Kafka消息模型
一、消息传递模型
传统的消息队列最少提供两种消息模型,一种P2P,一种PUB/SUB,而Kafka并没有这么做,巧妙的,它提供了一个消费者组的概念,一个消息可以被多个消费者组消费,但是只能被一个消费者组里的一个消费者消费,这样当只有一个消费者组时就等同与P2P模型,当存在多个消费者组时就是PUB/SUB模型。

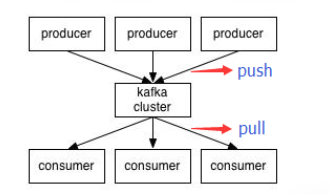
Kafka 的 consumer 是以pull的形式获取消息数据的。 pruducer push消息到kafka cluster ,consumer从集群中pull消息,如下图。该博客主要讲解. Parts在消费者中的分配、以及相关的消费者顺序、底层结构元数据信息、Kafka数据读取和存储等。
二、消息持久化
很多系统、组件为了提升效率一般恨不得把所有数据都扔到内存里,然后定期flush到磁盘上;可实际上,现代操作系统也是这样,所有的现代操作系统都乐于将空闲内存转作磁盘缓存(页面缓存),想不用都难;对于这样的系统,他的数据在内存中保存了一份,同时也在OS的页面缓存中保存了一份,这样不但多了一个步骤还让内存的使用率下降了一半;因此,Kafka决定直接使用页面缓存;但是随机写入的效率很慢,为了维护彼此的关系顺序还需要额外的操作和存储,而线性的写入可以避免这些,实际上,线性写入(linear write)的速度大约是300MB/秒,但随即写入却只有50k/秒,其中的差别接近10000倍。这样,Kafka以页面缓存为中间的设计在保证效率的同时还提供了消息的持久化,每个消费者自己维护当前读取数据的offser(也可委托给zookeeper),以此可同时支持在线和离线的消费。
三、Push vs. Pull
对于消息的消费,ActiveMQ使用PUSH模型,而Kafka使用PULL模型,两者各有利弊,对于PUSH,broker很难控制数据发送给不同消费者的速度,而PULL可以由消费者自己控制,但是PULL模型可能造成消费者在没有消息的情况下盲等,这种情况下可以通过long polling机制缓解,而对于几乎每时每刻都有消息传递的流式系统,这种影响可以忽略。
四、消息投递可靠性
一个消息如何算投递成功,Kafka提供了三种模式:
- 第一种是啥都不管,发送出去就当作成功,这种情况当然不能保证消息成功投递到broker;
- 第二种是Master-Slave模型,只有当Master和所有Slave都接收到消息时,才算投递成功,这种模型提供了最高的投递可靠性,但是损伤了性能;
- 第三种模型,即只要Master确认收到消息就算投递成功;实际使用时,根据应用特性选择,绝大多数情况下都会中和可靠性和性能选择第三种模型
消息在broker上的可靠性,因为消息会持久化到磁盘上,所以如果正常stop一个broker,其上的数据不会丢失;但是如果不正常stop,可能会使存在页面缓存来不及写入磁盘的消息丢失,这可以通过配置flush页面缓存的周期、阈值缓解,但是同样会频繁的写磁盘会影响性能,又是一个选择题,根据实际情况配置。
消息消费的可靠性,Kafka提供的是“At least once”模型,因为消息的读取进度由offset提供,offset可以由消费者自己维护也可以维护在zookeeper里,但是当消息消费后consumer挂掉,offset没有即时写回,就有可能发生重复读的情况,这种情况同样可以通过调整commit offset周期、阈值缓解,甚至消费者自己把消费和commit offset做成一个事务解决,但是如果你的应用不在乎重复消费,那就干脆不要解决,以换取最大的性能。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号