记一次破解反爬字体加密
背景
之前做了一个采集小说网站,打包成epub的工具,某一天发现新增了字体加密,采集到的文字和实际文字不符,经过观察发现是使用了特别的字体文件。
有几个相似的案例
分析
网页上看起来是这样的,下面一行文字的字体明显和上面不一样。

F12后看到是这样的:

发现添加了一个样式
p:last-of-type {
font-fmaily: "read"!important;
}
此时有两个选择
- 将字体文件一同打包进epub,添加样式
- 对字体文件进行解析,替换成正常的文字
第一种方法是最简单的,但是代价是打包出的epub会大上1.7M,第二种方法会比较复杂,但是效果会很好,我选择了第二种。
解析加密
先拿到字体文件了,文件名为read.woff2。
woff(Web Open Font Format)其实就是 tff 的核心部分进行 zlib 压缩,woff2 也是类似,不过压缩算法更新为 Brotli。
woff2文件在windows上不能打开,但是woff2是ttf核心部分通过Brotli压缩得到的,所以可以转换成ttf文件。
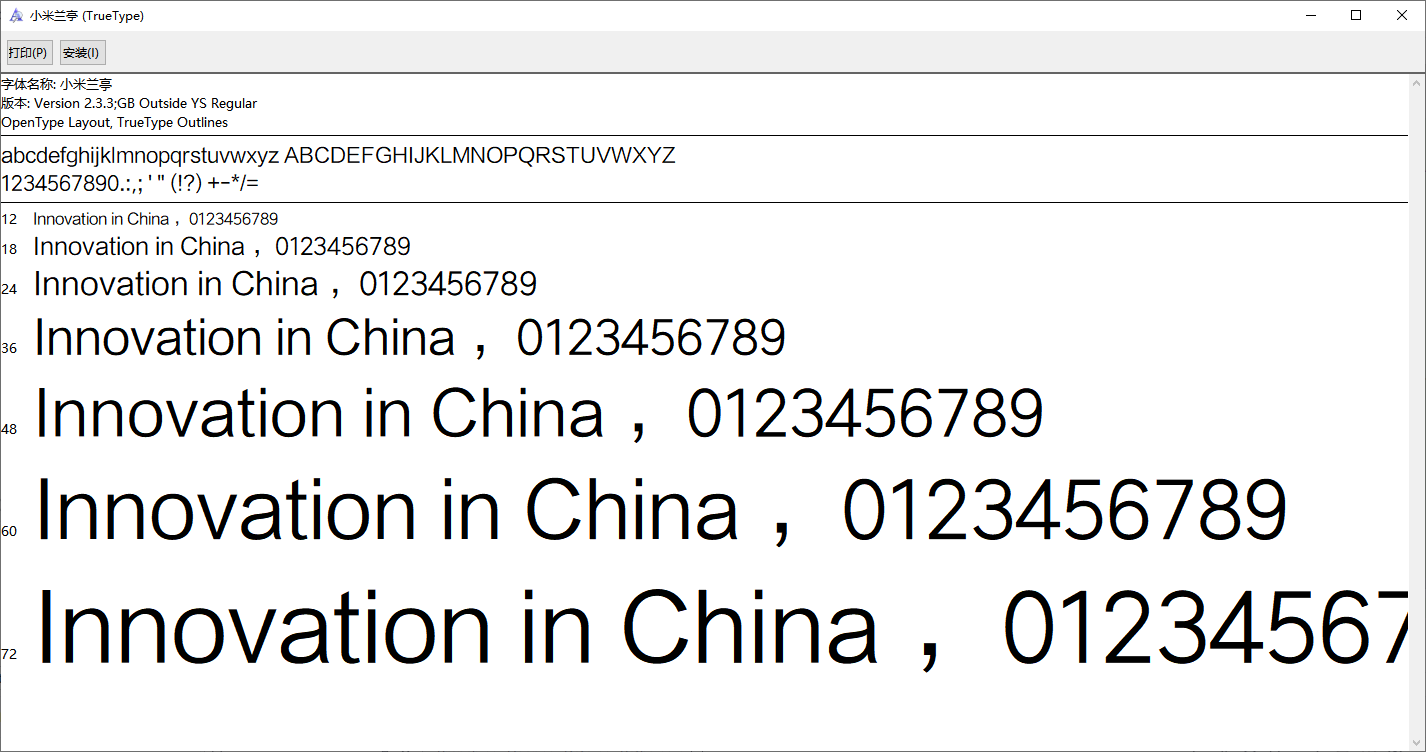
搜索一下很容易就找到在线网站转换了,把woff2转成ttf,转换后文件的体积来到了4M,打开文件后发现字体是小米兰亭,版本号为2.3.3。
我们再回到网页上,看看这段文字到底是啥。将文字拷贝下来后,输出每个文字的unicode编码。
在浏览器的控制台输入函数的代码,并拷贝加密后的文字作为参数。
function getUnicode(str) {
for (var i = 0; i < str.length; i++) {
var unicode = "\\u" + parseInt(str.charCodeAt(i)).toString(16);
console.log("index", i, "char", str[i], "unicode", unicode);
}
}
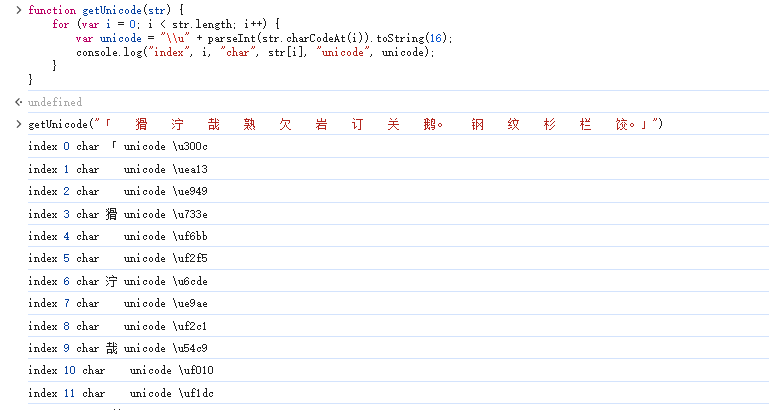
我们姑且称这段奇怪的文字为密文,网页上正常显示的文字为明文,——虽然这应该不是加密。
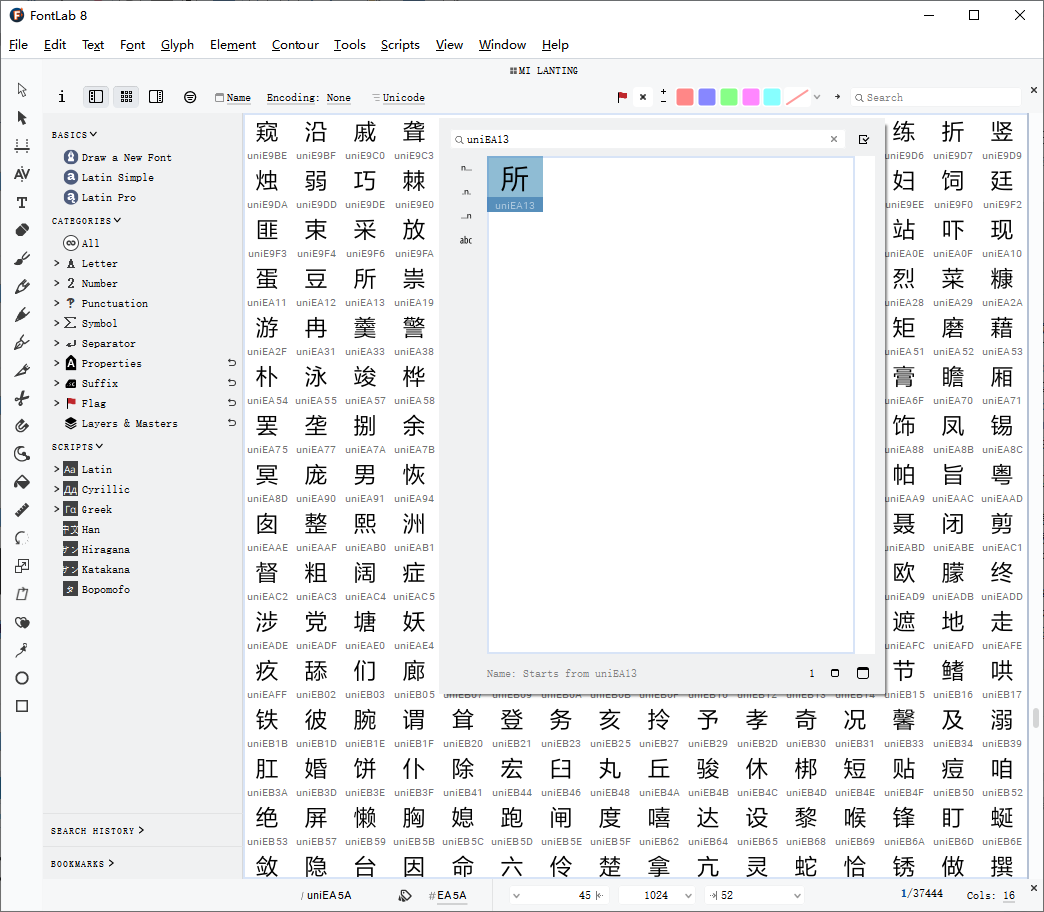
然后回到网页,先拷贝一个所字,用方法输出看一看,看起来是空白字符,发现其unicode为\uea13
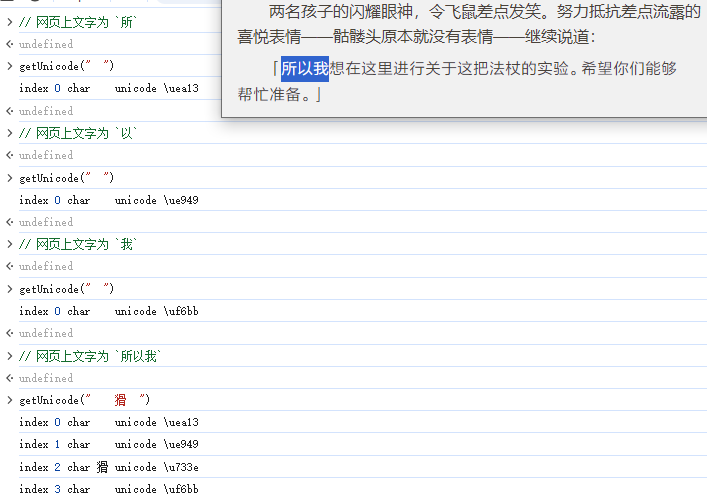
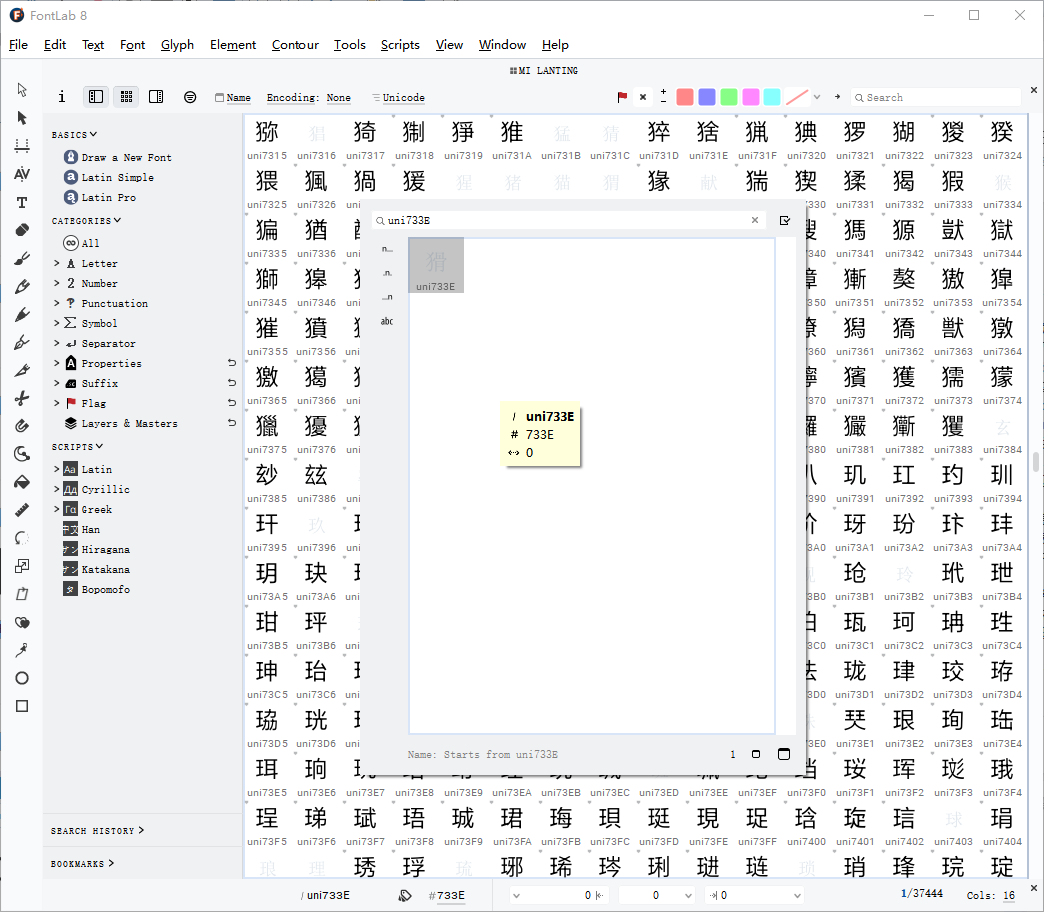
发现拷贝单个文字时会输出一个unicode,但是拷贝3个字时会输出4个unicode,所以\u733e在字体中是不显示的。
用FontLab打开字体文件,Ctrl+F搜索uniEA13,即unicode\uea13,发现与网页显示一致。
搜索uni733E,发现没有字形,背景应该是默认字体显示出来的。
可以发现,网页上加密的文字都是中文汉字,而中文的unicode范围为\u4E00 - \u9FA5。
查看字体文件,发现从4E00-9FA5范围内都多为空白字形和错误字形,而E000-FA29范围内都是完整的文字,FA29往后都是字母数字和笔画等。
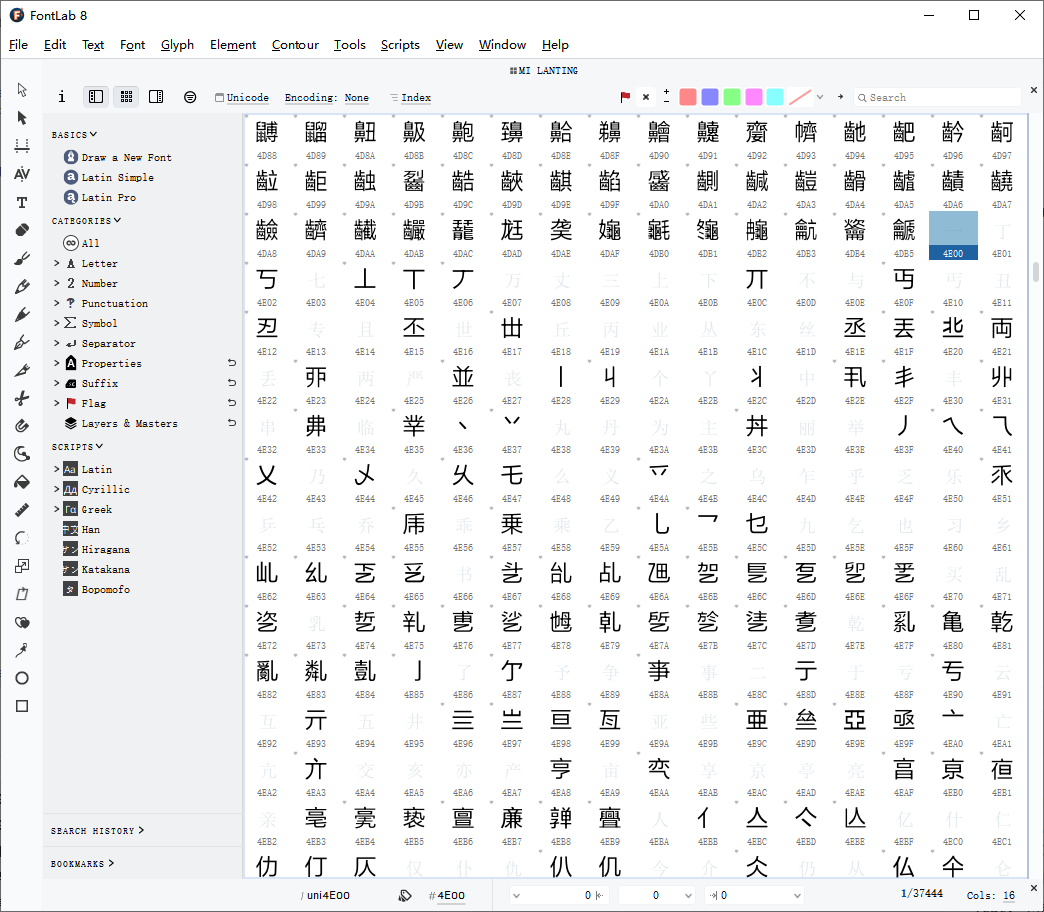
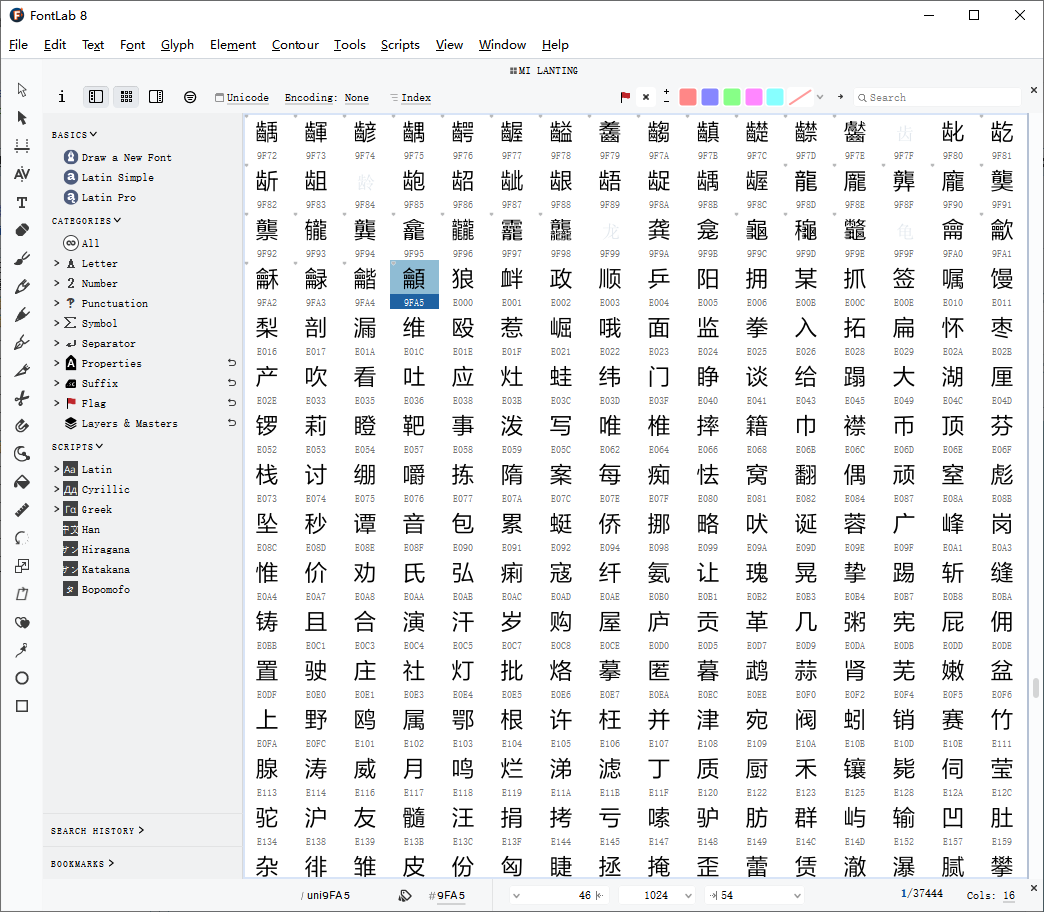
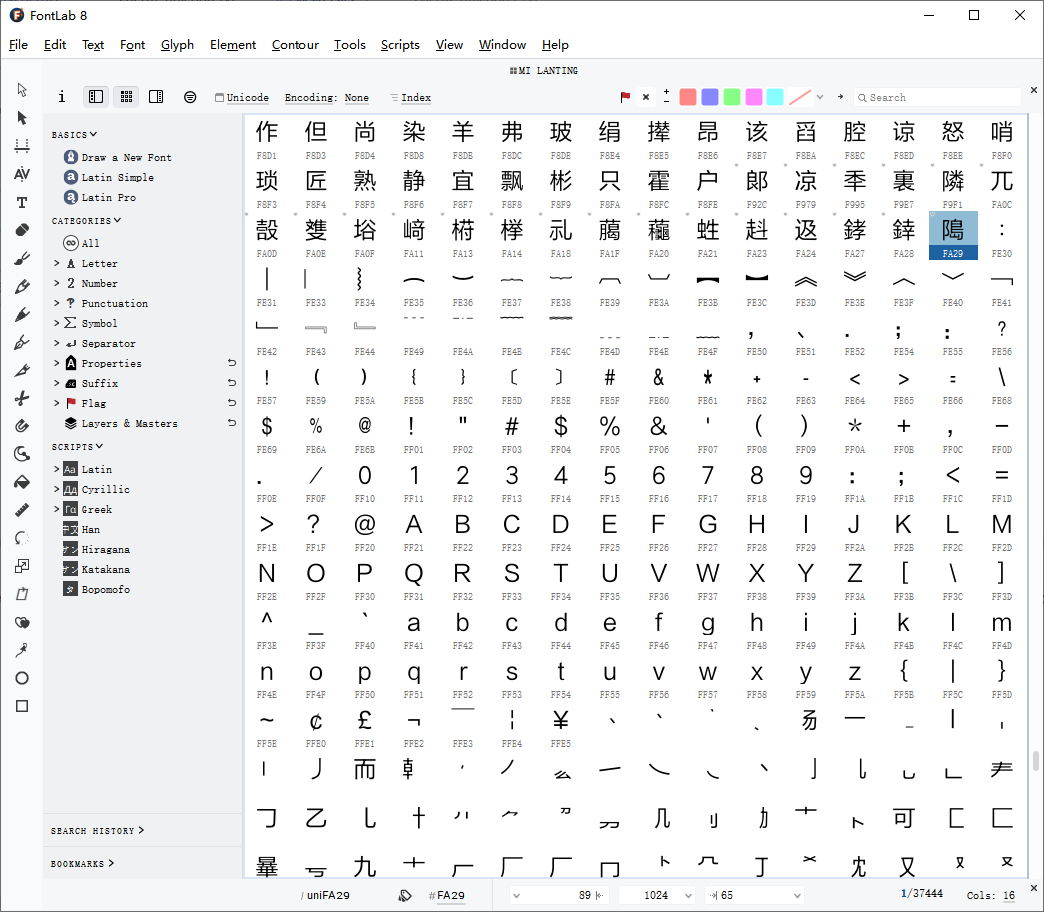
大致确认正确字形的unicode范围为E000-FA29,要如何得到正确的unicode映射?
加密字体是由小米兰亭字体修改而来,如果我们能用正确的小米兰亭中的字形与加密字体中的正确字形范围进行对比,就能得到加密字体unicode与实际unicode的映射。
编写代码获取映射
这里我使用java来编写,仅供参考。
添加maven依赖,如果依赖无法安装要在maven中配置镜像。
<!-- https://mvnrepository.com/artifact/org.apache.pdfbox/pdfbox -->
<dependency>
<groupId>org.apache.pdfbox</groupId>
<artifactId>pdfbox</artifactId>
<version>3.0.3</version>
</dependency>
<!-- https://mvnrepository.com/artifact/cn.hutool/hutool-all -->
<dependency>
<groupId>cn.hutool</groupId>
<artifactId>hutool-all</artifactId>
<version>5.8.27</version>
</dependency>
编写对比代码,进行简单的字形对比,其中read.ttf文件为加密的字体文件,Miui-Regular.ttf为小米兰亭字体,结果会输出到result.txt中。
import cn.hutool.core.io.FileUtil;
import cn.hutool.core.io.resource.ResourceUtil;
import org.apache.fontbox.ttf.CmapLookup;
import org.apache.fontbox.ttf.GlyphData;
import org.apache.fontbox.ttf.TTFParser;
import org.apache.fontbox.ttf.TrueTypeFont;
import org.apache.pdfbox.io.RandomAccessReadBuffer;
import java.io.BufferedWriter;
import java.io.File;
import java.io.IOException;
import java.io.InputStream;
import java.nio.charset.StandardCharsets;
import java.util.*;
import java.util.stream.Collectors;
import java.util.stream.IntStream;
public class Main {
// 正确字体的中文unicode范围
public static final int CHINESE_UNICODE_FORM = 0x4E00;
public static final int CHINESE_UNICODE_TO = 0x9FA5;
// 加密字体的unicode范围
public static final int SECRET_UNICODE_FROM = 0xE000;
public static final int SECRET_UNICODE_TO = 0xFA29;
public static void main(String[] args) throws IOException {
Map<Integer, List<Integer>> secretMap = new HashMap<>();
List<Integer> secretUnicodeList = IntStream.range(SECRET_UNICODE_FROM, SECRET_UNICODE_TO).boxed().toList();
TrueTypeFont secretFont = readFont("read2.ttf");
TrueTypeFont miuiFont = readFont("Miui-Regular.ttf");
CmapLookup secretLookUp = secretFont.getUnicodeCmapLookup();
CmapLookup normalLookup = miuiFont.getUnicodeCmapLookup();
for (Integer secretUnicode : secretUnicodeList) {
int secretGlyphId = secretLookUp.getGlyphId(secretUnicode);
GlyphData secretGlyph = secretFont.getGlyph().getGlyph(secretGlyphId);
for (int normalUnicode = CHINESE_UNICODE_FORM; normalUnicode <= CHINESE_UNICODE_TO; normalUnicode++) {
int normalLookupGlyphId = normalLookup.getGlyphId(normalUnicode);
GlyphData normalGlyph = miuiFont.getGlyph().getGlyph(normalLookupGlyphId);
if (equal(secretGlyph, normalGlyph)) {
List<Integer> list = secretMap.computeIfAbsent(secretUnicode, k -> new ArrayList<>());
list.add(normalUnicode);
}
}
}
Map<Integer, Integer> sizeMap = secretMap.entrySet().stream().collect(Collectors.toMap(Map.Entry::getKey, e -> e.getValue().size()));
List<Integer> moreThanOne = sizeMap.entrySet().stream().filter(e -> e.getValue() > 1).map(Map.Entry::getKey).toList();
List<Integer> noneMap = sizeMap.entrySet().stream().filter(e -> e.getValue() <= 0).map(Map.Entry::getKey).toList();
if (moreThanOne.isEmpty() && noneMap.isEmpty()) {
File file = FileUtil.file("result.txt");
BufferedWriter writer = FileUtil.getWriter(file, StandardCharsets.UTF_8, true);
System.out.println(file.getAbsolutePath());
Set<Map.Entry<Integer, List<Integer>>> entries = secretMap.entrySet();
for (Map.Entry<Integer, List<Integer>> entry : entries) {
Integer key = entry.getKey();
List<Integer> value = entry.getValue();
String secretUnicode = Integer.toHexString(key);
String normalUnicode = Integer.toHexString(value.get(0));
writer.write("\"\\u" + secretUnicode + "\": " + "\"\\u" + normalUnicode + "\",");
}
writer.flush();
} else {
System.out.println(moreThanOne);
System.out.println(noneMap);
}
}
public static TrueTypeFont readFont(String name) throws IOException {
InputStream inputStream = ResourceUtil.getStream(name);
TTFParser parser = new TTFParser();
return parser.parse(new RandomAccessReadBuffer(inputStream));
}
private static boolean equal(GlyphData glyph1, GlyphData glyph2) {
boolean b1 = glyph1.getXMaximum() == glyph2.getXMaximum() &&
glyph1.getXMinimum() == glyph2.getXMinimum() &&
glyph1.getYMaximum() == glyph2.getYMaximum() &&
glyph1.getYMinimum() == glyph2.getYMinimum() &&
glyph1.getNumberOfContours() == glyph2.getNumberOfContours();
boolean b2 = glyph1.getDescription().getPointCount() - glyph2.getDescription().getPointCount() == 0;
return b1 && b2;
}
}
最后查看结果

用JS查看一下,一共3500个键值对,数量非常整数,说明应该没有问题。

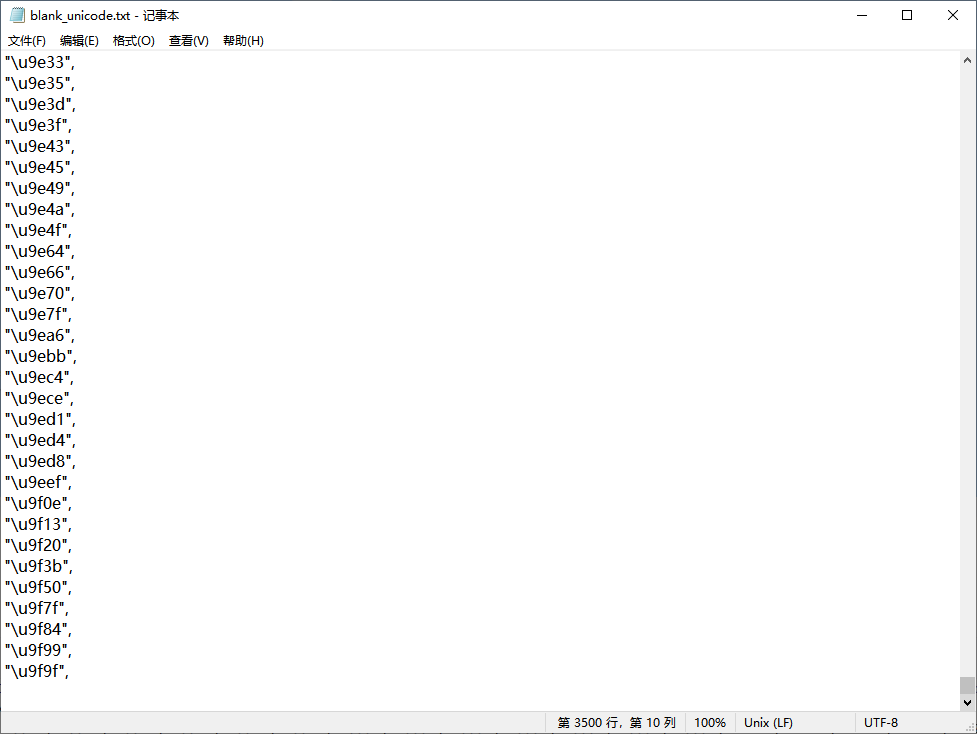
同时在加密字体中还有无字形的,我们需要把他找出来,同样编写代码找出无字形的unicode,结果会写出到blank_unicode.txt。
import cn.hutool.core.io.FileUtil;
import org.apache.fontbox.ttf.CmapLookup;
import org.apache.fontbox.ttf.GlyphData;
import org.apache.fontbox.ttf.TrueTypeFont;
import java.io.BufferedWriter;
import java.io.File;
import java.io.IOException;
import java.nio.charset.StandardCharsets;
import java.util.ArrayList;
import java.util.List;
public class Main2 {
public static void main(String[] args) throws IOException {
TrueTypeFont font = Main.readFont("read.ttf");
List<Integer> emptyUnicode = new ArrayList<>();
CmapLookup lookup = font.getUnicodeCmapLookup();
File file = FileUtil.file("blank_unicode.txt");
BufferedWriter writer = FileUtil.getWriter(file, StandardCharsets.UTF_8, true);
for (int unicode = Main.CHINESE_UNICODE_FORM; unicode <= Main.CHINESE_UNICODE_TO; unicode++) {
int glyphId = lookup.getGlyphId(unicode);
GlyphData glyph = font.getGlyph().getGlyph(glyphId);
if (emptyGlyphData(glyph)) {
emptyUnicode.add(unicode);
String hex = "\\u" + Integer.toHexString(unicode);
writer.write("\"" + hex + "\",\n");
}
}
writer.flush();
System.out.println(file.getAbsolutePath());
System.out.println(emptyUnicode);
}
public static boolean emptyGlyphData(GlyphData glyph) {
return glyph.getXMinimum() == 0 && glyph.getYMinimum() == 0 &&
glyph.getXMaximum() == 0 && glyph.getYMaximum() == 0;
}
}
查看结果,也是3500个,数量和之前相同,证明没有问题。
最后就是把这两个数据应用到开头说的工具上了,这里不细说,没有问题。

