

机器学习:支持向量机(SVM)
优点:泛化错误率低,计算开销不大,结果易解释
缺点:对参数调节和核函数的选择敏感,原始分类器不加修改仅适用于处理二分类问题
线性可分
- 给定一个二维数据集,如果可以用一条直线,将数据分成两类,在直线的一边都是一种分类,另一边的都是另一种分类,我们说这个数据集线性可分
- 该直线称为分隔超平面(Separating Hyperplane),也就是分类的决策边界
- 同理对 N 维数据集,如果存在可对数据进行分类的 N-1 维超平面,我们说该数据集线性可分
- 采用这种方式来构建分类器,如果数据点离决策边界越远,那么其最后的预测结果也就越可信
支持向量
- 数据集可能存在多个可用于分类的超平面
- 我们希望找到离分隔超平面最近的点,确保它们离分隔面的距离尽可能远
- 符合这个条件的超平面鲁棒性(Robust)最好,对未知数据的分类准确性高
- 在这里距离又被称为间隔(Margin)
- 离分隔超平面最近的那些点就是支持向量(Support Vector)
- SVM(Support Vector Mechine)就是要最大化支持向量到分隔面的距离
寻找最大间隔
下图以有两个特征的二维数据为例子
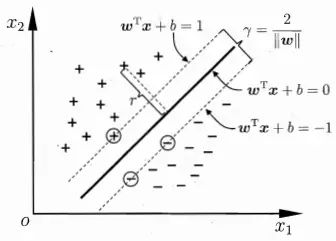
离分割超平面最近的点就是支持向量,对于最佳分割超平面而言,两边的支持向量到分割超平面的距离是相等的,并且该距离等于过支持向量且与分割面平行的面到分割面的距离
分隔超平面可表示为
可表示为
或
平行面的 系数有相同的比例,所以两个平行面可表示为
对平面的 , 系数进行同比例的缩放,表示的依然是同一个平面,所以可改写为
由于平面等距,所以有
进一步改写为
三个方程都除以 得到
将 , 改用 , 表示,最终得到
之所以取 1 是为了方便计算距离,平行线 和 的距离为
所以这三个面的距离可表示为
满足 的分类记为
满足 的分类记为
由于样本数据最近的点在 上,样本数据可以进一步表示为
满足 的分类记为
满足 的分类记为
这样 SVM 的训练过程就是要寻找合适的 和 以满足
max
s.t. , (s.t. 是约束条件的意思)
max 等价于 min (取为 和平方的目的是为了后面方便求解)
所以优化目标又可以写为
min
s.t. ,
拉格朗日乘数法
给定函数 和约束条件 ,为求解函数极值,构建拉格朗日函数
对 和 求导并令导数等于 0 即
求出的 带入 可得到极值
如果约束条件是不等式
只要满足 KKT 条件(这里不推导了)也可以用拉格朗日数法
于是前面的优化目标的拉格朗日函数为
对 和 求导并令导数等于 0
将结果带入 可得
s.t. ,
s.t. ,
求出 后,将 代入 得到点 的值为
或者
其中
和 是 (n,1) 矩阵
是 (n,m) 矩阵,是样本数据集
是 (1,m) 矩阵,是要求解的一条数据
到此为止都是假设数据线性可分,考虑到数据不一定完全线性可分的时候,可以引入一个常数限制 ,允许部分数据划分错误,即 的约束条件变为
s.t. ,
s.t. ,
可以使用通用的二次规划算法求解 的值,但这会造成很大的开销,为了简化计算,人们提出了很多高效算法,SMO 是一个著名代表
SMO(Sequential Minimal Optimization,序列最小优化)
SMO 将大优化问题分解为多个小优化问题,这些小优化问题往往很容易求解,并且对它们进行顺序求解的结果与将它们作为整体来求解的结果是一致的,而 SMO 算法的求解时间短很多
基本思路是先取两个值 和 做变量,然后固定其他 值,由于只有两个变量所以很容易优化,然后再继续取下一对 值,照同样的方法优化,就这样不断迭代,直到无法再优化,或者达到最大迭代次数
由 可以得到,当固定一组 以外的其他值时,有
其中
为常数
以 和 为例子,因为其他 值被当做常数,可以将优化目标中除 和 外的项去掉(因为常数无法优化)
所以原优化目标
等价于
再用 代入得到
注意有 以及 ,对 求导得到
令导数为 0 得到
这过程中,代入 和 时用到的 (即等式右边用的)是旧的
可以得到优化后的值为
然后计算优化后的
得到优化值后,继续取下一对 值进行优化
考虑到 和 的限制,在优化的过程中, 值是受到限制的
当 和 异号,比如 , 时,有
当 或 时
由于有 ,该式子无解
当 时
的取值范围在
当 时
的取值范围在
可以看到 的取值范围是
即有 的取值范围是
同理可求得 和 同号时
接下来求 值
由 可以反推
If: ,通过第一个点计算
又有
elif: ,通过第二个点计算
else :
或者是 0 或者是 则
分类预测
前面已经给出了公式,这里再总结一下
或者
或者
对应的 就是支持向量(??)
简化版 SMO 代码
# coding=utf-8
import numpy as np
def selectJrand(i, n):
"""
在 (0, n) 之间随机选择一个不等于 i 的 值
"""
j = i
while j == i:
j = int(np.random.uniform(0, n))
return j
def clipAlpha(aj, H, L):
"""
限制 aj 的值在 L 和 H 之间
"""
if aj > H:
aj = H
if L > aj:
aj = L
return aj
def smoSimple(dataMatIn, classLabels, C, toler, maxIter):
"""
dataMatIn - 样本数据集,(n, m) 维数组,n 是样本数,m 是特征数
classLabels - 标签,(1, n) 维数组,取值为 1 或 -1
C - 使 C > a > 0,以处理不 100% 线性可分的情况,加上 C 的限制后不会一直增加 a 值,同时允许部分数据错分
toler - 能容忍的误差范围
maxIter - 迭代次数
"""
# 样本转为 numpy 矩阵
dataMatrix = np.mat(dataMatIn)
labelMat = np.mat(classLabels).transpose()
# 样本数,特征数
n, m = np.shape(dataMatrix)
# 初始化 a 和 b 为 0
b = 0
alphas = np.mat(np.zeros((n, 1)))
# 如果连续 maxIter 迭代 a 值都没改变就跳出
# 如果 a 值有变化要重新计算迭代次数
iter = 0
while iter < maxIter:
alphaPairsChanged = 0
# 遍历每个样本
for i in range(n):
# f = WX + b
# = (a . y)^T * (X * x^T) + b
fXi = float(np.multiply(alphas, labelMat).T * (dataMatrix * dataMatrix[i, :].T)) + b
# 计算误差
Ei = fXi - float(labelMat[i])
# 误差偏大,看能不能优化 a 值
if (labelMat[i] * Ei < -toler and alphas[i] < C) or (labelMat[i] * Ei > toler and alphas[i] > 0):
# 随机选择另一个样本
j = selectJrand(i, n)
# 计算误差
fXj = float(np.multiply(alphas, labelMat).T * (dataMatrix * dataMatrix[j, :].T)) + b
Ej = fXj - float(labelMat[j])
# 保存对应的 a 值
alphaIold = alphas[i].copy()
alphaJold = alphas[j].copy()
# 计算优化后的 a2 的取值范围
if labelMat[i] != labelMat[j]:
L = max(0, alphas[j] - alphas[i])
H = min(C, C + alphas[j] - alphas[i])
else:
L = max(0, alphas[j] + alphas[i] - C)
H = min(C, alphas[j] + alphas[i])
if L == H:
# 无法优化
print "L == H"
continue
# a2-new = a2-old - y2(E1-E2)/(2 * x1 * x2^T - x1 * x1^T - x2 * x2^T)
# = a2-old - y2(E1-E2)/eta
eta = 2.0 * dataMatrix[i, :] * dataMatrix[j, :].T \
- dataMatrix[i, :] * dataMatrix[i, :].T \
- dataMatrix[j, :] * dataMatrix[j, :].T
if eta >= 0:
# 无法优化
print "eta>=0"
continue
# 优化 aj
alphas[j] -= labelMat[j] * (Ei - Ej) / eta
# 限制 aj
alphas[j] = clipAlpha(alphas[j], H, L)
if abs(alphas[j] - alphaJold) < 0.00001:
# 没优化
print "j not moving enough"
continue
# 优化 ai
# a1-new = a1-old + y1*y2*(a2-old - a2-new)
alphas[i] += labelMat[j] * labelMat[i] * (alphaJold - alphas[j])
# 计算 b 值
b1 = b - Ei \
- labelMat[i] * (alphas[i] - alphaIold) * dataMatrix[i, :] * dataMatrix[i, :].T \
- labelMat[j] * (alphas[j] - alphaJold) * dataMatrix[i, :] * dataMatrix[j, :].T
b2 = b - Ej \
- labelMat[i] * (alphas[i] - alphaIold) * dataMatrix[i, :] * dataMatrix[j, :].T \
- labelMat[j] * (alphas[j] - alphaJold) * dataMatrix[j, :] * dataMatrix[j, :].T
if (0 < alphas[i]) and (C > alphas[i]):
b = b1
elif (0 < alphas[j]) and (C > alphas[j]):
b = b2
else:
b = (b1 + b2) / 2.0
# 优化次数
alphaPairsChanged += 1
print "iter: %d i:%d, pairs changed %d" % (iter, i, alphaPairsChanged)
if alphaPairsChanged == 0:
# 到这里说明遍历了整个数据集都没能优化
# 但由于第二个样本是随机的,所以可以继续迭代,可能还是可以优化
# 其实这里的代码还可以优化,如果每次的第一个样本就决定优化不了,那到这里就没必要继续迭代了
# 而且这里不应该完全依赖迭代次数达成,应该有其他条件比如误差小到一定程度就可以停止计算
iter += 1
else:
# 有优化,重新计算迭代次数
iter = 0
print "iteration number: %d" % iter
return b, alphas
def calcWs(alphas, dataArr, classLabels):
"""
计算 W 系数
"""
X = np.mat(dataArr)
labelMat = np.mat(classLabels).transpose()
m, n = np.shape(X)
w = np.zeros((n, 1))
for i in range(m):
w += np.multiply(alphas[i]*labelMat[i], X[i, :].T)
return w
完整版 SMO
- 简化版 SMO 运算速度慢
- 接收参数一样
- 对 alphas 的更改运算一样
- 对第二个 alphas 的选择不一样,简化版是随机的,完整版复杂一点
- 外循环最多循环一次,不会出现重置 iter 的情况,而且两次迭代如果 alphas 都没有优化就会跳出外循环
核函数
- 有的数据是非线性可分的,比如某些二维数据无法用直线划分而是用圆划分
- 可以将数据从原始空间映射到更高维度的特征空间(比如讲二维数据映射到三维空间),使得数据在这个新的特征空间内线性可分
- 对于有限维空间,一定存在这样一个高维空间使得数据线性可分
- 用于映射的函数就被称为核函数,很多其他的机器学习算法也都用到核函数
- 假设映射后的特征向量为 ,则划分超平面表示为
- 参数的推导过程和 SMO 一样
高斯核函数
径向基函数是 SVM 中常用的一个核函数。
径向基函数是一个采用向量作为自变量的函数,能够基于向量距离运算输出一个标量。
径向基函数的高斯版本的高斯版本,函数为
其中
表示自然数 的指数
是函数值跌落到 0 的速度参数
该函数将数据映射到更高维的空间
具体来说是映射到一个无穷维的空间(不理解,貌似是按泰勒展开的话有无穷维)
优化的目标函数由
改写为
训练过程和前面的 SMO 一样,推导过程中的 改为 就可以
高斯核函数计算
def kernel(X, omiga):
"""
用高斯核函数对样本数据 X 转换
X 是二维矩阵
返回矩阵 K
K(i, j) = exp(-(||Xi - Xj||**2)/(2 * (omiga**2)))
"""
m, n = np.shape(X)
K = np.mat(np.zeros((m, m)))
for i in range(m):
for j in range(m):
# 计算 ||Xi - Xj||**2
deltaRow = X[j, :] - X[i, :]
d = deltaRow * deltaRow.T
K[i, j] = np.exp(d / (-2 * omiga ** 2))
return K


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 提示词工程——AI应用必不可少的技术
· 地球OL攻略 —— 某应届生求职总结
· 字符编码:从基础到乱码解决
· SpringCloud带你走进微服务的世界