线程转储分析
一、线程状态
在具体分析线程转储数据之前,我们首先要明确线程的状态。java.lang.Thread.State枚举类中定义了如下几种类型:
- NEW:线程创建尚未启动。
- RUNNABLE:包括操作系统线程状态中的Ready和Running,可能在等待时间片或者正在执行。
- BLOCKED:线程被阻塞。
- WAITING:不会分配CPU执行时间,直到别的线程显式的唤醒,否则无限期等待。LockSupport.park(),没有设置Timeout参数的Object.wait()和Thread.join(),会导致此现象。
- TIMED_WAITING:不会分配CPU执行时间,直到系统自动唤醒,不需要别的线程显示唤醒。Thread.sleep(),LockSupport.parkNanos(),LockSupport.parkUntil(),设置了超时时间的Object.wait()和Thread.join(),会让线程进入有限期等待。
- TERMINATED:线程执行结束
很多人分不清楚阻塞和等待的区别,导致在分析线程转储时出现偏差。
阻塞状态与等待状态的区别是:阻塞状态的线程是在等待一个排它锁,直到别的线程释放该排它锁,该线程获取到该锁才能退出阻塞状态;
而等待状态的线程则是等待一段时间,由系统唤醒或者别的线程唤醒,该线程便退出等待状态。
线程状态转化见下图:
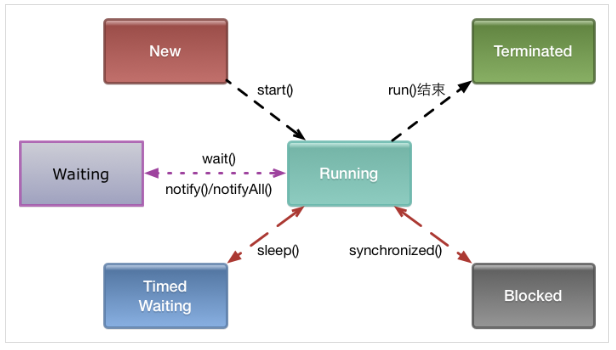
在任意一个时刻,线程只能处于其中的一种状态。
上面的状态颗粒度比较大,stackoverflow上有个哥们将状态定义为如下11种。在我们强制dump出来的转储中,更多的是表现为如下状态中的一种。至于这11种状态的是否权威,不敢妄下定论。
- NEW: Just starting up, i.e., in process of being initialized.
- NEW_TRANS: Corresponding transition state (not used, included for completness).
- IN_NATIVE: Running in native code.
- IN_NATIVE_TRANS: Corresponding transition state.
- IN_VM: Running in VM.
- IN_VM_TRANS: Corresponding transition state.
- IN_JAVA: Running in Java or in stub code.
- IN_JAVA_TRANS: Corresponding transition state (not used, included for completness).
- BLOCKED: Blocked in vm.
- BLOCKED_TRANS: Corresponding transition state.
- UNINITIALIZED
Java的线程转储指的是JVM中在某一个给定的时刻运行的所有线程的快照。一个线程转储可能包含一个单独的线程或者多个线程。在多线程环境中,如Java EE应用服务器,将会有许多线程和线程组。转储中的每一个线程都有一自己独立的逻辑,这些逻辑信息将会在堆栈信息中体现。
线程转储可以通过如下的方式生成:
- Unix:kill -3 ,输出到了/proc//fd/1
- Windows:CTRL+BREAK
- jstack:jstack >> 输出文件
在Linux上,大家可能都碰见过这样的问题:

就是用jstack 是拿不到thread dump的,必须加-F来强制dump。上面的问题是其实很简单,就是pid路径问题导致的,Google一下就清楚了。我想说的是,加-F dump出来的内容是不能用TDA分析的。如果不是真正的进程挂起,如果又想使用TDA进行分析的话,可以使用第一种方式进行dump。但有时候,的确必须要使用-F才能获得dump信息,比如程序挂起了。由于jstack -F/m就会使用到SA(The Serviceability Agent),我们平常不加-F/-m的时候默认走的是Instrumentation的attach操作,知道这点非常重要。
二、转储说明
线程转储生成好之后,我们便可以开始着手分析转储信息了,下面会给出几个例子逐一分析。
例子1
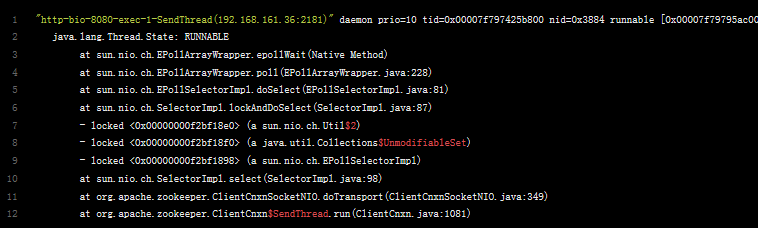
- http-bio-8080-exec-1-SendThread(192.168.161.36:2181):线程的名字
- daemon:守护线程
- prio=10:线程的优先级(默认是5)
- tid:Java的线程Id(线程在当前虚拟机中的唯一标识)
- nid:线程本地标识
- runnable:线程的状态
- [0x00007f79795ac000]:当前运行的线程在堆中的地址范围
这个线程转储的剩余部分是调用堆栈,这个线程(http-bio-8080-exec-1-SendThread(192.168.161.36:2181))是操作系统守护线程,当前正在执行一个本地方法epollWait。该native线程正处于RUNNABLE的状态。
例子2
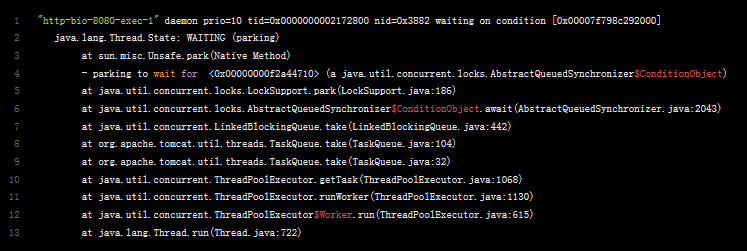
该转储表示守护线程http-bio-8080-exec-1会一直等待,直到ThreadPoolExecutor上有需要执行的任务分配给该线程执行(LockSupport.unpark),它才能从LockSupport.park中解脱出来。
例子3
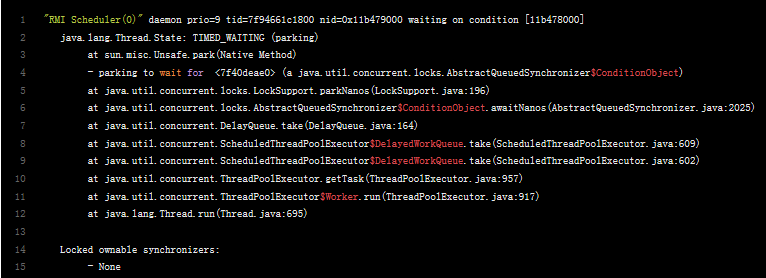
线程RMI Scheduler不会分配CPU执行时间,直到系统自动唤醒,不需要别的线程显示唤醒。它由于调用了LockSupport.parkNanos()进入了有限期等待。
三、案例分析
1、CPU负载高
Java进程CPU占用率居高不下,导致系统吞吐率下降,这种问题对很多初级码农来说简直就是梦魇。如果想快速的定位CPU高的原因,线程转储绝对是第一选择。CPU过高一般原因分为CPU密集型和死循环,这两种情况我们分开来分析。
死循环分析非常简单,步骤如下:
- 在CPU占用率高的时候,通过top -H或者ps H -eo user,pid,ppid,tid,time,%cpu,cmd –sort=%cpu将CPU占用率高的线程的tid给找出来,并即时线程转储。
- 将上面的找到的tid进行转化为16进制,然后在线程转储中查找对应的线程号,都会找到对应的nid标示。
- 定位之后,通过转储中的精确的行号,可以定位到代码中相应的位置,便可以迅速确定原因。
死循环一般是逻辑错误导致的,我们在代码中应该慎用自旋。在一些带有状态机逻辑的代码中,加入次数限制,防止程序跑飞。
CPU密集型分析跟死循环不一样,因为你通过查看线程的CPU使用率,你会发现每个线程都不是很高,但是多个加起来之后就不容乐观。这类问题,步骤如下:
- 在CPU占用率高的时候,通过top -H或者ps H -eo user,pid,ppid,tid,time,%cpu,cmd –sort=%cpu将CPU占用率高的前10个线程的tid给找出来,并即时线程转储。
- 将上面的找到的tid进行转化为16进制,然后在线程转储中查找对应的线程号,将能够找到的部分标记出来。
- 然后在标记出来的线程转储中寻找共性。如果通过所有的线程转储,发现线程正在执行同一个方法(同样的行号),几乎就可以确定这就是罪魁祸首了。那就可以查看代码,来做代码级别的分析了,问题便迎刃而解了。
CPU密集型,一般原因是算法效率低导致的。例如,正则表达式写的差,该用Map或者Set结构的却用了List来遍历。
线程占用CPU的类型可以分为如下两种:
us:用户空间占用CPU百分比
sy:内核空间占用CPU百分比
在linux下可以通过top命令查看详细,示例如下:

CPU us高的原因主要是执行线程不需要任何挂起动作,且一直执行,导致CPU没有机会去调度执行其他的线程,我们上面分析的都属于这类情况。
CPU sy高的原因主要是线程的运行状态要经常切换,对于这种情况,常见的一种优化方法是减少线程数。
2、响应慢(低负载)
相应时间长,一般出现在高负载的机器上。如果在CPU的占用率很低,只有几个线程在消耗CPU的时间片,然而应用的响应时间却很长,我们首先要想到的是IO操作出现问题,至于到底是网络IO还是本地IO,我们就可以通过线程转储来定位。定位到位置之后,可以使用缓存或者减少IO操作来提升系统响应速度。
3、应用/服务宕机
当一个应用活着却不能完成任何响应的时候,表明该服务已经宕机。
此时分析线程转储,会发现大量的线程在同一个操作中罢工了,没有任何一个线程能够完成自己的操作,从而导致该JVM再没有可用的线程。很多时候都是由于死锁导致的,当一个线程持有一个对象锁而不释放,而别的线程都在等待该锁的时候便会发生死锁现象。幸运的是JVM通常会检测死锁,通过工具分析转储能够更快的定位到原因。如果想避免复杂的死锁,我们需要尽可能减小同步块的大小,并且在进行资源的访问时设置合理的超时时间,避免死等现象。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号