
爬虫(1)
一、代理:
1、是采用代理服务器的方式来访问服务器,以防止服务器封住本机的ip地址。
二、urllib库使用:
1、获得response对象:
(1)方法:
(1)status
(2)getheaders()
(3)read()
(4)getheader(headername)
(2)、参数:
(1)data:
2、Request:
三、处理异常:
1、urlerror:
属性:reason
2、httperror:
属性:reason
code
headers
四、parse模块:
1、urlparse: 可以实现 URL 的识别和分段.
2、urlunparse:实现url字段的合并:
3、urlsplit:和urlparse方法相似。
4、urlunsplit:
5、urljoin:
6、urlencode:声明了一个字典,将参数表示出来,然后调用 urlencode() 方法将其序列化为 URL 标准 GET 请求参数。
用于构造get方法的参数值。
7、parse_qs:用于将参数反序列化
8、parse_qsl:将参数反序列化为元组
9、quote():将内容转化为 URL 编码的格式,有时候 URL 中带有中文参数的时候可能导致乱码的问题,所以我们可以用这个方法将中文字符转化为 URL 编码.
10、unquote() :它可以进行 URL 解码
五、robots协议分析:
1、urllib.robotparser.RobotFileParser(url='')
2、
六、requests库:
1、基本使用:
2、高级用法:
(1)文件上传:
requests.post()
将files参数赋值。
(2)设置cookie信息:
在headers参数中设置cookie信息比较简单。
(3)维持会话:
使用Session()函数。
(4)ssl证书验证:
打开时将verify参数为false。
(5)设置代理:
proxies={} 将该参数传递给open函数即可。
(6)网站验证:
使用requests自带的身份验证功能:
1 import requests 2 from requests.auth import HTTPBasicAuth 3 4 r = requests.get('http://localhost:5000', auth=HTTPBasicAuth('username', 'password')) 5 print(r.status_code)
七、正则表达式:
1、匹配规则:

2、re库使用:
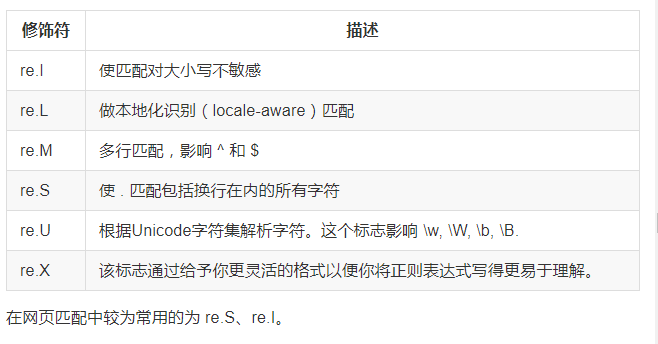
(1)修饰符:
(2)转义匹配:
(3)search方法:
(4)findall() 方法:
(5)sub()
可以将子字符串修改。
(6)compile() 将正则字符串编译成正则表达式编译成正则表达式。

