Python 爬取 中关村CPU名字和主频
0.准备工作
1.相关教程
2.说明
下面的代码基本只处于可用阶段,欠缺移植性,本篇Bolg更多是一种记录
本篇Bolg中使用的是Python2.7
3.效果
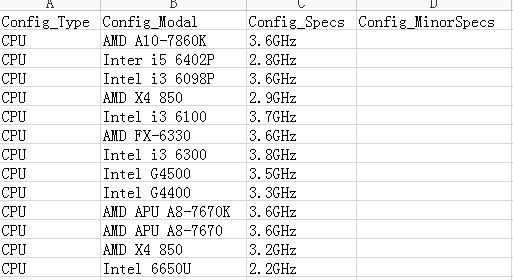
1.获取CPU型号和主频信息
1.神伤的AJAX
我只需修改page=n 即可获取第n页的CPU信息
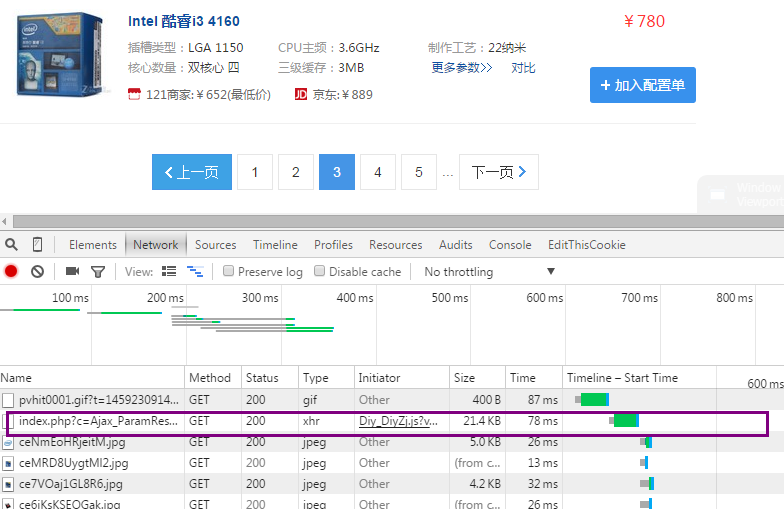
2.获取CPU名字
格式举列
tag.contents[0] :AMD \u7cfb\u5217 A8-7670\uff08\u76d2\u88c5\uff09<\/a>\r\n\t\t\t\t\t <\/h3>\r\n\t\t\t\t\t
manufacturer:AMD
modalDetail:A8-7670
modal:AMD A8-7670
#-*- coding: UTF-8 -*- import urllib import re from bs4 import BeautifulSoup url='http://zj.zol.com.cn/index.php?c=Ajax_ParamResponse&a=GetGoods&subcateId=28&type=0&priceId=noPrice&page=2&manuId=¶mStr=&keyword=&locationId=1&queryType=0' html = urllib.urlopen(url).read() soup=BeautifulSoup(html,"html.parser") listModal=[] listSpecs=[] tags = soup.find_all("a",attrs={"target":"\\\"_blank\\\""}) cnt=0 for tag in tags: cnt+=1 modalSubstr=tag.contents[0] #print 'modalSubstr:'+modalSubstr manufacturer=re.findall('(.+?) ',modalSubstr)[0]#非贪心匹配 遇到空格即中止,返回第一个匹配项 #print 'manufacturer:'+manufacturer detailSubstr=re.findall(' ([0-9a-zA-Z- ]+)',modalSubstr) #print detailSubstr detailSubstr0=detailSubstr[0] #针对i3、i5、i7的处理 if "i3" in modalSubstr: modalDetail="i3 "+detailSubstr0 elif "i5" in modalSubstr: modalDetail="i5 "+detailSubstr0 elif "i7" in modalSubstr: modalDetail="i7 "+detailSubstr0 else: modalDetail=detailSubstr0 #针对APU的处理 if modalDetail=="APU": modalDetail+=" "+detailSubstr[1] modal=manufacturer+" "+modalDetail print "modal:"+modal
效果
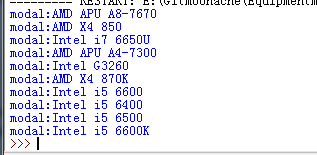
3.获取CPU主频
except IndexError:因为中关村网站上最后一款CPU的主频信息暂无,所以针对这个情况它的规格(specs)为“Data Missed”
#-*- coding: UTF-8 -*- import urllib import re from bs4 import BeautifulSoup url='http://zj.zol.com.cn/index.php?c=Ajax_ParamResponse&a=GetGoods&subcateId=28&type=0&priceId=noPrice&page=2&manuId=¶mStr=&keyword=&locationId=1&queryType=0' html = urllib.urlopen(url).read() soup=BeautifulSoup(html,"html.parser") listModal=[] listSpecs=[] tags = soup.find_all("a",attrs={"target":"\\\"_blank\\\""}) cnt=0 for tag in tags: cnt+=1 print cnt substr=str(tag)[100:500] #以title='\"开头+任意小数+ GHz结尾 specsDictionary=re.findall(r'title=\'\\\"([0-9.]+GHz)',substr) try: specs=specsDictionary[0] except IndexError: specs="Data Missed" print specs
效果

4.循环读取下一页并自动终止
一共有16页,本来可以直接用循环,但经观察发现每页开头的内容中有page值。而且当地址中的page>=16,index.php都只会返回page=16的内容。所以有了下面的代码用来循环读取下一页并自动终止。

urlLeft='http://zj.zol.com.cn/index.php?c=Ajax_ParamResponse&a=GetGoods&subcateId=28&type=0&priceId=noPrice&page=' urlRight='&manuId=¶mStr=&keyword=&locationId=1&queryType=0' urlPageIndex=1 while (1): url=urlLeft+str(urlPageIndex)+urlRight html = urllib.urlopen(url).read() soup=BeautifulSoup(html,"html.parser") soupSub=str(soup)[0:50] pageIndex=int(re.findall('page\":([0-9]+)',soupSub)[0]) if urlPageIndex==pageIndex: tags = soup.find_all("a",attrs={"target":"\\\"_blank\\\""}) cnt=0 for tag in tags: ......省略 print "yes"+str(urlPageIndex) urlPageIndex+=1 else: print "no"+str(urlPageIndex) break
5.输出为csv
python内置了csv读取和导入,我参考crifan上的的csv导出
import csv with open('excel_2010_ms-dos.csv', 'rb') as csvfile: spamreader = csv.reader(csvfile, dialect='excel') for row in spamreader: print ', '.join(row)
6.最终代码
#-*- coding: UTF-8 -*- import urllib import re import csv from bs4 import BeautifulSoup listModal=[] listSpecs=[] urlLeft='http://zj.zol.com.cn/index.php?c=Ajax_ParamResponse&a=GetGoods&subcateId=28&type=0&priceId=noPrice&page=' urlRight='&manuId=¶mStr=&keyword=&locationId=1&queryType=0' urlPageIndex=1 while (1): url=urlLeft+str(urlPageIndex)+urlRight html = urllib.urlopen(url).read() soup=BeautifulSoup(html,"html.parser") soupSub=str(soup)[0:50] pageIndex=int(re.findall('page\":([0-9]+)',soupSub)[0]) if urlPageIndex==pageIndex: tags = soup.find_all("a",attrs={"target":"\\\"_blank\\\""}) cnt=0 for tag in tags: cnt+=1 modalSubstr=tag.contents[0] manufacturer=re.findall('(.+?) ',modalSubstr)[0]#非贪心匹配 遇到空格即中止,返回第一个匹配项 detailSubstr=re.findall(' ([0-9a-zA-Z- ]+)',modalSubstr) detailSubstr0=detailSubstr[0] #针对i3、i5、i7的处理 if "i3" in modalSubstr: modalDetail="i3 "+detailSubstr0 elif "i5" in modalSubstr: modalDetail="i5 "+detailSubstr0 elif "i7" in modalSubstr: modalDetail="i7 "+detailSubstr0 else: modalDetail=detailSubstr0 #针对APU的处理 if modalDetail=="APU": modalDetail+=" "+detailSubstr[1] modal=manufacturer+" "+modalDetail listModal.append(modal) substr=str(tag)[100:500] #以title='\"开头+任意小数+ GHz结尾 specsDictionary=re.findall(r'title=\'\\\"([0-9.]+GHz)',substr) try: specs=specsDictionary[0] except IndexError: specs="Data Missed" listSpecs.append(specs) print "yes"+str(urlPageIndex) urlPageIndex+=1 else: print "no"+str(urlPageIndex) break with open('Config.csv', 'wb') as csvfile: spamwriter = csv.writer(csvfile, dialect='excel') #write 标题行 spamwriter.writerow(['Config_Type','Config_Modal','Config_Specs','Config_MinorSpecs']) i=0 for elementModal in listModal: spamwriter.writerow(['CPU',listModal[i], listSpecs[i]]) i+=1
作者:Moonache
出处:http://www.cnblogs.com/moonache/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文链接,否则保留追究法律责任的权利。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号