HDFS 编程实践(Hadoop3.1.3)
一、使用 Eclipse 开发调试 HDFS Java 程序
- 实验任务:
- 在分布式文件系统中创建文件并用 shell 指令查看;
- 利用 Java API 编程实现判断文件是否存在以及合并两个文件的内容成一个文件。
1、创建文件
- 首先启动 hadoop,命令:
$ cd /usr/local/hadoop/ ; $ ./sbin/start-dfs.sh,如图:

- 在本地 Ubuntu 文件系统的
/home/Hadoop/目录下创建两个文件 file_a.txt、file_b.txt:
$ touch /home/Hadoop/file_a.txt
$ touch /home/Hadoop/file_b.txt
- 把本地文件系统的
/home/Hadoop/file_a.txt、/home/Hadoop/file_b.txt上传到 HDFS 中的当前用户目录下,即上传到 HDFS 的/user/hadoop/目录下:
./bin/hdfs dfs -put /home/Hadoop/file_a.txt
./bin/hdfs dfs -put /home/Hadoop/file_b.txt
- 在文件里编辑内容:
gedit /home/Hadoop/file_a.txt
gedit /home/Hdaoop/file_b.txt
- 查看文件是否上传成功:
./bin/hdfs dfs -ls

可以看到,以上两个文件已经上传成功。 - 读取文件内容:
./bin/hdfs dfs -cat file_a.txt
./bin/hdfs dfs -cat file_b.txt

上图暂时有个报错,我们可以看到,两个文件的读取已经成功。
2、利用Java API 编程实现
在 Eclipse 中创建项目
- 启动 Eclipse,启动后,会弹出如下图所示的界面,提示设置工作空间(workspace)
直接采用默认设置,点击 OK 即可。 - Eclipse 启动后,会出现如下界面:
- 创建一个 Java Project,选择“File-->New-->Java Project”,名字自拟。
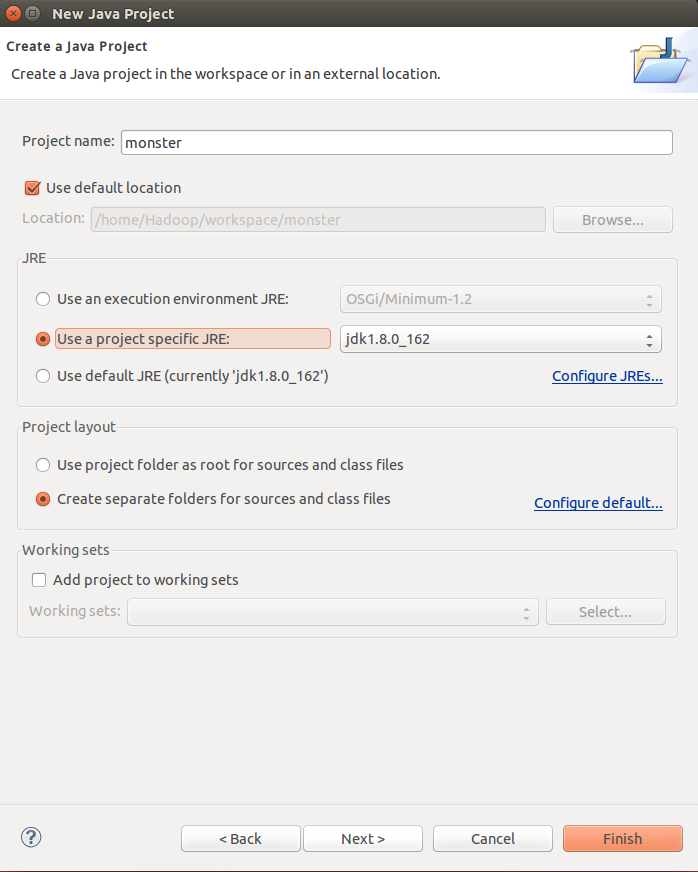
选中“Use default location”,让这个Java工程的所有文件都保存在“/home/Hadoop/workspace/monster”目录下。在“JRE”这个选项中,选择之前已经安装好的JDK:jdk1.8.0_162。点击Next,进入下一步。
为项目添加需要用到的JAR包
当点击下一步之后,会看到如下界面:

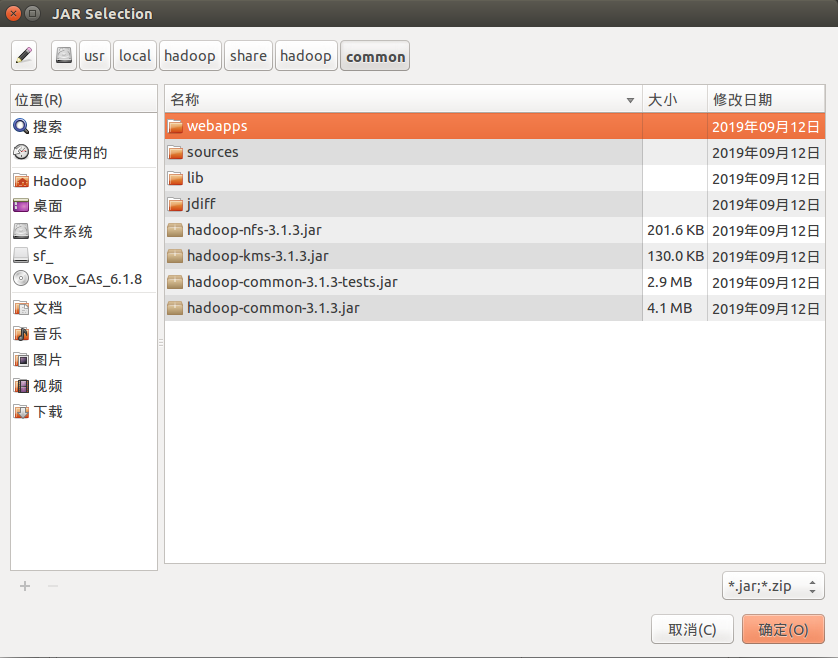
此时需要加载该 Java 工程所需要的 JAR 包,这些 JAR 包含可以访问 HDFS 的 Java API。这些 JAR 包位于 Linux 系统的 Hadoop 安装目录下,在 “/usr/local/hadoop/share/hadoop” 目录下。点击 "Libraries" 选项卡, 然后点击 "Add External JARS...",会弹出如下图界面:
为了编写一个能够与 HDFS 交互的 Java 应用程序,一般需要向 Java 工程中添加以下 JAR 包:
(1)“/usr/local/hadoop/share/hadoop/common” 目录下的所有 JAR 包,包括hadoop-common-3.1.3.jar、hadoop-common-3.1.3-tests.jar、haoop-nfs-3.1.3.jar 和 haoop-kms-3.1.3.jar,注意,不包括目录 jdiff、lib、sources和webapps;
(2)“/usr/local/hadoop/share/hadoop/common/lib” 目录下的所有 JAR 包;
(3)“/usr/local/hadoop/share/hadoop/hdfs” 目录下的所有 JAR 包,注意,不包括目录jdiff、lib、sources和webapps;
(4)“/usr/local/hadoop/share/hadoop/hdfs/lib” 目录下的所有 JAR 包。
现在,我们把 “/usr/local/hadoop/share/hadoop/common” 目录下的hadoop-common-3.1.3.jar、hadoop-common-3.1.3-tests.jar、haoop-nfs-3.1.3.jar 和 haoop-kms-3.1.3.jar 添加到当前的 Java 工程中,可以在界面中点击目录按钮,进入到 common 目录,然后,界面会显示出 common 目录下的所有内容(如下图所示):
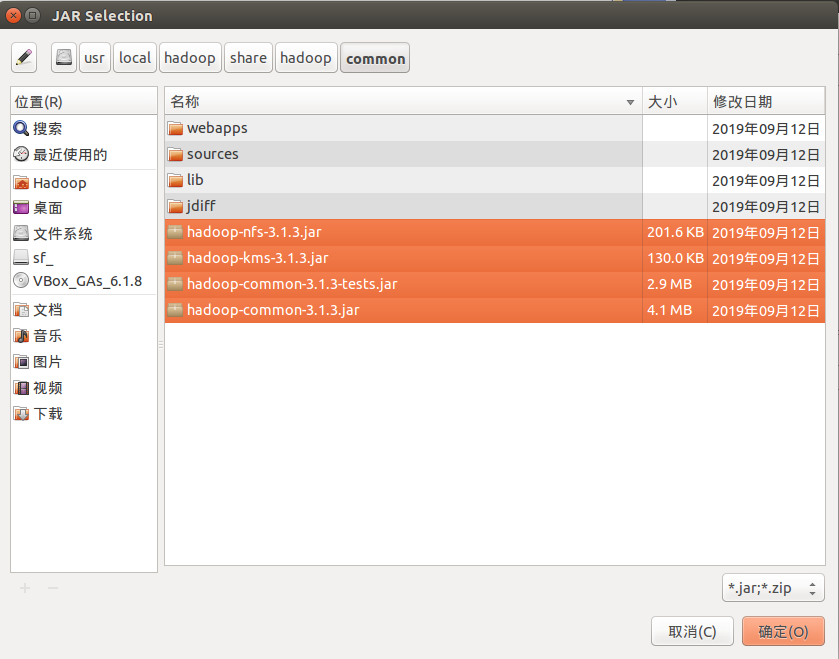
请在界面中用鼠标点击选中 hadoop-common-3.1.3.jar、hadoop-common-3.1.3-tests.jar、haoop-nfs-3.1.3.jar和haoop-kms-3.1.3.jar,然后点击界面右下角的“确定”按钮,就可以把这两个 JAR 包增加到当前 Java 工程中,出现的界面如下图所示。

此时 hadoop-common-3.1.3.jar、hadoop-common-3.1.3-tests.jar、haoop-nfs-3.1.3.jar和haoop-kms-3.1.3.jar已经被添加到当前 Java 工程中。然后,按照类似的操作方法,可以再次点击 "Add External JARs…" 按钮,把剩余的其他JAR包都添加进来。需要注意的是,当需要选中某个目录下的所有 JAR 包时,可以使用 "Ctrl+A" 组合键进行全选操作。全部添加完毕以后,就可以点击界面右下角的 "Finish" 按钮,完成 Java 工程 monster 的创建。
编写 JAVA 应用程序
- 下面编写一个Java应用程序,用来检测HDFS中是否存在一个文件
在工程 monster 上点击右键,点击New-->Class创建两个 Class,如下图:

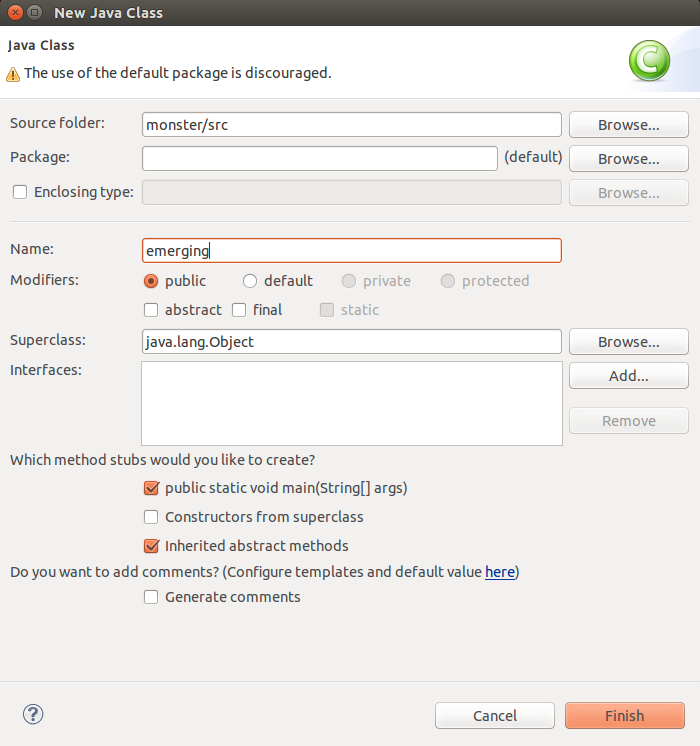

此时,两个类已经建好了,下面我们开始测试。 - 判断文件是否存在
代码如下:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
public class cunzai{
public static void main(String[] args){
try{
String fileNameA = "file_a.txt";
String fileNameB = "file_b.txt";
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://localhost:9000");
conf.set("fs.hdfs.impl", "org.apache.hadoop.hdfs.DistributedFileSystem");
FileSystem fs = FileSystem.get(conf);
if(fs.exists(new Path(fileNameA))){
System.out.println(fileNameA + " 文件存在");
}else{
System.out.println(fileNameA + " 文件不存在");
}
if(fs.exists(new Path(fileNameB))){
System.out.println(fileNameB + " 文件存在");
}else{
System.out.println(fileNameB + " 文件不存在");
}
}catch (Exception e){
e.printStackTrace();
}
}
}
运行代码:选择 Debug As --> Java Application,结果如下:
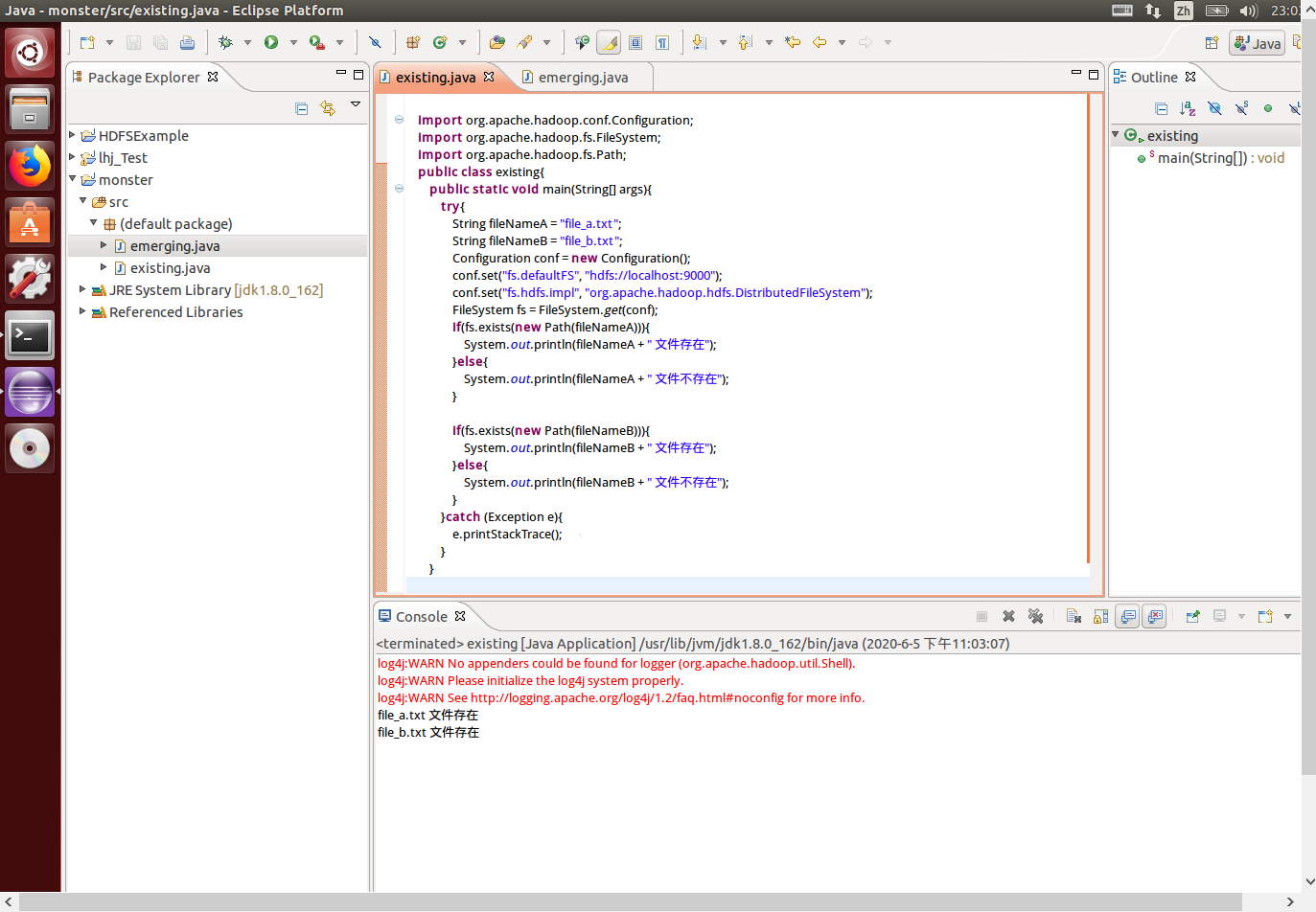
执行成功,下一步将 class 文件按一个可执行 JAR 包的格式导入到 hadoop 路径中,创建一个路径,执行命令: mkdir myapp ,完成后回到 Eclipse 中,右键名为 existing 的 class 类,点击 Export...:
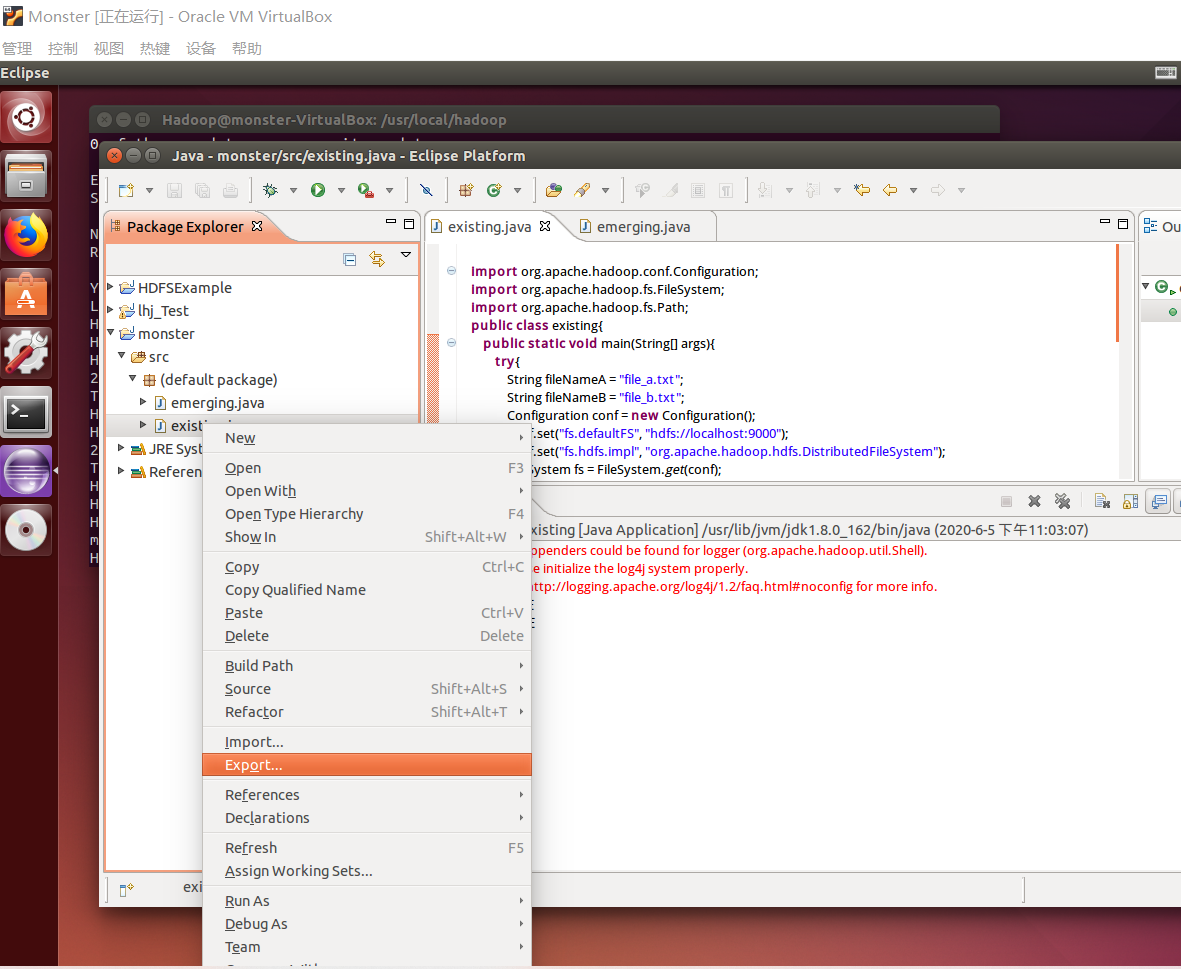
选择:Runnable JAR file:
选择 class 文件名和文件路径,如下图:
点击 ok
再次点击:ok
现在,已经成功导出 jar 包,回到终端检查刚才导出的 jar 包是否能正常运行,执行命令:./bin/hadoop jar ./myapp/existing.jar

成功完成了 jar 包读取文件任务。
- 合并文件
将代码复制到 emerging.class 中:
import java.io.BufferedReader;
import java.io.InputStreamReader;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FSDataOutputStream;
public class hebing {
private static final String utf8 = "UTF-8";
public static void main(String[] args) {
try {
Configuration conf = new Configuration();
conf.set("fs.defaultFS","hdfs://localhost:9000");
conf.set("fs.hdfs.impl","org.apache.hadoop.hdfs.DistributedFileSystem");
FileSystem fs = FileSystem.get(conf);
Path fileA = new Path("file_a.txt");
Path fileB = new Path("file_b.txt");
FSDataInputStream getItA = fs.open(fileA);
FSDataInputStream getItB = fs.open(fileB);
BufferedReader dA = new BufferedReader(new InputStreamReader(getItA));
BufferedReader dB = new BufferedReader(new InputStreamReader(getItB));
String contentA = dA.readLine(); //读取文件一行
System.out.println(contentA);
String contentB = dB.readLine(); //读取文件一行
System.out.println(contentB);
String mem = new String();
mem = contentA+contentB;
String filename = "test_merge.txt"; //要写入的文件名
FSDataOutputStream os = fs.create(new Path(filename));
os.writeUTF(mem);
System.out.println("Create: "+ filename);
os.close(); //关闭文件os
dA.close(); //关闭文件A
dB.close(); //关闭文件B
fs.close(); //关闭hdfs
} catch (Exception e) {
e.printStackTrace();
}
}
}
运行代码,结果如下:

将这个 class 导出:
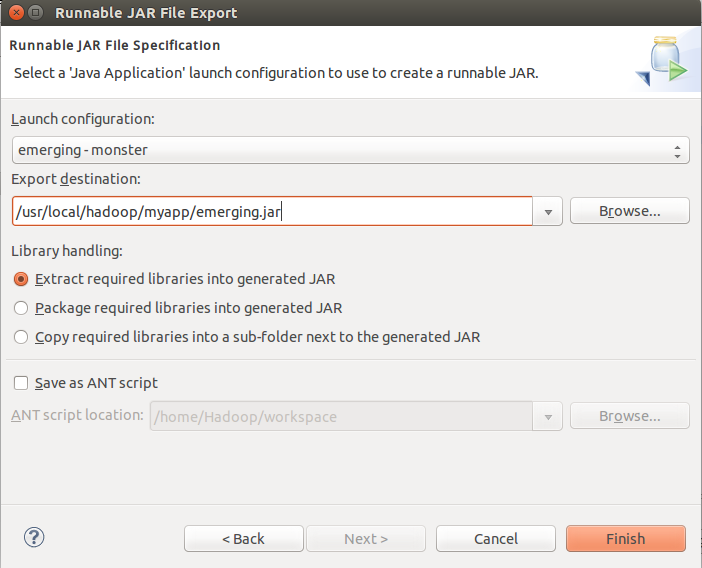
在终端执行命令:./bin/hadoop jar ./myapp/emerging.jar 运行刚才导出的 Jar 包:
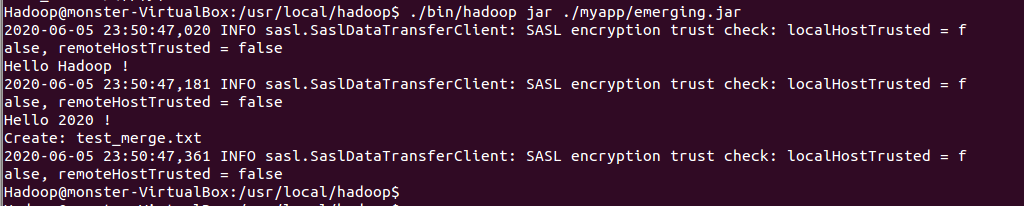
最后:查看刚才合成的新文件的内容,执行命令:./bin/hdfs/ dfs -cat test-merge.txt,如下图:

END...
二、总结致谢
此博客为博主学习总结,学习内容:
- 在分布式文件系统中创建文件并用 shell 指令查看;
- 利用 Java API 编程实现判断文件是否存在以及合并两个文件的内容成一个文件。
本次博客记录自己操作的详细步骤。
最后,感谢厦门大学数据库实验室的实验教程,对博主的学习帮助很大。

