2023-06-11:redis中,如何在100个亿URL中快速判断某URL是否存在?
2023-06-11:redis中,如何在100个亿URL中快速判断某URL是否存在?
答案2023-06-11:
传统数据结构的不足
当然有人会想,我直接将网页URL存入数据库进行查找不就好了,或者建立一个哈希表进行查找不就OK了。
当数据量小的时候,这么思考是对的,
确实,将值映射到 HashMap 的 Key,可以在 O(1) 的时间复杂度内返回结果,具有高效的优点。但是 HashMap 的实现也存在一些不足,例如存储容量占比较高。考虑到负载因子的存在,通常需要预留一定的空间,导致实际空间不能被完全利用。例如,如果有一个1000万大小的 HashMap,以String类型为Key(长度不超过16个字符,且非常少重复),以Integer类型为Value,需要占据多少空间呢?实际上,它将占用1.2GB内存。相比之下,存储1000万个int类型的数据只需要大约40MB空间,占比仅为3%;而存储1000万个Integer类型的数据则需要约161MB空间,占比高达13.3%。因此,一旦数据量增大到数亿级别,HashMap 所占据的内存大小将变得非常可观。
如果整个网页黑名单系统包含100亿个网页URL,则简单的数据库查找操作将非常费时,并且如果每个URL空间为64B,则整个系统需要的内存空间将达到640GB,这对于一般的服务器来说是一个非常大的需求,难以实现。
布隆过滤器
布隆过滤器简介
1970 年布隆提出了一种布隆过滤器的算法,用来判断一个元素是否在一个集合中。
这种算法由一个二进制数组和一个 Hash 算法组成。
本质上布隆过滤器是一种数据结构,比较巧妙的概率型数据结构(probabilistic data structure),特点是高效地插入和查询,可以用来告诉你 “某样东西一定不存在或者可能存在”。
相比于传统的 List、Set、Map 等数据结构,它更高效、占用空间更少,但是缺点是其返回的结果是概率性的,而不是确切的。
实际上,布隆过滤器被广泛应用于网页黑名单系统、垃圾邮件过滤系统、爬虫网址判重系统等领域。Google 著名的分布式数据库 Bigtable 就使用了布隆过滤器来查找不存在的行或列,以减少磁盘查找的IO次数。此外,Google Chrome浏览器也使用布隆过滤器来加速安全浏览服务。

布隆过滤器的误判问题
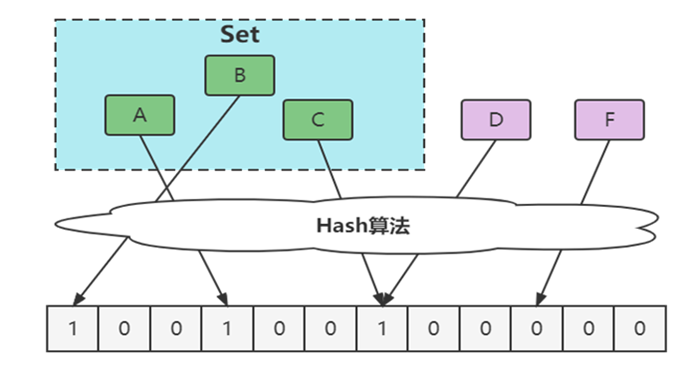
Ø通过哈希计算得到的在数组上的位置并不一定代表元素真正存在于集合中
Ø误判问题的本质是哈希冲突,即不同的元素可能哈希到相同的数组位置
Ø如果一个元素的哈希值不在数组中,则一定不存在于集合中,但是如果哈希值在数组中,则存在误判的概率(误判)
优化方案
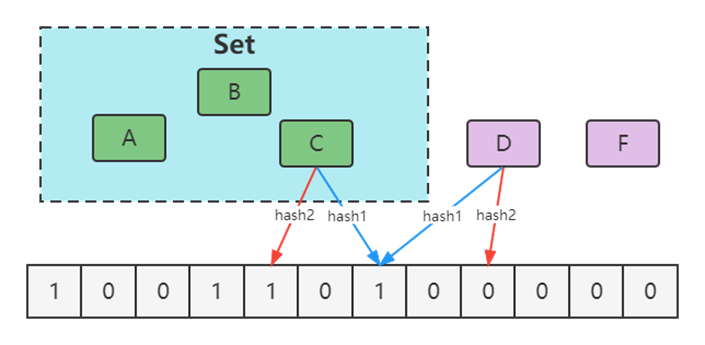
增大哈希数组的长度,使其能够容纳更多的元素。需要根据集合大小和误判率等因素,预估合适的数组长度;
增加哈希函数的数量,以减少哈希冲突的概率。多个哈希函数可以让元素哈希到多个位置上,从而降低误判率。
布隆过滤器重要的三个公式
1.假设数据量为n,预期的失误率为p(布隆过滤器大小和每个样本的大小无关)。
2.根据n和p,算出BloomFilter一共需要多少个bit位,向上取整,记为m。
3.根据m和n,算出BloomFilter需要多少个哈希函数,向上取整,记为k。
4.根据修正公式,算出真实的失误率p_true。
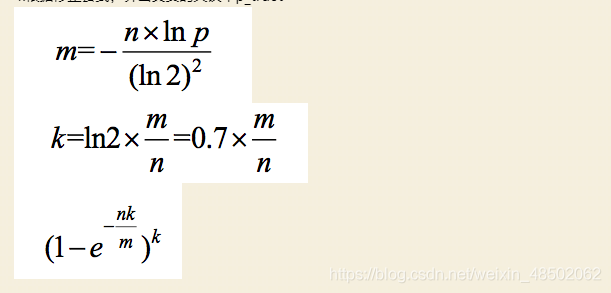
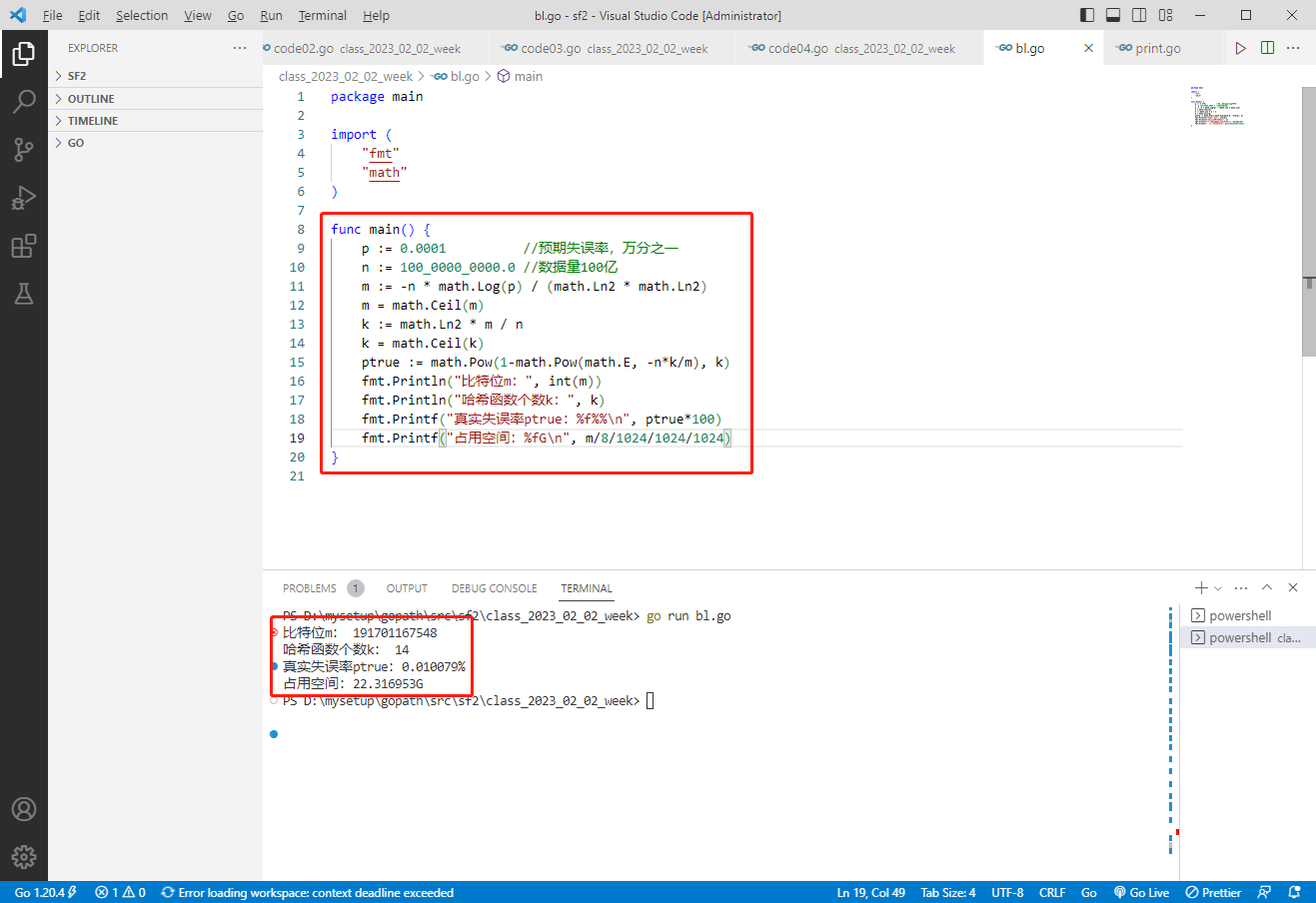
golang代码如下:
package main
import (
"fmt"
"math"
)
func main() {
p := 0.0001 //预期失误率,万分之一
n := 100_0000_0000.0 //数据量100亿
m := -n * math.Log(p) / (math.Ln2 * math.Ln2)
m = math.Ceil(m)
k := math.Ln2 * m / n
k = math.Ceil(k)
ptrue := math.Pow(1-math.Pow(math.E, -n*k/m), k)
fmt.Println("比特位m:", int(m))
fmt.Println("哈希函数个数k:", k)
fmt.Printf("真实失误率ptrue:%f%%\n", ptrue*100)
fmt.Printf("占用空间:%fG\n", m/8/1024/1024/1024)
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号