
回归(二):局部加权线性回归
前言
回顾一下回归(一)中的标准线性回归:
step1: 对于训练集,求系数w,使得
最小
step2: 对于新输入x,其预测输出为w*x
从中我们知道,标准线性回归可能表达能力比较差,出现如图所示的欠拟合的情况(underfitting):
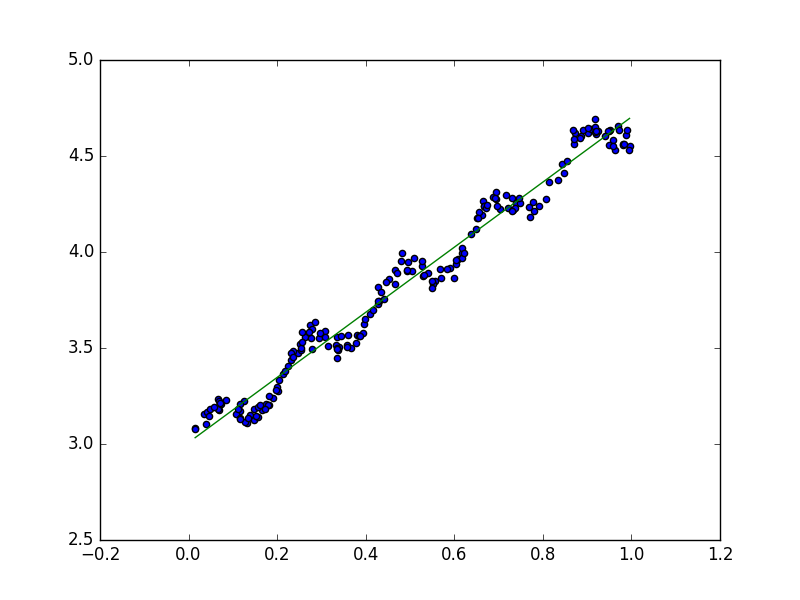
我们可以通过添加诸如x2或sin(x)等特征重新拟合函数来解决这个问题,但是这里讨论另一种方法:局部加权回归(Locally Weighted Linear Regression)
数学表达
它的思想是赋予待预测点附近的点更高的权重,权重随着距离的增大而缩减——这也就是“局部”和“加权”的由来。
既然要加权,误差准则就变成了
![]()
其中W(大写)是训练样本点的权重。按照这个准则解出的回归系数w的矩阵表达如下:

现在再考虑“局部”。要实现局部,就要让权值为关于相距预测点x距离的某个递减函数。LWLR用“核函数”来实现这一点。高斯核是最常用的核函数:

其中x是查询点,xi是第i个训练数据,k是一个需要调节的参数,它控制了训练点距离查询点衰减速率,越小,衰减速率越快。
代码实现
下面参考《机器学习实战》代码实现以下这个算法:
# -*- coding: utf-8 -*-"""author: Alandate:2016/4/3局部加权线性回归,参考《机器学习实战》"""from numpy import *def loadDataSet():fileName = 'D:\Files\python\Ch08\ex0.txt'numFeat = len(open(fileName).readline().split('\t'))-1dataMat = []; labelMat = []fr = open(fileName)for line in fr.readlines():lineArr = []curLine = line.strip().split('\t')for i in range(numFeat):lineArr.append(float(curLine[i]))dataMat.append(lineArr)labelMat.append(float(curLine[-1]))return dataMat, labelMatdef lwlr(testPoint, xArr, yArr, k = 1.0):'''the algorithm of lwlr'''xMat = mat(xArr); yMat = mat(yArr).Tm = shape(xMat)[0]#样本个数weights = mat(eye(m))#单位矩阵,用于存储权重for j in range(m):diffMat = testPoint - xMat[j]weights[j, j] = exp(diffMat * diffMat.T/(-2.0*k**2))#用高斯核求权重xTx = xMat.T * (weights * xMat) #括号里面是把样本乘以对应的权重if linalg.det(xTx) == 0.0:#计算行列式print 'This matrix is singular, cannot do inverse!'returnws = xTx.I * (xMat.T * (weights * yMat))return testPoint * wsdef lwlrTest(testArr, xArr, yArr,k):num = shape(testArr)[0]yHat = zeros(num)#存储预测的labelfor i in range(num):yHat[i] = lwlr(testArr[i], xArr, yArr, k)return yHat#绘制估计的点和原始点的对比图#k控制训练点距离查询点的衰减速率,越小,衰减越快def plotData(k):xArr, yArr = loadDataSet()#用lwlr对整个数据集进行估计yHat = lwlrTest(xArr, xArr, yArr, k )import matplotlib.pyplot as pltxMat = mat(xArr)srtInd = xMat[:, 1].argsort(0)#从小到大排序xSort = xMat[srtInd][:, 0, :]#绘制估计出的点构成的曲线fig = plt.figure()ax = fig.add_subplot(111)ax.plot(xSort[:, 1], yHat[srtInd])#绘制原始点的散点图ax.scatter(xMat[:, 1], mat(yArr), s = 2, c = 'red')plt.show()
其中lwlr()函数是算法的核心实现,plotData()函数是综合了几个函数的功能的一个整合函数,并且把原始数据和拟合后的曲线用图形化显示,能够更加直观的看到算法的拟合效果。传入plotData()三种不同的K值得到的效果如下:


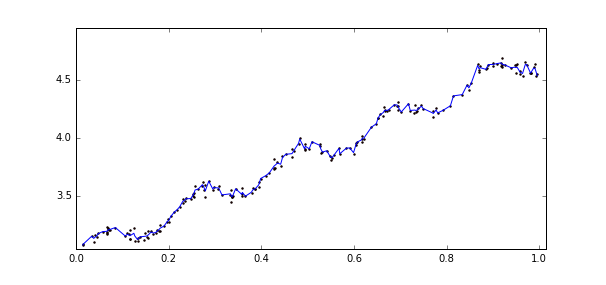
上图中的k=1,中图k=0.01,下图k=0.003,可以看到图一依然是欠拟合的;图二模型已经能够很好地表达原始数据的变化趋势和潜在规律;而图三已经把噪声点考虑在内了,造成了一定程度上过拟合。
总结
至此,局部加权线性回归的基本原理和实现方式已经理清楚了,总结一下步骤:
step1:对于需要查询的输入x,找到其领域的训练样本
step2:对于领域的训练集赋予更大的权重,求取回归系数w使得
![]()
最小,其中W(i)为权重值
step3:预测输出:wx
step4:对于新的输入,重复1-3
从步骤中可以看出,这个算法是一个非参数学习算法( non-parametric learning algorithm),非参数学习算法每次预测值的时候都要重新训练数据得到新的参数值才能计算预测输出。算法所需要的计算量根据需要查询的输入的数量呈线性增加。
与之对应地,标准线性回归是一种参数学习算法(parametric learning algorithm), 有固定的(指的是:值的大小是固定)、有限的参数,通过训练样本,找到合适的参数后,对于之后未知的输入,我们可以直接利用这组参数得出其相应的预测输出。
上面的推导和代码实现中的LWLR还存在一个很明显的问题,每次对数据集重新训练都要使用整个数据集。而事实上,随着K的变小,远离查询点的数据的权重趋近于0。如果可以避免这些重复且对结果没有影响的计算将会大大减少计算量。所以这里可以像KNN一样只考虑领域中有限的N个训练点,实现真正的“局部”,那么误差准则可以变为:

参考文献
http://blog.csdn.net/allenalex/article/details/16370245
http://www.cnblogs.com/JiePro/p/MachineLearning_2.html
《机器学习实战》
《机器学习》Tom M. Mitchell
保持傻,保持饿

 浙公网安备 33010602011771号
浙公网安备 33010602011771号