出为
定义第 i 层的第 q 个神经元的局部梯度为
对最后一层(假设共 m 层)的第 q 个神经元和上一层的第 p 个神经元间的系数求导
其中
对 i 层的第 q 个神经元和 i-1 层的第 p 个神经元间的系数求导
其中
这里采用多元函数的链式法则,因为 和 之间是一对多的关系
将所有系数合起来用矩阵表达,结合梯度下降法,学习率为 ,对于 m 层网络有
其中
是 矩阵
是 矩阵
是 矩阵
是 矩阵
是 矩阵
以上是针对单个样本的
对于多个样本的同时计算有(这里的 还是 矩阵代表单个样本)
可以得到(这里的 改写为 矩阵代表多个样本)
其中
是样本数量
是 矩阵
是 矩阵
是 矩阵
是 矩阵
是 矩阵
np.sum
是借用 numpy 的写法,是对矩阵求和,这里求出的结果是 矩阵
axis=0
代表对第一个下标求和,即求
sum[0] = x[0][0] + x[1][0] + ... + x[m][0]
sum[1] = x[0][1] + x[1][1] + ... + x[m][1]
可以看到就是求列和
keepdims=True
代表保持原来维度,不然求和后会变成一维向量
可以看到,每一次前向传导算法出来结果后,就要从最后一层开始,通过反向传播算法更新系数
然后再进行前向传导算法,然后再反向传播更新系数,这样不断迭代得到最优参数
损失层 (CostLayer)
输出层后面可以再加一个损失层 CostLayer 作为 BP 算法的第一层
并且其 BP 算法和其他层不一样
损失层没有激活函数,但可能有特殊的变换函数 (比如说 Softmax)
需要定义某个损失函数
定义导函数时,需要考虑到自身特殊的变换函数并计算相应的、整合后的梯度
可以把损失层和输出层合并,把损失层同时作为输出层使用
损失函数的选择
对于固定的损失函数,有相对适合它的激活函数,结合激活函数来选择损失函数是一个常见的做法
用得比较多的组合有以下四个
Sigmoid 系以外的激活函数 + 距离损失函数(MSE)
因为 Sigmoid 系激活函数会引起梯度消失的现象,既梯度容易趋向于 0
MSE 这个损失函数无法处理这种梯度消失
可以看到,由于 取 0 和 1,而 是趋向于 0 和 1
当这两个值不一致的时候也就是需要调整参数时,梯度会趋向 0,所以这种组合不能用
Sigmoid + Cross Entropy
Cross Entropy 能解决 Sigmoid 的梯度消失问题
可以看到当 和 不一致时梯度趋向 1 或 -1
Softmax + Cross Entropy / log-likelihood
log-likelihood 会导致训练无法收敛,需要改进,改进后和 Cross Entropy 本质上是一样的
特殊的层结构(SubLayer)
有一类特殊的 Layer 它们不会独立存在,而是附在某个 Layer 后以实现某种特定功能,称为 SubLayer
SubLayer 是为了对 Layer 的输出进行变换,目的是为了优化输出
SubLayer 可以有多个相连,最前面的 Layer 又称为 Root Layer,最后一个 SubLayer 又称为 Leaf Layer
SubLayer 的行为大体上可以概括如下:
在前向传导中,它会根据自身的属性和算法来优化从父层处得到的更新
在反向传播中,它会有如下三种行为:
SubLayer 之间的关联不会被更新
SubLayer 本身可能会有参数,可能会被 BP 算法更新,但影响域仅在该 SubLayer 的内部
Layer 之间关联的更新通过 Leaf Layer 完成,i 层的 Leaf 用 i 层的激活函数完成局部梯度的计算
典型的 SubLayer 有 Dropout 和 Normalize
Dropout
核心思想在于提高模型的泛化能力
它在每次迭代中依概率去掉 Layer 的某些神经元,从而每次迭代训练的都是一个小的神经网络
Normalize
核心思想在于把父层的输出进行归一化
从而期望能够解决由于网络结构过深而引起的梯度消失等问题
优化器(Optimizer)
在众多深度学习框架中,参数更新过程常被单独抽象成若干个模型,这些模型称为优化器
优化器主要对梯度的计算进行优化
优化的算法和梯度下降法类似,区别可以概括如下两点:
更新方向不是简单地取为梯度
学习速率不是简单地取为常值
优化器的框架应该包括如下三个方法:
接收欲更新的参数并进行相应处理的方法
利用梯度和自身属性来更新参数的方法
在完成参数更新后更新自身属性的方法
这里要讲的优化器属于最朴素的优化器:根据算法与梯度来更新相应参数
比较优秀的算法在每一步迭代中计算梯度时都不是独立的,而会利用上以前的计算结果
以 代表原始梯度,以 代表优化后的梯度
Vanilla Update
Vanilla 是朴实平凡的意思,既和最普通的梯度下降一样
在实际实现中,Vanilla Update 通常以小批量梯度下降法(MBGD)的形式出现
Momentum Update
设想:
将损失函数的图像想象成一个山谷,我们的目的是达到谷底
将损失函数某一点的梯度想象成该点对应的坡度
将学习速率想象成沿坡度行走的速度
Vanilla Update 会出现前一秒还在以很快的速度往左走,下一秒突然以很快的速度往右走
这种行进模式之所以违背直观,是因为没有考虑到惯性
Momentum Update 通过尝试模拟物体运动时的惯性以期望增加算法收敛的速度和稳定性
其优化公式为:
其中
为动力
为第 t-1 步的速度
为惯性, 初始化为 0.5 并逐步加大至 0.99,相当于越接近谷底越要减少动力
Nesterov Momentum Update
在凸优化问题下的收敛性会比传统的 Momentum Update 要更好
核心思想在于想让算法具有前瞻性
它会利用下一步的梯度而不是这一步的梯度来合成出最终的更新步伐
RMSProp
Momentum 系算法通过搜索更优的更新方向来进行优化
RMSProp 则是通过实时调整学习速率来进行优化
计算公式比较复杂
是从算法开始到当前步骤的所有梯度的某种“累积”
是衰减系数,越早的梯度对当前梯度的影响越小
Adam
Adam 算法是应用最广泛的,一般而言效果最好,它高效、稳定、适用于绝大多数应用场景
一般来说如果不知道该选哪种优化算法的话,使用 Adam 常常会是个不错的选择
计算公式比较复杂,很像是 Momentum 系算法和 RMSProp 算法的结合
如何选择网络大小
将样本数据随机的划分为训练集 (假设占 80%)、测试集 (假设占 20%)
常用模型比如:
3 层每层 30 节点、3 层每层 40 节点、3 层每层 50 节点、4 层每层 30 节点、4 层每层 40 节点、......、5 层每层 50 节点
选择全部常用模型,或随机挑选几个常用模型,然后选择在测试集表现最好的那个模型使用
神经元总数相同的情况下,层数多的,比层数少的,更容易训练,准确率更高
参数和超参数
参数指的是 W 值,和 b 值等,需要靠学习获得
超参数
- 层数和每层神经元数:在固定组合中,随机挑选若干个训练,或者挑选全部进行训练,然后选择效果好的
- 激活函数:隐藏层多用 ReLU,输出层如果是分类多用 Softmax,如果是回归多用 Linear
- 损失函数:分类多用交叉熵,回归多用 MSE
- 学习率:迭代时 W 变化的速度,,比如 0.01、0.1、0.5、1.0 等等,一般在 0.01 到 0.1 之间,学习率太大会导致 W 变化太快容易错过最佳值,学习率太小会导致 W 变化太慢需要更多的迭代次数才能起作用,有的算法会在每执行多少次迭代后,减小学习率
- 正则化系数:如果一味使损失函数最小,有可能导致模型太复杂,出现过拟合的情况,为了防止这种情况,引入了正则化项,即目标函数不只是损失函数,而是损失函数加正则化项,正则化项通常是 W 的和,或是 W 的平方和再求平方根,即 ,通常 L 越小 J 会越大,通过调整正则化系数 来控制正则化项的影响
- 迭代次数
- mini-batch 大小:防止一次迭代训练太多数据,内存可能会爆,通过设置 batch 大小,比如 64、128、256 等,这样每次迭代,都是分批取数据,直到样本数据取完,一次迭代完成
超参数需要在训练前就指定好,训练时不会变化
提高效果的一些方法
- 数据增强:比如,一张猫的图片,截除多张包含猫的图片,有的包含整只猫,有的只有猫头,有的只有猫身,做翻转,换色,等等,增强数据的多样性
- 数据预处理:比如归一化 (标准归一化、缩放归一化、PCA),防止有的特征数值比较大而有的特征数值比较小造成只有数值大的特征在其作用,比如剔除异常数据
- 自适应学习率
- 正则化,防止模型太复杂
- 增加 Dropout Sublayer,它在训练的每次更新 W 值的时候,依概率去掉 Layer 的某些神经元,提高模型的泛化能力,每个 mini batch 会重新采样 (即重新认为所有神经元都需要,然后每次计算再重新随机去掉),但实际上每个 W 值都还在,只是计算的时候被随机跳过而已,测试的时候不会跳过任何神经元,并且会把 W 值变大,如果 W 被去掉的概率是 0.1,那么测试时用的值就是 0.9 * W (这里 W 是训练集训练出来的)
- 增加 Normalize Sublayer,把父层的输出进行归一化
- early-stop,训练集的准确度,必然是随着迭代次数的增加而提高的,但测试集就不一定,early-stop 就是在测试集的准确度无法再提高,或者是准确度开始下降的时候,就停止迭代
也可能是新的算法,比如使用新的更好的激活函数
代码思路
主要的函数有
# 添加新的层
def add(self, layer)
# 训练,使用反向传播算法(bp),指定学习率,迭代次数,优化器
def fit(self, x, y, lr=None, epoch=None, optimizer=None)
# 预测,使用前向传导算法
def predict(self, x)
使用
# 初始化神经网络
nn = NN()
# 添加输入层,需要指定输入维度和输出维度,输入维度就是 x 的维度
nn.add(ReLU((x.shape[1], 24)))
# 添加变换层,只需要指定输出维度,输入维度就是上一层的输出维度
nn.add(ReLU((24, )))
# 添加损失层,同时作为输出层,输出维度就是 y 的维度,指定损失函数和变换函数
nn.add(CostLayer((y.shape[1],), "CrossEntropy", "Softmax"))
# 训练,步长 0.01,迭代 1000 次,选用 Adam 优化器
nn.fit(x, y, lr=0.01, epoch=1000, optimizer="Adam")
# 预测新数据的值
nn.predict(x_new)
分批思想
数据量大时容易引发内存不足,可以考虑分批处理,这里的分批不是指并行分布式,而是一次取一部分数据处理
计算过程会产生中间数据,比如 100 条数据可能产生 10000 条中间数据,数据量大了内存可能不够,如果每次只处理 10 条数据,只产生 1000 条数据,对内存的要求就小了,处理下一批时内存又释放了出来
训练过程
for counter in range(epoch):
for _ in range(train_repeat): # 每次迭代都将输入数据 x 分多批次完成
# 训练部分数据
预测过程
while count < len(x): # 每次预测一批 x 而不是一次性全预测
count += single_batch
if count >= len(x):
rs.append(self._get_activations(x[count - single_batch:]).pop())
else:
rs.append(self._get_activations(x[count - single_batch:count]).pop())
梯度消失
随着网络层数增加,可能会出现梯度消失现象
BP 反向传播梯度时,每传递一层,梯度都会衰减,那么层数一多,梯度就会消失,将无法有效训练参数
解决方法包括使用 ReLU,ELU 等激活函数,使用 Normalize SubLayer 进行归一化等等
矩阵算法的优势
- 算法有优化
- 硬件层面有特殊的向量运算指令
- 可以实现并行计算
样本数据就是一个矩阵,比如 N 个样本,每个 M 个特征,那就是 N*M 矩阵,直接可以一次性计算
应用代码例子
import matplotlib.pyplot as plt
from tensorflow.keras import datasets
from tensorflow.keras import models
from tensorflow.keras import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.layers import Flatten
# 导入样本数据
# 包、衣服、鞋等图片,60000 测试集,10000 训练集 (mnist 是 0~9 的数字图片,但有点简单,所以换成 fashion_mnist)
# 大小是 28*28
# 共 10 个分类
(train_x, train_y), (validation_x, validation_y) = datasets.fashion_mnist.load_data()
# 归一化
train_x = train_x / 255.0
validation_x = validation_x / 255.0
# 显示图片,可以看到是一个包
plt.figure()
plt.imshow(train_x[100])
plt.colorbar()
plt.grid(False)
plt.show()
# 创建模型
model = Sequential()
model.add(Flatten(input_shape=[28, 28])) # 将图片拍平成一维数据
model.add(Dense(32, activation='relu')) # 第一个神经层,32 个节点,激活函数是 ReLU
model.add(Dense(32, activation='relu')) # 第二个神经层,32 个节点,激活函数是 ReLU
model.add(Dense(10, activation='softmax')) # 输出层,10 个节点,因为有 10 个分类,激活函数是 softmax
# Dense 还有很多其他参数比如 kernel_regularizer,use_bias 等等
# 如果输入是一维数据,那么代码应该是
# model = Sequential()
# model.add(Dense(32, activation='relu', input_dim=784)) # 第一个神经层要指定输入的维度 28*28 = 784
# model.add(Dense(32, activation='relu'))
# model.add(Dense(10, activation='softmax'))
# 如果要加 sublayer 比如 dropout,可以这样
# from tensorflow.keras.layers import Dropout
# model.add(Dropout(0.5))
# 可以把模型画出来
# sudo apt-get install graphviz
# sudo pip install graphviz
# sudo pip install pydot_ng
# from tensorflow.keras.utils import plot_model
# plot_model(model)
# 创建模型时,也可以写成下面这种格式
# model = Sequential(
# [
# Flatten(input_shape=[28, 28]),
# Dense(32, activation='relu'),
# Dense(32, activation='relu'),
# Dense(10, activation='softmax')
# ])
# 编译模型,指定损失函数,优化器,也可以使用自己自定义的函数
# 这里的损失函数是交叉熵 sparse_categorical_crossentropy,也可以用 categorical_crossentropy
# 区别是前者不用 one-hot,后者用 one-hot,只是内部实现的区别
# metrics 表示如何衡量模型准确度,accuracy 表示真实值和预测值都是一个数字,还有其他类型
# 比如 categorical_accuracy 表示真实值是 one-hot 比如 [1, 0, 0] 而预测值是向量比如 [0.6, 0.3, 0.1]
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
# 训练
# 指定训练集和测试集
# 迭代 5 次 (计算完所有 60000 张图片算一次迭代),每次计算最多用 100 张照片 (600次计算完成一个迭代)
model.fit(train_x, train_y, epochs=5, batch_size=100, validation_data=(validation_x, validation_y), verbose=1)
# 把模型有多少层,每层几个节点,多少参数,给打印出来
model.summary()
# 获取测试集的损失值,和准确度
loss, accuracy = model.evaluate(validation_x, validation_y, verbose=0)
# 预测
# 必须指定数组,如果只预测一个应该用 model.predict(validation_x[0:1])
result = model.predict(validation_x[0:100])
# 结果是 (100, 10) 表示有 100 个结果,每个值是一个 10 个值的列表表示属于不同分类 (共 10 个) 的概率
print(result.shape)
# 取第一个结果,可以看到属于最后一个分类的概率最大
# [1.54234713e-05 8.47201420e-08 7.35944195e-06 1.41576163e-06
# 3.19953301e-06 1.59782887e-01 2.61375098e-05 1.20886475e-01
# 4.77397395e-03 7.14502990e-01]
print(result[0])
# 保存模型
model.save('my_model')
# 读取模型
my_model = models.load_model('my_model')
这是比较简单的例子
实际中数据的预处理也是比较花时间的工作
神经网络小结
基本单位是层 (Layer),它是一个非常强大的多分类模型
每一层都会有一个激活函数,它是模型的非线性扭曲力
通过权值 w 和偏置量 b 连接相邻两层,其中 w 将结果线性映射到新的维度空间,b 则能打破对称性
通过前向传导算法获取各层的激活值
通过输出层的激活值和损失函数来计算损失,以及输出层的局部梯度
通过反向传播算法算出各层的局部梯度并用各种优化器更新参数 w 和 b
合理利用一些特殊的层结构能使模型表现提升
当任务规模较大时、就需要考虑内存等诸多和算法无关的问题了
各种神经网络
前反馈神经网络 (Feedforward Neural Network, FNN)
信息由输入层到输出层向前单向流动,误差由输出层到输入层后向传递,这就是 FNN
有时也叫 BP 神经网络(Back Propagation Neural Network)
CNN 也是 FNN 的一种
RNN 则不是
全连接神经网络 (Fully Connected Neural Network)
每个节点的输出会被下一层的所有节点当作输入
每个节点的输入会使用上一层的所有节点的输出
既前后两层的所有节点都连接起来
前面介绍的神经网络就是全连接神经网络,CNN、RNN 则不是
卷积神经网络 (Convolutional Neural Network, CNN)
全连接网络容易导致参数太多,尤其用于处理图像时
全连接网络把图片数据转成一维的话也可以处理,但效果比较差,不如 CNN
卷积神经网络在全连接网络的基础上增加了卷积层,卷积层的计算函数称为卷积核
卷积神经网络接受多维数据
比如一副 5x4 的图片,假设 RGB 占 3 位,全连接神经网络必须将其转为 (1,60)
而卷积层则直接接受多维数据 (3,4,5),通常认为这是 3 个频道,每个频道是一个 (4,5) 二维数据
卷积核输出维度为 (m,n) 的数据,每个数值只使用上一层的所有频道的部分数据进行计算
使用 k 个卷积核最终输出维度为 (k,m,n) 的数据,k 个卷积核被认为提取了 k 个特征
这里说的卷积和数学上的卷积不是一个意思
最后还是要连接普通的全连接网络,因为卷积层只用于提取特征,实际上后面用其他算法也可以
训练过程与全连接神经网络基本一致
循环神经网络 (Recurrent Neural Network, RNN)
全连接网络还存在另一个问题:无法对时间序列上的变化进行建模
然而样本出现的时间顺序对于自然语言处理、语音识别、手写体识别等应用非常重要
在 RNN 中,神经元的输出可以在下一个时间戳直接作用到自身
即第 i 层在 m 时刻的输入,除了 i-1 层在该时刻的输出外,还包括其自身在 m-1 时刻的输出
长短期记忆网络 (Long Short-Term Memory, LSTM)
RNN 可看成一个在时间上传递的神经网络,它的深度是时间长度,会在时间轴上出现梯度消失现象
对于 t 时刻来说,它产生的梯度在时间轴上传播几层之后就消失了,这种影响只能维持若干个时间戳
为了解决时间上的梯度消失,LSTM 通过门的开关实现时间上记忆功能,并防止梯度消失
深层神经网络 (Deep Neural Network, DNN)
广义上来说,神经网络,多层神经网络,深层神经网络指的是同一个东西
狭义上来说,DNN 有时特指全连接神经网络,不包括 CNN,RNN
一般都理解为广义上的意思
深度学习 (Deep Learning, DL)
维基百科:通过多层非线性变换对高复杂性数据建模算法的合集
一般通过激活函数实现去线性化
由于深层神经网络是多层非线性变换的一种常用方法,很多时候深度学习就是指深层神经网络
这里的深度并没有固定的定义
在语音识别中 4 层网络就能够被认为是较深的,而在图像识别中 20 层以上的网络屡见不鲜
深层神经网络比浅层神经网络的优势
打个比方,给一幅图片,上面有一只猫和一张椅子,要求进行识别
浅层神经网络(假设只有一层)
相当于直接把所有信息抽象成猫和椅子
深层神经网络
相当于有多次的提取特征、多次的进行抽象,比如
第一层,从图像中识别出线条
第二层,从线条中识别出图形
第三层,从简单的图形中识别出两个更复杂的图形
第四层,识别出这两个图形分别是猫和椅子
深层神经网络例子
2012 AlexNet 8 layer Error Rate 16.4%
2014 VGG 19 layer Error Rate 7.3%
2014 GoogleNet 22 layer Error Rate 6.7%
2015 ResidualNet 152 layer Error Rate 3.57%
ResidualNet 能更深是因为用了残差网络,后面章节再讲


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 提示词工程——AI应用必不可少的技术
· 地球OL攻略 —— 某应届生求职总结
· 字符编码:从基础到乱码解决
· SpringCloud带你走进微服务的世界