
Kafka分布式消息模型
Kafka开发的主要初衷目标是构建一个用来处理海量日志,用户行为和网站运营统计等的数据处理框架。在结合了数据挖掘,行为分析,运营监控等需求的情况下,需要能够满足各种实时在线和批量离线处理应用场合对低延迟和批量吞吐性能的要求。从需求的根本上来说,高吞吐率是第一要求,其次是实时性和持久性。
既有的消息队列框架或者对消息传送的可靠性提供了较高的保证,由此带来较大的负担,不能满足海量高吞吐率的要求;或者完全面向实时消息处理系统,对于批量离线处理的场合无法提供足够的缓存和持久性要求。
而多数针对大数据开发应用的日志收集处理系统(e.g. scribe, flume)则通常更适合批量离线处理场合,对实时在线处理的场合支持不够。
总体而言,Kafka试图提供一个同时满足在线和离线处理海量数据的消息派发系统。
一、Kafka的实现
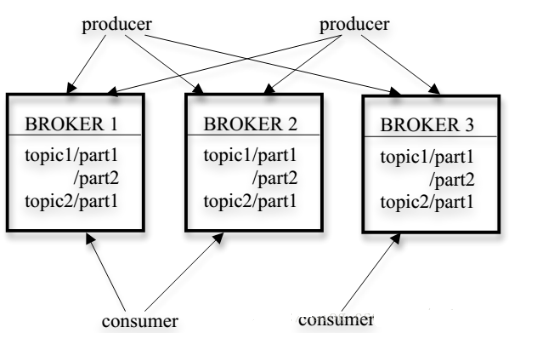
Kafka的集群有多个Broker服务器组成,每个类型的消息被定义为topic,同一topic内部的消息按照一定的key和算法被分区(partition)存储在不同的Broker上,消息生产者producer和消费者consumer可以在多个Broker上生产/消费topic.
核心思想:以高效率作为第一设计原则,Kafka的结构设计在很多方面都做了激进的取舍.
Topic
Topic是生产者生产、消费者消费的队列标识。一个Topic由一个或多个partition组成,每个partition可以单独存在一个broker上,消费者可以往任一partition发送消息,以此实现生产的分布式,任一partition都可以被且只被一个消费者消息,以此实现消费的分布式;因此partition的设计提供了分布式的基础。

同时,从上图我们也能发现这种设计还有一个优点,因为每个partition内的消息是有序的,而一个partition只能被一个消费者消费,因此Kafka能提供partition层面的消息有序,而传统的队列在多个consumer的情况下是完全无法保证有序的。
1、极简的数据结构和应用模式

消息队列是以log文件的形式存储,消息生产者只能将消息添加到既有的文件尾部,没有任何ID信息用于消息的定位,完全依靠文件内的位移,因此消息的使用者只能依靠文件位移顺序读取消息,这样也就不需要维护复杂的支持随即读取的索引结构。
Kafka broker完全不维护和协调多用户使用消息的行为模式,用户自己维护位移用来索引消息。
最小的并发访问单位就是partition分区,同一用户组内的所有用户(可以理解为同一个应用的所有并发进程)只能有一个访问同一分区,同时分区的个数是固定的,不支持动态调整。这样最大简化了多进程/分布式client之间对消息处理访问的并发控制的复杂度,当然也带来一定的使用模式上的限制(比如最大并发度完全取决于预先规划的partition的个数)
此外分区也带来一个问题就是消息只是分区内部有序而不是全局有序的。如果需要全局有序,应用需要自己靠别的机制来保证。
使用Pull模式派发消息,消息的使用情况,比如是否还有consumer没有读取,是否重复读取(改进中)等,在Broker端也完全不跟踪维护,消息的过期处理简单的由定时器定时删除(比如保留7天),由此简化各种消息跟踪维护的开销。
2、采取各种方式最大化数据传输效率
比如生产者和消费者可以批量读写消息减少RPC开销。使用Zero Copy方式在内核层直接将文件内容传送给网络Socket,避免应用层数据拷贝,使用合理的压缩格式等
3、激进的内存管理模式
基本的意思就是不管理。Kafka不在JVM进程内部维护消息Cache,消息直接从文件中读写,完全依赖操作系统在文件系统层面的cache,避免在JVM中管理Cache带来的额外数据结构开销和GC带来的性能代价。基于批量处理和顺序读写的应用模式,最大化利用文件系统的Cache机制和规避文件读写相对内存读写的性能代价
4、HA
Kafka在0.8之前message是没有备份容错机制的,producer的工作模式是fire and forget,如果一个broker失效,那么相关topic分区的相关消息也就丢失了。这种设计的原因在于最初的应用模式,如日志/用户行为等消息的处理,对数据的健壮性方面要求不高,可以容忍部分数据的缺失。采用fire and forget 模式,不需要等待Broker ack,有利于提高producer的吞吐率。
不过在0.8版本中,添加了数据replica的机制,一个消息分区的多个replica分布在不同的Broker上,由leader replica负责日常读写,通过zookeeper监督failover,不同的分区的leader replica均衡负载到不同的Broker上。在这种情况下,producer可以选择不等待leader replica的Ack,部分Ack,或者完全备份完毕后Ack等不同的ack机制。这三种机制,性能依次递减 (producer吞吐量降低1-3倍),数据健壮性则依次递增。

