
BUAA-OO第三单元总结
JML与测试数据构造思路
jml学习和阅读心得
完成第三单元的最基本要求,就是我们需要能够理解和高效地阅读jml、理解任务的需求。
-
-
jml的阅读中主要的难点在于对于语法的理解和多层嵌套括号的处理。
-
语法理解是jml阅读的基础,对语法理解的偏差会导致不可预料的后果、而且很难debug发现。例如在我第三单元第二次作业建立最小生成树并求其权重的时候,因为对于/forall语句的理解不准确,导致在计算的时候忽略了还需要考虑边的权重的问题。
-
多层括号处理:多层括号切忌全靠脑子硬看…在处理多层括号的层级关系时很容易出问题,所以可以借助编辑器的帮助,将jml注释先复制到一个新建的文件中,将注释符号删掉之后,把每层括号结构之间使用比较明显的缩进分割,凸显层级关系。
相关工具
在我们oo课程的作业和未来的工作中,版本迭代都难以避免。在每次迭代里面,如何才能快速识别或大或小、分布在各个角落的修改,是我们必须面对和解决的一个问题。
这一点体现的比较明显的是第三个单元的作业。在第三单元的三次代码作业中,jml都提出了不同的需求,每次迭代不仅新增了新的方法,而且对之前已经实现了的方法也有了更多的功能要求。我就是在迭代过程中,写到一半才发现,“欸这个方法这次作业中的行为怎么和上次要求的不一样”,才发现是方法的内部实现也发生了迭代。
通过 Compare With Clipboard,在你发现想要对比的代码之后,可以直接在代码中右键点击,然后选择“compare with clipboard”,就可以进入对比界面。在对比界面中,你可以自己选择进行对比的两个文件。
测试数据构造思路
本次我主要采用的是黑盒测试、大数据量随机生成数据和人脑构造测试点结合的方式。
人脑构造测试点,有一个比较严重的问题是。如果我们在设计代码的时候没有考虑到某种特殊的情况,那么在构造手动测试的过程中也大概率难以测试到这个盲点。
因此,就需要借助大量的自动生成数据来弥补这个缺失。
自动生成数据的思路
-
简单版:(以am和sm为例)
def add_message():
a = random.randint(-MAXN, MAXN)
b = random.randint(-MAXN, MAXN)
c = random.randint(0, 1)
d = random.randint(-MAXN, MAXN)
if c == 0:
e = random.randint(-MAXN, MAXN)
else:
e = random.randint(-MAXM, MAXM)
s = 'am {} {} {} {} {}\n'.format(a, b, c, d, e)
def send_message():
a = random.randint(-MAXN, MAXN)
s = 'sm {}\n'.format(a)
std_in.append(s)
这种生成方式有一个问题,就是大多数生成的指令都会被当作exception,所以实际覆盖到的测试情况是比较少的。
所以如果希望测试的效果更好,就需要一些更加完善的体系来进行测试
-
通过person_pool、relation_pool等实现id的生成和选择通过instrSet统计和判断指令的生成等等。
以person_pool为例,我们将ap指令生成的person的id作为index,将person的其他属性存到person_pool中。
之后,在ar指令中,我们可以一一定的比例从person_pool中随机选取某个person作为关系连接的人。
等等。
-
通过参数选择的不同模式的评测,每个模式针对不同的测试数据生成比例,有针对性的测试某一个或几个比较薄弱或容易出问题的测试点。但是这个我最后没有实现,因为时间比较紧张。
正确性评测的思路
使用python进行对拍
p.s.:使用评测机一定要慎重、评测的结果也仅供参考……这单元可以说被评测机坑的挺惨的。之前几个单元大部分采用了手动评测,这单元希望能通过评测机的方式提升性能的同时学习一下自动评测的思路和技术。结果就是太过于相信评测结果,导致强测分一次比一次低,太惨了太惨了。要是拿出一部分评测机的时间来有针对性地构造测试数据,效果应该会好很多。
算法性能分析和改进
架构和容器
在前两个单元的任务中,因为刚刚接触java,所以使用的容器大多为ArrayList。
但在本单元中,有大量需要通过id进行检索的操作,而如果继续采用ArrayList加循环遍历的方式进行检索,就会发生不太好的事情,比如在强测和互测中被CTLE。
所以本次作业我采用了尽量多地的HashMap + 维护变量的方式,以提升性能。
算法分析
并查集
本单元第一次作业采用的主要算法。很简单,但是也很强
public int getFather(int idTmp) {
int id = idTmp;
int root = id;
while (root != pre.get(root)) {
root = pre.get(root);
}
while (root != id) {
int tmp = pre.get(id);
pre.replace(id, pre.get(id), root);
id = tmp;
}
return root;
}
public void merge(int id1, int id2) {
int f1 = getFather(id1);
int f2 = getFather(id2);
pre.remove(f1);
pre.put(f1, f2);
}
public boolean connected(int id1, int id2) {
int f1 = getFather(id1);
int f2 = getFather(id2);
return f1 == f2;
}
并查集主要应用于queryCircle这个方法的实现。只要将判断的对象使用connected进行判断两者的father节点是否相同即可。
看其他同学还有人使用这个方法维护queryBlockSum,直接在merge的时候 - 1,add的时候 + 1即可。也是很巧妙的方法,当时我没有想到。
Kruskal算法最小生成树
query_least_connection指令的要求是查询图中包含某个点的最小生成树的权重和。
public int kruskal(int id) {
int result = 0;//结果
edgeSet.clear();
father.clear();
edges.forEach(edge -> {
if (connected(edge.getId1(), id)) {
edgeSet.add(edge);
father.put(edge.getId1(), edge.getId1());
father.put(edge.getId2(), edge.getId2());
}
});
//System.out.println("person number is " + personNum);
edgeSet.sort(Edge::compareTo);
int nedge = 0;
for (int i = 0; i < edgeSet.size() && nedge < father.size() - 1; i++) {
int id1 = edgeSet.get(i).getId1();
int id2 = edgeSet.get(i).getId2();
int value = edgeSet.get(i).getValue();
Person p1 = getPerson(id1);
Person p2 = getPerson(id2);
if (!connectedK(id1, id2)) {
mergeK(id1, id2);
result = result + value;
nedge++;
}
}
return result;
}
通过并查集优化kruskal算法的遍历过程,时间复杂度由普通kruskal的
O(n^2)
$$
优化为了
O(n)
$$
因为kruskal算法需要对边关于权重进行排序,所以有两种选择:
-
在加边的时候直接插入排序
-
每次调用qlc的时候进行排序
两种方法在不同的指令比例下性能各有利弊,所以我选择的是每次调用方法的时候进行排序,选择的是java内置的sort函数。
Dijkstra 最短路径算法
sim指令需要在社会网络中寻找发送者和接收者之间的最短路径
public int dijkstra(int fromId, int dstId) {
HashMap<Integer, Integer> dis = new HashMap<>(); //dis:记录从Id到index的距离,index为key,value为距离
HashMap<Integer, Boolean> used = new HashMap<>(); //记录哪些节点已经被遍历过了
for (Person person : people.values()) {
dis.put(person.getId(), Integer.MAX_VALUE);
used.put(person.getId(), false);
}
Queue<Integer> idQueue = new LinkedList<>();//key是id,value是从fromId到id的最短距离
Queue<Integer> valQueue = new LinkedList<>();
dis.put(fromId, 0);
idQueue.add(fromId);
valQueue.add(0);
while (!idQueue.isEmpty()) {
int nowId = idQueue.poll();
int nowVal = valQueue.poll();
if (used.get(nowId)) {
continue;
}
used.put(nowId, true);
for (Person person : getPerson(nowId).getAcquaintance()) {
if (dis.get(person.getId()) >
getPerson(nowId).queryValue(person) + nowVal) {
dis.put(person.getId(), getPerson(nowId).queryValue(person) + nowVal);
idQueue.add(person.getId());
valQueue.add(dis.get(person.getId()));
}
}
}
return dis.get(dstId);
}
Network扩展
假设出现了几种不同的Person
Advertiser:持续向外发送产品广告
Producer:产品生产商,通过Advertiser来销售产品
Customer:消费者,会关注广告并选择和自己偏好匹配的产品来购买 -- 所谓购买,就是直接通过Advertiser给相应Producer发一个购买消息
Person:吃瓜群众,不发广告,不买东西,不卖东西
如此Network可以支持市场营销,并能查询某种商品的销售额和销售路径等 请讨论如何对Network扩展,给出相关接口方法,并选择3个核心业务功能的接口方法撰写JML规格(借鉴所总结的JML规格模式)
public class Advertiser implements Person;
public class Producer implements Person;
public class Customer implements Person;
public class PurchaseMsg implements Message;
public class AdvertiseMsg implements Message;
public class ProduceMsg implements Message;
/*@ public normal_behavior
@ requires containsAdvertisement(id);
@ assignable AdvertisementList;
@ ensures !containsAdvertisement(id) && AdvertisementList.length == \old(AdvertisementList.length) - 1 &&
@ (\forall int i; 0 <= i && i < \old(AdvertisementList.length) && \old(AdvertisementList[i].getId()) != id;
@ (\exists int j; 0 <= j && j < AdvertisementList.length; AdvertisementList[j].equals(\old(AdvertisementList[i]))));
@ ensures (\forall int i; 0 <= i && i < CustomerList.length;
@ (\forall int j; 0 <= j < \old(CustomerList[i].AdvertisementList.length)
@ (\exists int k; 0 <= k < CustomerList[i].AdvertisementList.length;
@ \old(CustomerList[i].AdvertisementList[j]) == CustomerList[i].AdvertisementList[k])));
@also
@ public exceptional_behavior
@ signals (MessageIdNotFoundException e) !containsMessage(id);
@ signals (NotAdvertisementException e) !(getMessage(id) instanceof Advertisement);
@*/
public void sendAdvertisement(int id) throws
MessageIdNotFoundException, NotAdvertisementException;
/*@ public normal_behavior
@ requires contains(producerId) && (getPerson(producerId) instanceof Producer);
@ assignable getProducer(producerId).productCount;
@ ensures getProducer(producerId).getProductCount(productId) ==
@ \old(getProducer(producerId).getProductCount(productId)) + 1;
@ also
@ public exceptional_behavior
@ signals (PersonIdNotFoundException e) !contains(producerId);
@ signals (NotProducerException e) !(getPerson(producerId) instanceof Producer);
@*/
public void Produce(int producerId, int productId) throws
PersonIdNotFoundException, NotProducerException;
/*@ public normal_behavior
@ requires contains(personId);
@ requires containsProduct(productId);
@ requires containsSaler(salerId);
@ ensures getPerson(personId).money = \old(getPerson(personId).money) - getProduct(productId).getValue;
@ ensures getSaler(salerId).getProduct(productId).getLeftNum() = \old(getSaler(salerId).getProduct(productId).getleftNum()) - 1;
@also
@ public exceptional_behavior
@ signals (PeronIdNotFoundException) !contains(customerId);
@ also
@ public exceptional_behavior
@ signals (PeronIdNotFoundException) !contains(advertiserId);
@ also
@ public exceptional_behavior
@ signals (PeronIdNotFoundException) !contains(product.getProducer);
@ also
@ public exceptional_behavior
@ signals (ProductIdNotFoundException) !getPerson(advertiserId).containsProduct(product);
@*/
public /*@ pure @*/void purchaseProduct(int personId, int productId, int salerId) throws PeronIdNotFoundException, ProductIdNotFoundException;
工具总结
key promoter X
Key promoter X的功能就是帮助我们提升代码编写的速度。
这个插件能够帮我们学习idea中一些常用的快捷键操作,免除敲着敲着代码还要换手用鼠标去操作的麻烦。在安装之后,当使用者在idea中使用鼠标时,如果这个鼠标操作是可以使用快捷键替代的,Key Promoter 就会弹出提示框,告知我们这个鼠标操作可以使用什么快捷键替代。
除此之外,Key Promoter X还提供统计功能,安装这个插件之后,在idea界面的右侧边栏,你可以看到最近我们的哪些鼠标操作可以使用快捷键替代,以及这些操作你分别进行了多少次。
Linux指令测cpu时间
CPU时间(CPU TIME)是指当应用进程启动后,占用CPU进行计算所占用的时间绝对值,或者叫时间点。如果进程进入中断、挂起、休眠等等的行为,其实是不占用CPU的,因此也就不增加CPU时间。
在过去的几个单元作业中,常常出现因为循环比较多或者算法不够优化而报错CPU时间超时的问题。为了“见bug于未萌”,我们就需要一种方法来在设计中就能衡量CPU时间,进而进行相应的优化。而Linux系统的time命令,就给了我们实现这个目标的途径。
time命令常用于测量一个命令的运行时间,注意不是用来显示和修改系统时间的。它能做的不仅仅是测量运行时间,还可以测量内存、I/O等的使用情况。
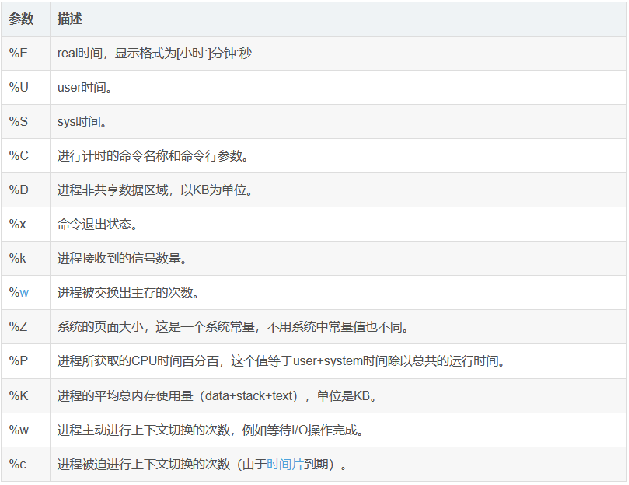
上面说-f选项的作用是格式化时间输出,它有一些参数,写在这里的表格里。我们可以发现,我们需要测量的CPU时间就可以使用%U这个参数。所以,如果我们想测我们项目的CPU时间,就可以把项目打包成jar文件,然后在linux的命令行中输入下面这个指令,来把运行这个jar文件消耗的CPU时间输出到time.txt这个文本文件中。

junit
JUnit是一个Java语言的单元测试框架;Junit测试是程序员测试,即所谓
我对于junit这个单元测试的理解,是他更像是学习计组Verilog的时候ise提供的代码测试时自动生成的那个TestBench文件,它只是提供了一个对代码进行测试的框架,具体实现本质上还是需要测试者来根据自己对于可能的错误和边界条件的理解进行手动测试。idea在其中的作用就是为这种手动测试提供了一定的便利。
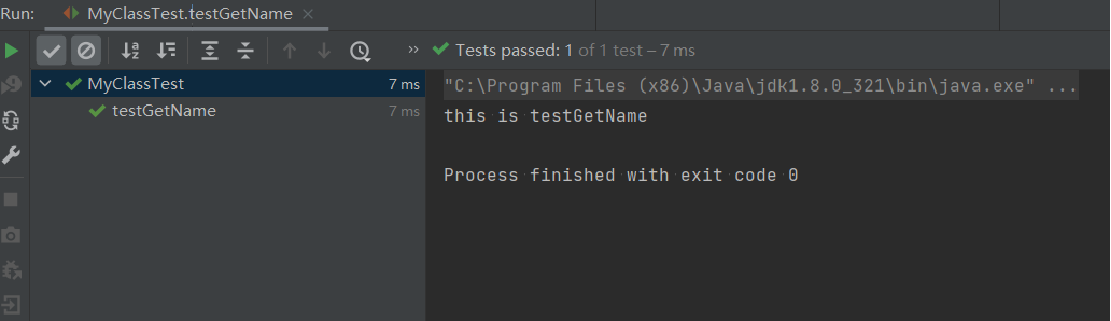
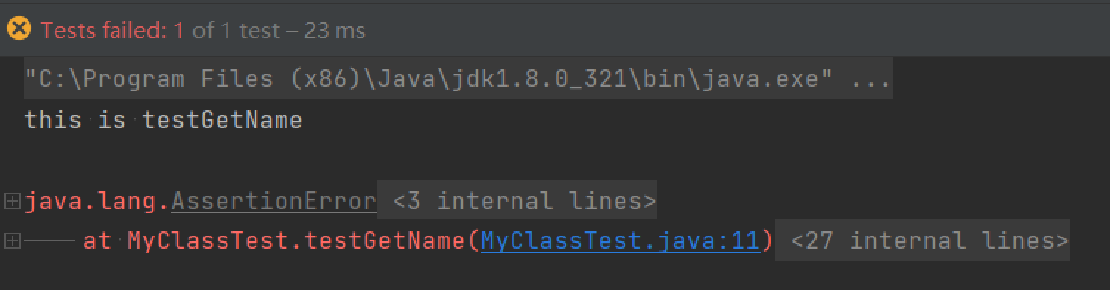
测试的结果应该就显示在下方弹出的junit测试中断窗口上,窗口上方的test passed显示了测试的总数和通过测试的数量,如果你的代码没有通过你自己写的junit测试,结果回像下面一样,显示test failed。
这里是自动生成的junit测试类代码框架中的几个注释,不同的注释修饰的方法在测试类中扮演不同的角色、有不同的功能。

其中最核心的注释就是test了,我们只需要在我们用来测试的方法上加上这个注解,这个方法就会被当做一个单元测试方法,单独去运行。也就是说,最核心的测试逻辑就存在于被test注释修饰的方法中。
before和after是相对于被test注释的方法而言的,被before注释的方法会在test方法运行之前被调用,一般来说呢是用来为test方法做前期准备的。而after则在test方法被调用完成后被调用,作用是进行一些收尾工作,比如释放在before中分配的资源。
beforeClass 和 afterClass类似于before和after,但是他俩都只能被执行一次,而且beforeclass是运行测试类时第一个被执行的方法,相应的afterclass是运行测试类时最后一个被执行的方法.
这里补充一点:就是在单元测试中断言的使用。
在使用单元测试的时候,可以使用断言(assert)来判断输出结果和中间变量是否正确、符合要求。相较于print中间变量和结果,使用assert工具类判断正确性具有几点好处:
-
错误明确,易于确认。相较于print在一大堆输出中找错误数据,assert可以直接输出错误信息并中断执行。
-
与junit配合更好。在@test注释的类中assert,如果不满足,那么在test运行窗口的上方可以直接判断程序测试是否通过
jprofiler
JProfiler 是一个主要用于检查和跟踪系统性能的工具。它可以通过实时监控系统的内存使用情况,随时监视垃圾回收,线程运行状况等手段,很好的监视 JVM 运行情况及其性能。
jprofiler的功能很强大,可以用来监测程序运行过程中多个维度的参数和数据,从而立体地分析和评价程序的性能。
在进入jprofiler的界面后,左侧有几个模块,可以检查各个视角下的程序运行情况,比如内存使用、CPU使用、并发情况等等。
通过在左侧的边栏选择要查看的模块,我们还可以在CPU views中使用jprofiler观察调用关系,并同步查看各个线程的状态和运行情况;此外,还可以检测各个方法占用的时间;在线程检测器中可以查看各个线程的运行时间、当前的运行状态等等信息。
学习体会
通过本单元的学习,我学会了如何面对JML规格书写代码,并更加熟悉了项目迭代的流程和需要的工具。
同时,通过三个每周作业,我还回顾(学习)了三种常用的集合与图论算法:并查集、dijkstra和kruskal,并更加熟悉了对于算法的常见的优化方式,比如更换效率更高的容器、优化算法的具体实现等。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号