
flink ---- 系统内部消息传递的exactly once语义
At Most once,At Least once和Exactly once
在分布式系统中,组成系统的各个计算机是独立的。这些计算机有可能fail。
一个sender发送一条message到receiver。根据receiver出现fail时sender如何处理fail,可以将message delivery分为三种语义:
At Most once: 对于一条message,receiver最多收到一次(0次或1次).
可以达成At Most Once的策略:
sender把message发送给receiver.无论receiver是否收到message,sender都不再重发message.
At Least once: 对于一条message,receiver最少收到一次(1次及以上).
可以达成At Least Once的策略:
sender把message发送给receiver.当receiver在规定时间内没有回复ACK或回复了error信息,那么sender重发这条message给receiver,直到sender收到receiver的ACK.
Exactly once: 对于一条message,receiver确保只收到一次
Flink的Exactly once模式
Flink实现Exactly once的策略: Flink会持续地对整个系统做snapshot,然后把global state(根据config文件设定)储存到master node或HDFS.当系统出现failure,Flink会停止数据处理,然后把系统恢复到最近的一次checkpoint.
什么是分布式系统的global state?
分布式系统由空间上分立的process和连接这些process的channel组成.
空间上分立的含义是,这些process不共享memory,而是通过在communication channel上进行的message pass来异步交流.
分布式系统的global state就是所有process,channel的local state的集合.
process的local state取决于the state of local memory and the history of its activity.
channel的local state是上游process发送进channel的message集减去下游process从channel接收的message的差集.
什么是一致性global state?

假设有两个银行账户A,B.A中初始有600美元,B中初始有200美元. SA, SB, CAB, CBA由A和B分别记录,组成了global state.
在t0时刻,A向B转账50美元;在t1时刻,B向A转账80美元.
如果SA, SB记录于(t0, t1), CAB, CBA记录于(t1, t2),那么global state = 550+200+50+80 = 880,比真实值多了$80. 这就是不一致性global state.
如果 SA, SB, CAB, CBA同属于一个时间区间,那么得到的global state就是一致性的.
Snapshot算法获得一致性global state的难点是什么?
分布式系统没有共享内存(globally shared memory)和全局时钟(global clock).
如果分布式系统有共享内存,那么可以从共享内存中直接获取整个分布式系统的snapshot,无需分别获得各个process,channel的local state再组合成global state.
如果分布式系统有global clock,那么所有的process能在同一时刻各自记录local state,这样就保证了state的一致性.
获得一致性global state的算法 ---- Chandy-Lamport算法
精髓:该算法在普通message中插入了control message – marker
前提:
1) message的传输可能有delay,但一定会到达
2) 每两个process之间都有一条communication path(可能由多条channel组成)
3) Channel是单向的FIFO
描述:
Marker sending rule for process Pi
(1) Process Pi 记录自身state
(2) Pi在记录自身state后,发送下一条message前,Pi向自己所有的outgoing channel发送marker
Marker receiving rule for process Pj on receiving a marker along channel C
如果Pj第一次接收到marker,那么
把channel C的state记为空集
执行marker sending rule
否则(并非第一次接收到marker)
把记录自身state(或最近一次记录另一个channel的state)后,收到这个marker前的message集记为C的state
每个process会记录自身的state和它的incoming channel的state
图解:
A,B,C,D代表4个process.有向线段代表FIFO的channel.绿色圆形代表普通message,橙色矩形代表marker.蓝色的节点和线段代表已经记录state的process和channel
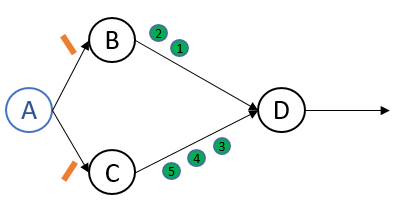
Process A启动snapshot算法,A执行marker sending rule(记录自身state,然后发送marker):

Process B接收到marker,执行marker receiving rule:将channel AB的state记为空集,然后记录自身state并向下发送marker:

Process C接收到marker, 执行marker receiving rule:将channel AC的state记为空集,然后记录自身state并向下发送marker:
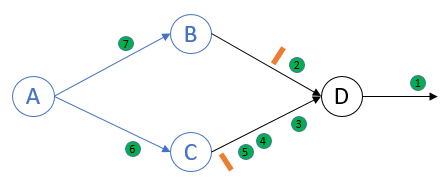
Process D接收到来自于process B的marker, 执行marker receiving rule:将channel BD的state记为空集,然后记录自身state并向下发送marker:
Process D接收到来自于process C的marker, 执行marker receiving rule:这是process D第二次接收到marker,将channel CD的state记为{5},不会向下发送marker:

自此process A,B,C,D的local state和所有Channel的state都记录完毕. 将这些local state组合,所得到的就是global state
Flink的snapshot算法 ---- Asynchronous Barrier Snapshotting(ABS)
为了消去记录channel state这一步骤,process在接收到第一个barrier后不会马上做snapshot,
而是等待接受其他上游channel的barrier.
在等待期间,process会把barrier已到的channel的record放入input buffer.
当所有上游channel的barrier到齐后,process才记录自身state,之后向所有下游channel发送barrier.
因为先到的barrier会等待后到的barrier,所有所有barrier相当于同时到达process,
因此,该process的上游channel的state都是空集.这就避免了去记录channel的state
图解:
A是JobManager, B C是source,D是普通task.
JobManager发起一次snapshot:向所有source发送barrier.
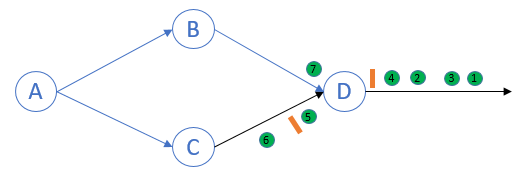
每个Barrier先后到达各自的source.Source在收到barrier后记录自身state,然后向下游节点发送barrier

Barrier (from)B 到达process D,但不会进行snapshot
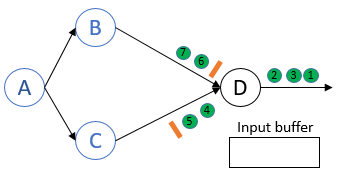
Barrier (from)B已经到达process D,
所以当来自于channel BD的record 6 7到达后,process D不会处理它们,而是将它们放入input buffer.
而Barrier (from)C尚未到达process D,所以当来自于channel CD的record 4到达后,process D会处理它.
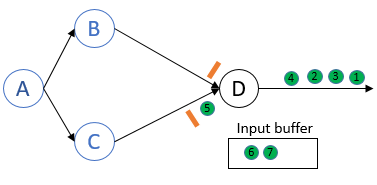
Barrier C也到达process D.
这样,process D已经接收到了所有上游process的barrier.process D记录自身state,然后向下游节点发送barrier
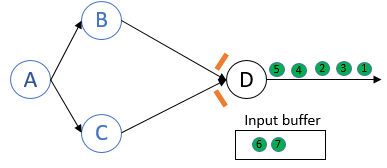
ABS的at least once模式
当process接收到barrier后,会立刻做snapshot. Process会继续处理所有channel的record.后来的snapshot会覆盖之前的snapshot.

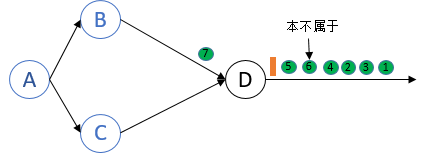
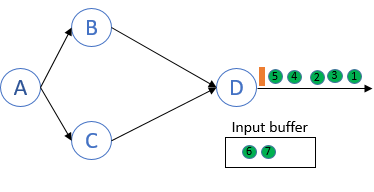
Record 6本不属于这次checkpoint,却包含在process D的local state中.
在recovery时,source认为record 6还没有被处理过,所以重发record 6. 这就导致stream中出现了两个record 6,造成了at least once.
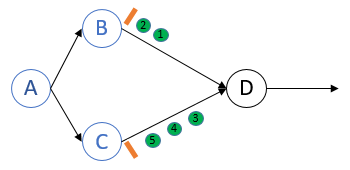
这里的问题在于,当第二个barrier到达时,节点D再次对自身做了snapshot.
而在Chandy-Lamport的算法中,第二个barrier到达时,节点D应该对barrier来源的channel做snapshot.
对单一input channel的算子来说,没有Alignment这个概念.这些算子在at least once模式下也是呈现exactly once的行为

 浙公网安备 33010602011771号
浙公网安备 33010602011771号