
Ubantu 安装 TensorFlow 详细教程
不要使用python2 安装,
不要使用python2 安装,
不要使用python2 安装,
使用清华镜像, 会快很多:
pip install tensorflow==1.8 -i https://pypi.tuna.tsinghua.edu.cn/simple使用清华镜像, 会快很多:
pip install tensorflow==1.8 -i https://pypi.tuna.tsinghua.edu.cn/simple使用清华镜像, 会快很多:
pip install tensorflow==1.8 -i https://pypi.tuna.tsinghua.edu.cn/simple1、安装 Python3
1)查看系统所安装的python版本
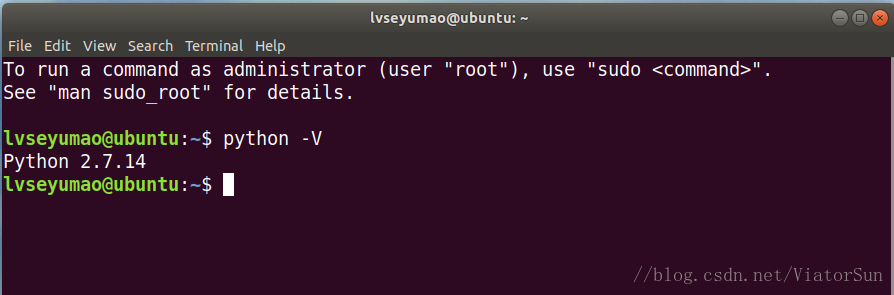
打开终端(快捷键:Ctrl+Alt+T)输入指令:python -V (大写 V)或者python --version(两个横线),如图所示,我的系统是ubuntu18.04,默认安装的python版本为2.7.14。
2)安装最新 Python3
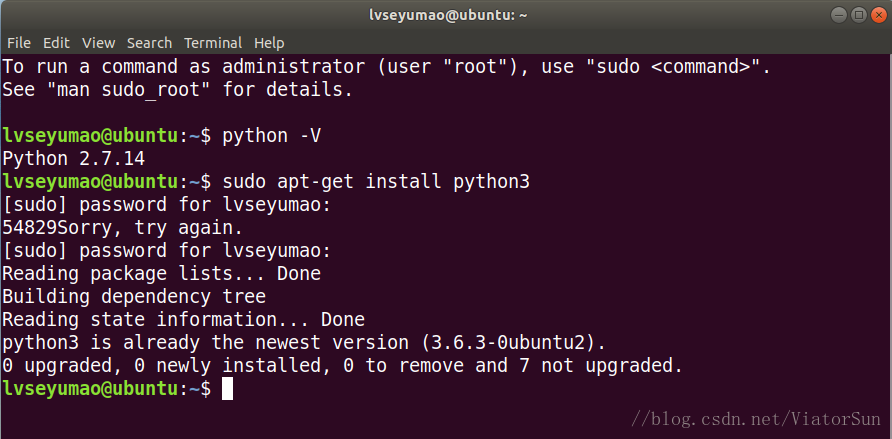
通过命令行sudo apt-get install python3 即可安装最新版本的Python3:
由于我之前更新过Ubuntu,所以提示安装0个安装包
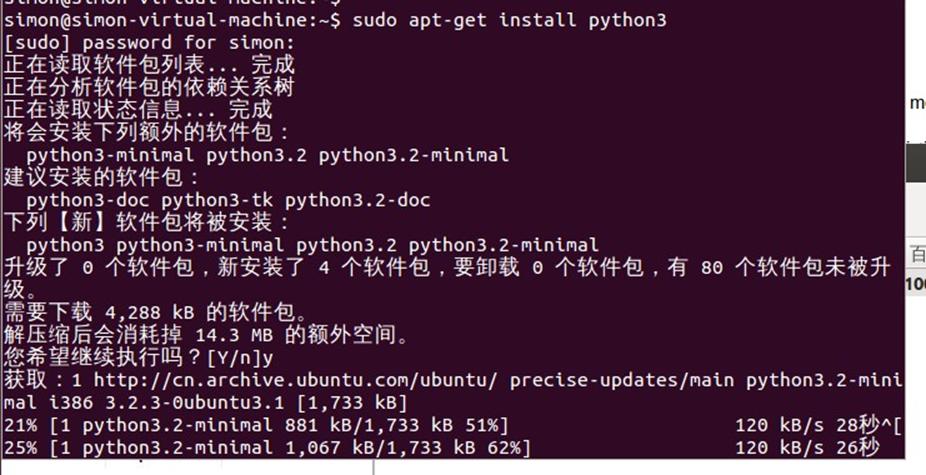
系统不自带Python3的情况如下:
刚才的Python3是被默认安装带usr/local/lib/python3.6目录中,如下

由于Ubuntu很多底层采用的是Python2.*,而Python2和Python3是互相不兼容的,所以此时不能卸载Python2,需要将默认Python的指向Python3
3)重指定系统默认 Python
在命令提示符中输入:sudo rm /usr/bin/python 移除默认的python2.7
输入:sudo ln -s /usr/bin/python3.6 /usr/bin/python 指定python3.6为默认python
并通过:python -V 检查系统默认指定Python版本
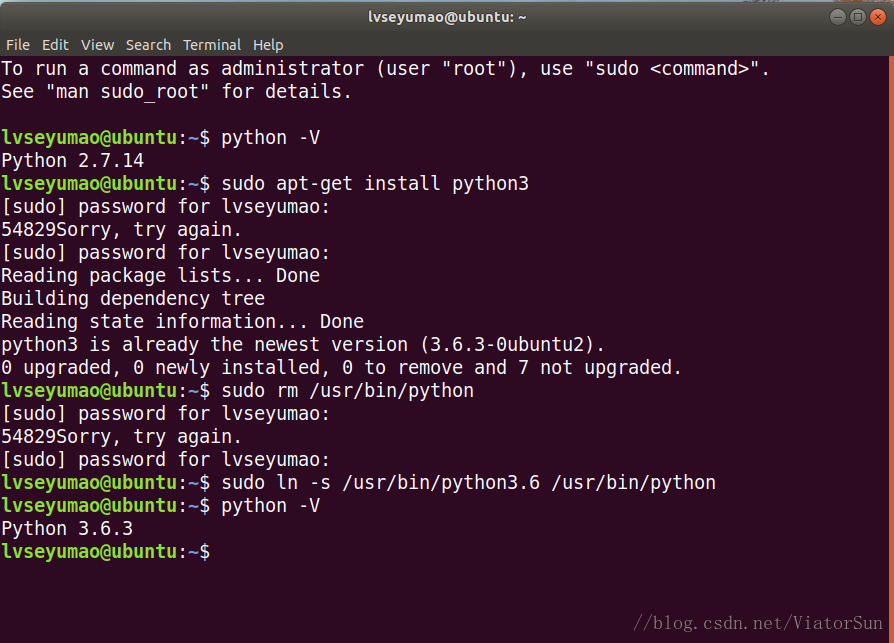
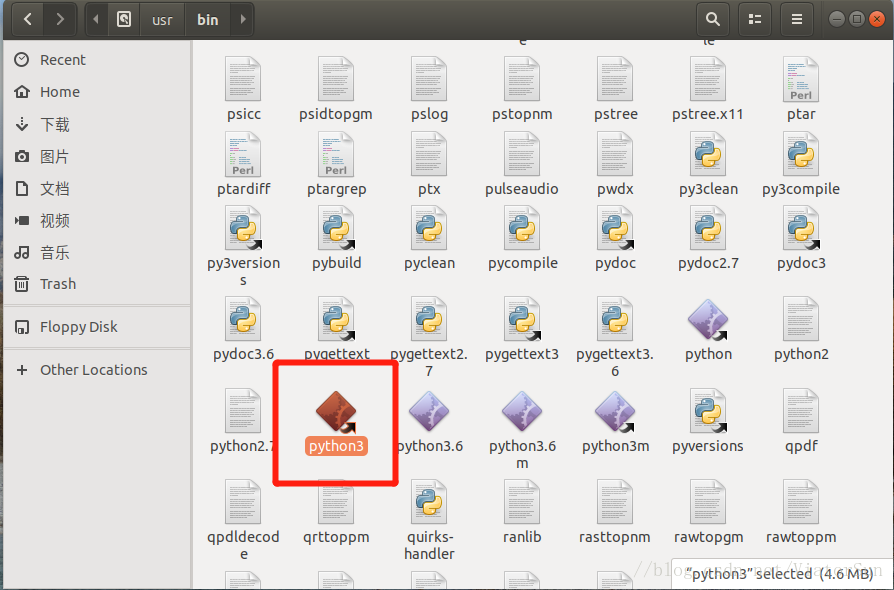
至此,已成功安装python3,并修改系统默认python版本
对于已经安装过Python3的可以通过sudo apt-get install python3来升级Python3到最新版本,然后从新定向Python
sudo mv /usr/bin/python3 /usr/bin/python3-old
sudo ln -s /usr/bin/python3.x /usr/bin/python3
- 1
- 2
2、安装 pip3
pip是一个安装和管理Python包的工具。在pip的帮助下,你可以安装独特版本的包。最重要的是,pip可以通过一个“requirements”的工具来管理一个由包组成的列表和版本号。pip很像easy_install,但是pip有一些额外的特色。
1)更新系统包
sudo apt-get update
sudo apt-get upgrade
- 1
- 2
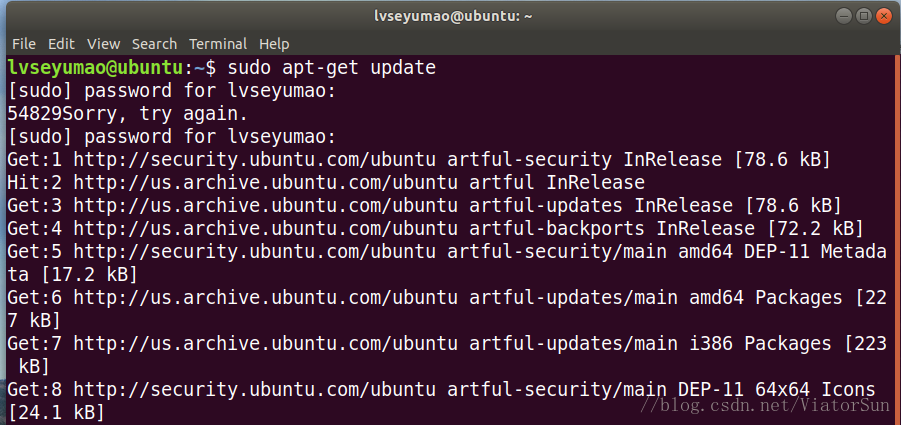
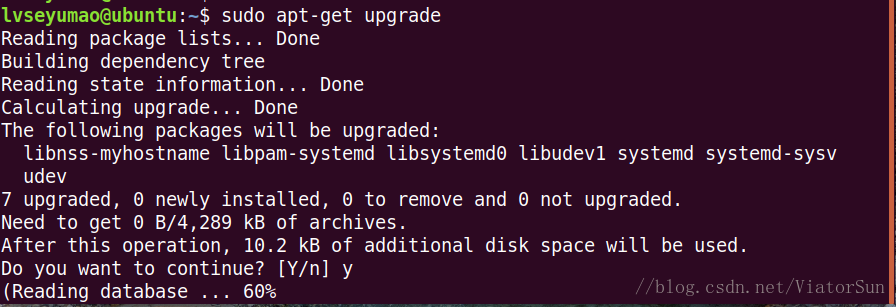
2)安装 pip3
# python2环境下安装pip
# sudo apt-get install pip
# python3环境下安装pip
sudo apt-get install python3-pip
- 1
- 2
- 3
- 4
- 5
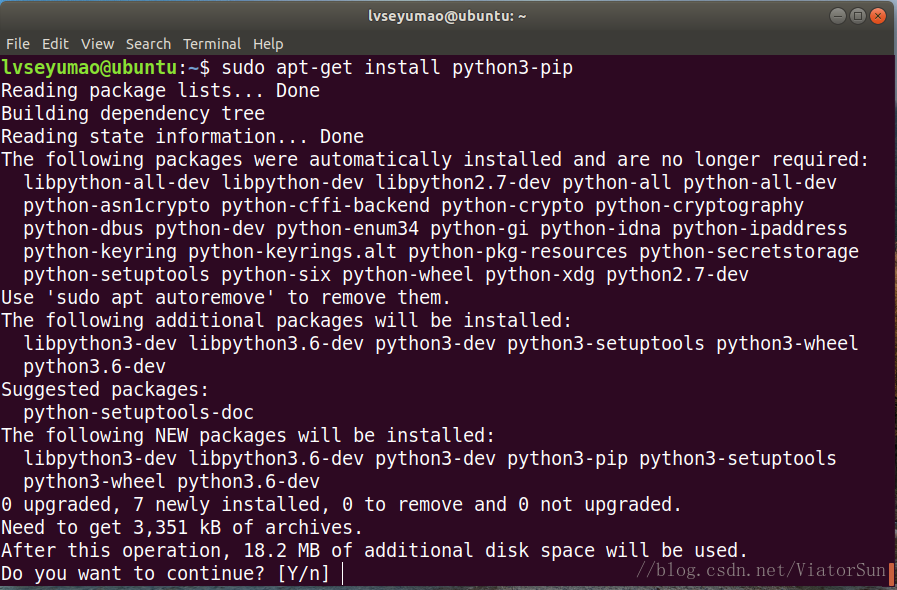
对于已经安装过pip的可以通过以下命令直接升级pip版本
# python 2.7版本:
sudo pip install --upgrade pip
# python 3.x版本:
sudo pip3 install --upgrade pip 3)检查是否安装成功
检查 pip3 是否安装成功
pip3 -V
至此pip3已安装成功
4)卸载旧版本 pip
但有时通过apt-get安装的pip版本太老,使用旧版本pip安装一些包时会报出提醒来升级pip。如果想升级最新的pip,需要先卸载pip,命令为
sudo apt-get remove python-pip
- 1
5)pip 常用命令
- 查看pip帮助:pip -help
- 安装新的python包:pip install packageName
- 卸载python包:pip uninstall packageName
- 寻找python包:pip search packageName
3、安装 vim
系统是没有自带Vim的,需要我们通过以下指令进行安装
sudo apt-get install vim 4、安装 scrapy
scrapy是一个快速高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据,可以用于数据挖掘、检测和自动化测试。
该扩展库具有如下优点:整个爬取过程简单。创建一个类,并定义要删除的项目类型,编写一些从网页中提取数据的规则,结果将以JSON、XML、CSV或其他的格式导出,搜集的数据可以保存在raw,也可以在导入时进行清理。此外scrapy可以扩展允许其他行为例如网站登录处理、会话cookie处理。图像也可被scrapy自动提取并与被抓取的内容进行关联。 总之scrapy是一个很强大的爬虫爬取框架。
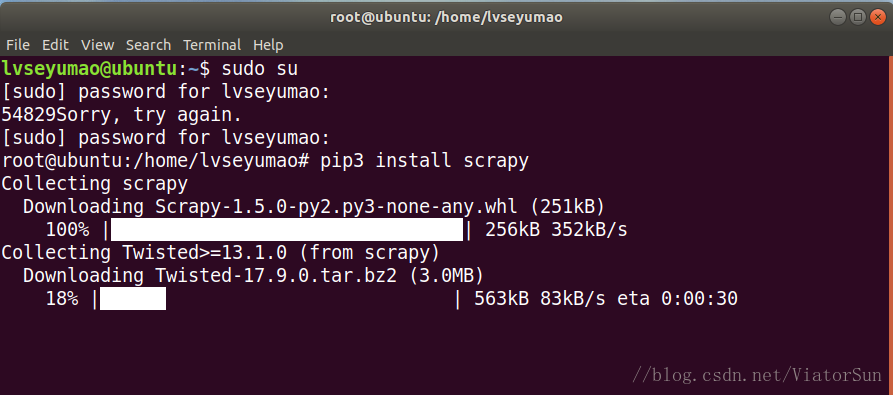
需要在root模式下使用如下命令安装
# 通过sudo su进入到root模式,可能需要输入命令
sudo su
# 通过以下命令安装scrapy
pip3 install scrapy
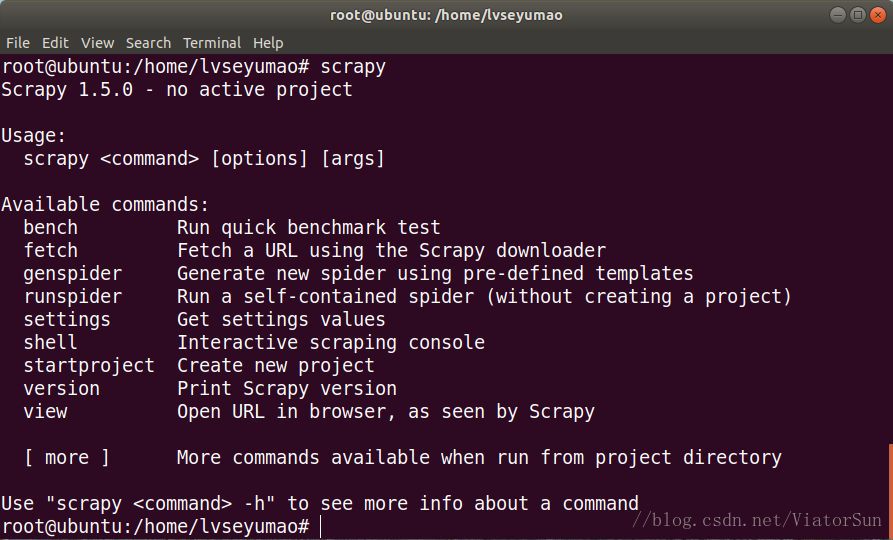
安装完成后输入scrapy显示如下信息即安装成功:
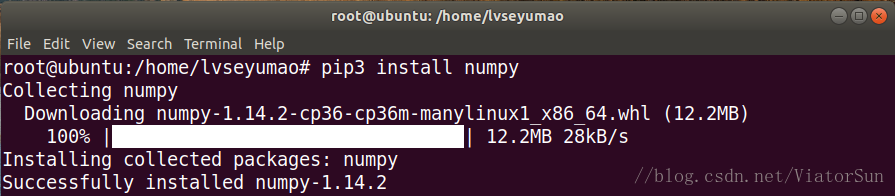
5、安装 numpy
numpy是一个开源的科学计算和数学工作基础包,包括统计学、线性代数、矩阵等
可使用如下命令安装,同样需要取得root权限:
sudo su
pip3 install numpy
6、安装TensorFlow
TensorFlow可以安装CPU和GPU两种版本,对于深度学习GPU运行效率大约是CPU的几倍至几十倍,相同的程序,CPU版可能需要运行一天左右(假设),那么GPU版本可能几个小时就运行完了,而目前跑深度学习的GPU暂时主要是英伟达(NVIDIA)。
1) GPU 版本安装:
GPU安装过程要比CPU安装复杂许多,大致过程有以下几步:
- 更新电脑显卡驱动,直接在更新里面就可以完成;
- 先更改gcc和g++,Ubantu17自带的gcc和g++为7版本的,Tensorflow暂时还不支持这么高的版本,所以首先我们需要将gcc和g++降低版本(gcc和g++的作用如同windows里的vc和vs一样,为c和c++编译器,而gcc和g++就是Ubantu里的c和c++编译器);
- 安装CUDA,CUDA是英伟达专门为GPU计算推出的计算平台,从CUDA3.0开始已经支持C++和FORTRAN,所以上面我们需要将gcc和g++调整到CUDA支持的版本;
- 安装cuDNN,cuDNN是英伟达为CUDA加速运算推出的加速库,用于在GPU上实现高性能现代并行计算;
- 最后安装Tensorflow-GPU
如果有不理解CUDA和cuDNN的同学,可以查看这篇文章:https://blog.csdn.net/fangjin_kl/article/details/53906874
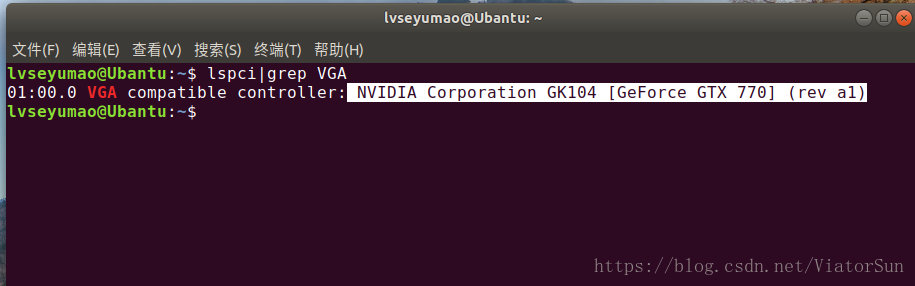
而如何才能知道自己的电脑是否支持TensorFlow的GPU版本,需要查看自己的电脑硬件配置,如果查看电脑硬件不太方便的话,可以通过以下命令查看Ubantu显卡的型号:
lspci|grep VGA
- 1
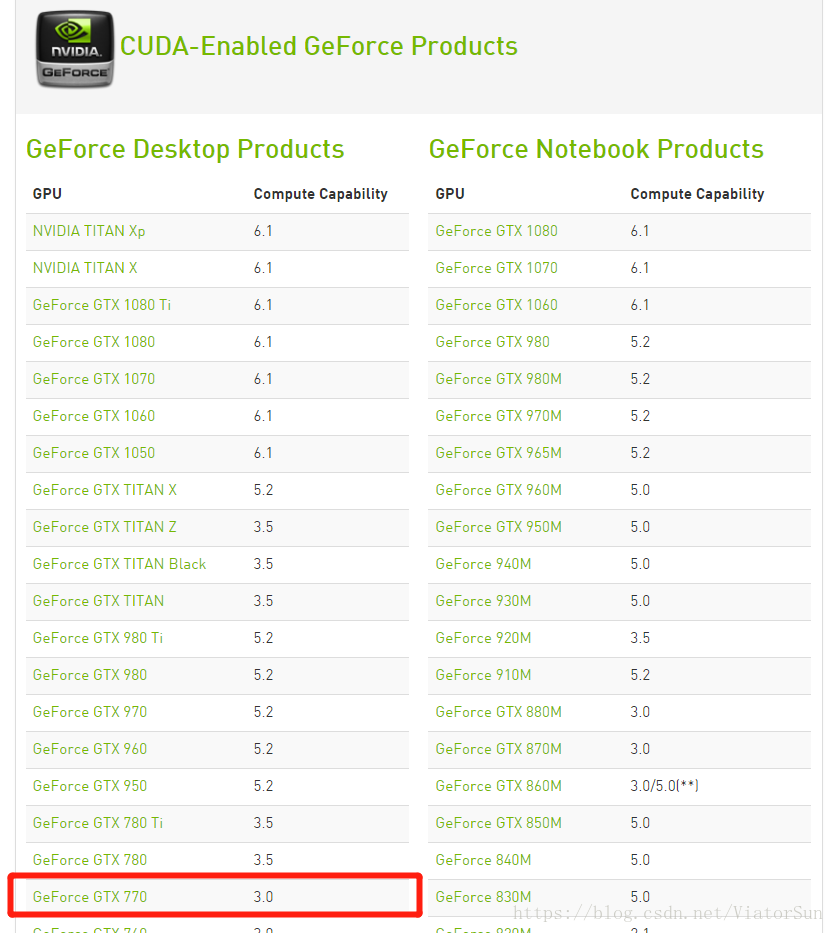
知道了显卡,如何知道自己的显卡是否支持深度学习呢?这里可以通过访问英伟达官网查看:https://developer.nvidia.com/cuda-gpus

上面我们已经查看到了电脑的GPU型号为:NVIDIA GeForce GTX 770,所以直接在GeForce系列里查找就可以了,结果如下图:
GPU版本安装命令如下:
具体安装教程请参考https://blog.csdn.net/dream_an/article/details/74992346
2)CPU 版本安装命令如下:
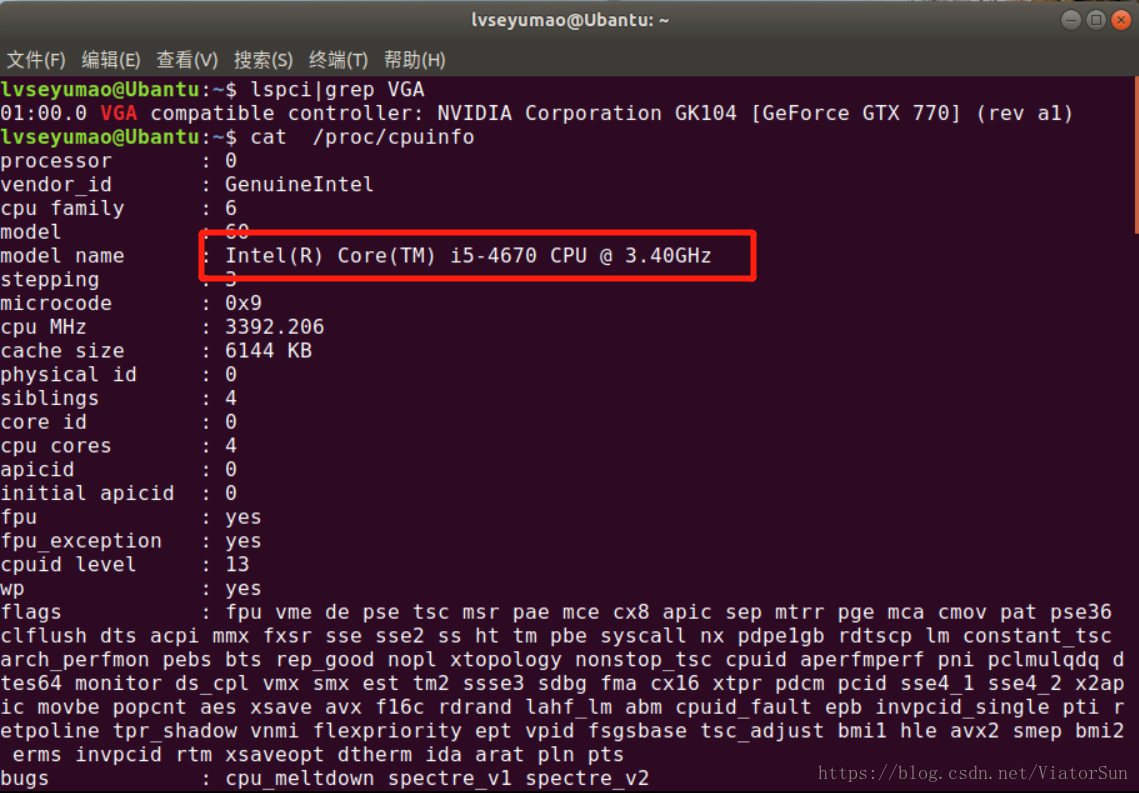
CPU性能虽然不如GPU效率高,但是GPU也不是常有的,所以CPU版本的更适用没有很好地独立显卡的小伙伴们,CPU的各个系列型号的性能也是不尽相同的,通过以下指令可以直接查看电脑的CPU信息:
CPU版本的TensorFlow安装也很简单,命令如下:
# python 2.7版本:
sudo pip install tensorflow
# python 3.x版本:
sudo pip3 install tensorflow
- 1
- 2
- 3
- 4
若上述命令执行过程没有报错,则安装成功
若提示错误,请检查网络,重试上述命令
3)卸载Tensorflow
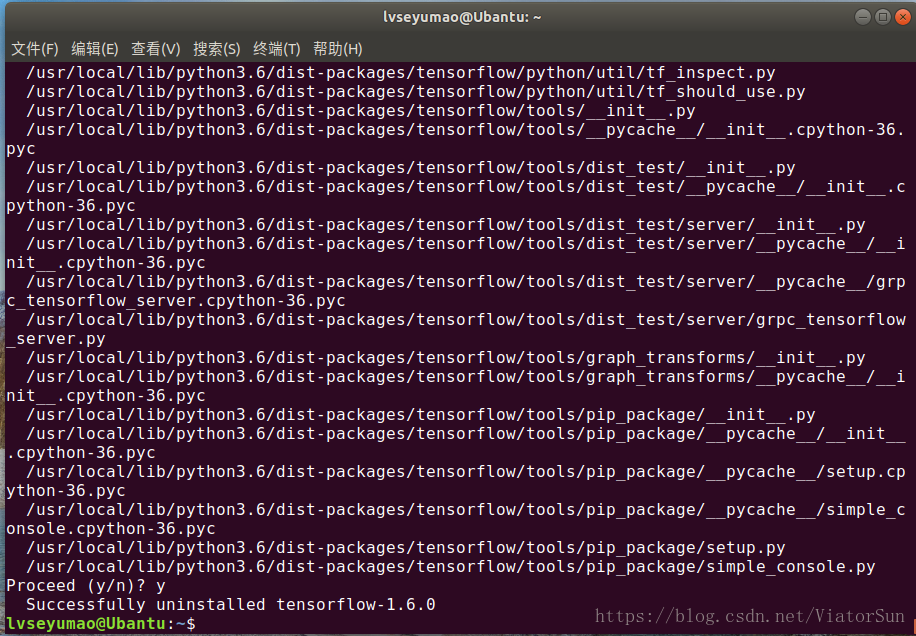
如果刚开始安装了CPU版本的TensorFlow,后来发现GPU支持,那么需要先卸载CPU版本的TensorFlow,命令如下:
sudo pip uninstall tensorflow
使用清华镜像, 会快很多:
pip install tensorflow==1.8 -i https://pypi.tuna.tsinghua.edu.cn/simple 成功卸载效果为:
7、测试安装结果
进入python编译环境,导入TensorFlow,做一个简单的加法运算,如图所示。
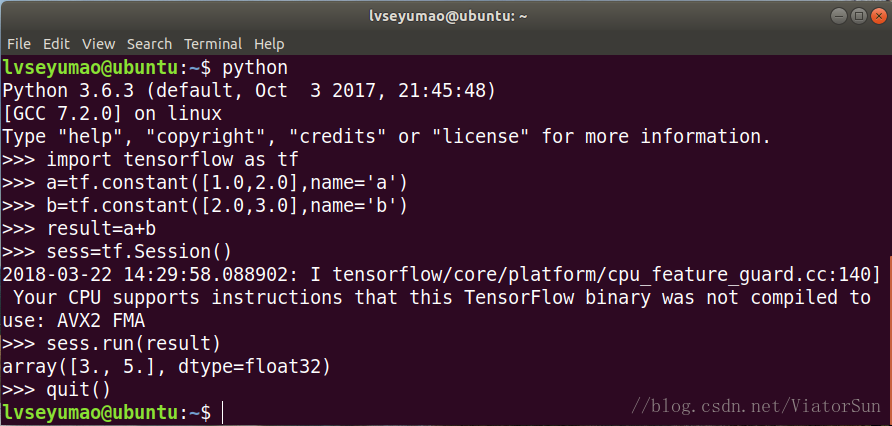
最后恭喜你,已经安装成功了

