
日志采集处理
最近由于项目需要上线一个日志采集、展示的功能,借此机会梳理了一下日志采集的大体框架。一般日志采集的总体框架如下:
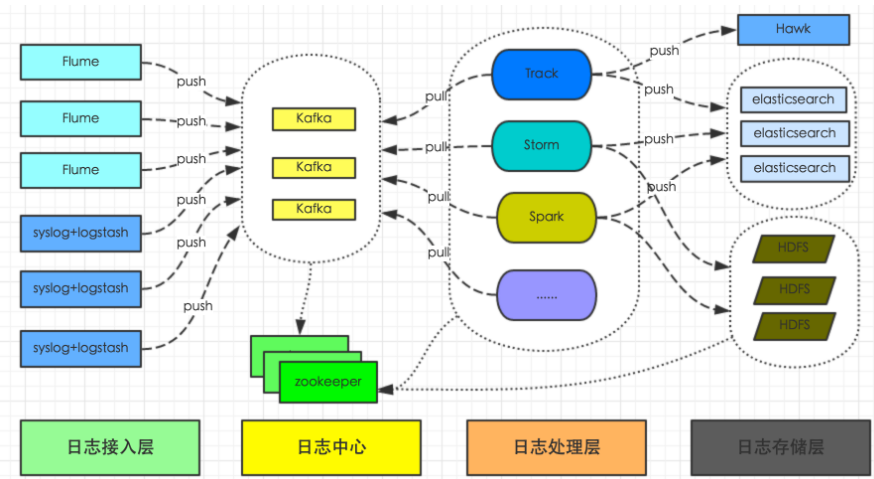
大体流程为:统一日志系统负责收集所有系统日志和业务日志,转化为流式数据,通过flume或logstash上传到日志中心(kafka集群),然后供Track、Storm、Spark及其它系统实时分析处理日志,并将日志持久化存储到HDFS供离线数据分析处理,或写入ElasticSearch提供数据查询,或写入Hawk发起异常报警或提供指标监控查询。
从上面总体架构图中,我们可以看到整个日志平台架构分为四层,从左到右依次是日志接入层、日志中心、日志处理层、日志存储层。
1、日志接入层
日志接入层主要有两种方式,方式1基于rsyslog和logstash,方式2基于flume-ng
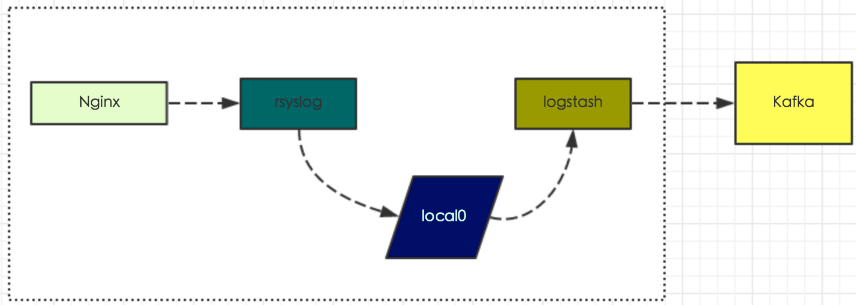
对于一些稳定的日志,比如系统日志或框架日志(如nginx访问日志、phpfpm异常日志等),我们添加nginx配置,通过rsyslog写到本地目录local0,然后logstash根据其配置,会将local0中的增量日志上传到日志中心对应的topic中。
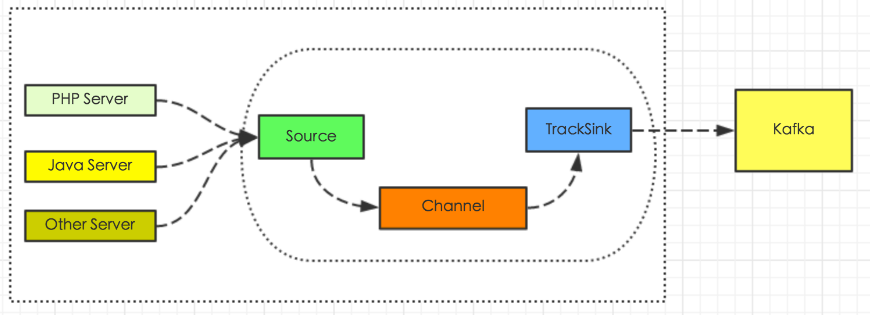
基于本身项目架构,我们采用Flume + MongoDBsink 和Flume + elasticsearch + kibana的二种方式进行处理,后面会做详细介绍。
MongoDBSink配置如下:
agent.sources = r1
agent.channels = c1
agent.sinks = s1
agent.sources.r1.type = exec
agent.sources.r1.command = tail -F /data01/monitorRequst.log
agent.sources.r1.interceptors = i1
agent.sources.r1.interceptors.i1.type = regex_extractor
agent.sources.r1.interceptors.i1.regex = (\\{.+\\})
agent.sources.r1.interceptors.i1.serializers = s1
agent.sources.r1.interceptors.i1.serializers.s1.type = org.apache.flume.interceptor.RegexExtractorInterceptorPassThroughSerializer
agent.sources.r1.interceptors.i1.serializers.s1.name = value
agent.channels.c1.type = memory
agent.channels.c1.capacity = 1000
agent.channels.c1.transactionCapacity = 100
agent.sinks.s1.type = org.riderzen.flume.sink.MongoSink
agent.sinks.s1.host = XX.XX.XX.XX
agent.sinks.s1.port = 27017
agent.sinks.s1.model = SINGLE
agent.sinks.s1.db = 数据库表
agent.sinks.s1.username = XX
agent.sinks.s1.password = YY
agent.sinks.s1.collection = 表名
agent.sinks.s1.batch = 100
agent.sources.r1.channels = c1
agent.sinks.s1.channel = c1

