用DOM实现对XML文件的解析
DOM 解析器介绍
DOM的 xml.dom.minidom 子模块、xml.dom.pulldom 子模块分别提供两种形式的解析器。
- xml.dom.minidom 子模块
主要提供对 XML 文档的读、修改操作,解析器的使用格式如下:
xml.dom.minidom.parse(filename_or_file,parse=None,bufsize=None)
该解析器解析成功,返回指定 XML 文件的一个文档对象。
本文用到的 DOM 对象的相关函数介绍
1.1 Node 接口对象相关函数
Node.childNodes,返回当前节点中包含的节点列表,这是一个只读属性。
1.2 Document 接口对象相关函数
Document.documentElement,返回文档的所有元素。
Document.getElementsByTagName(tagName),搜索所有具有特定元素类型名称下的子元素,返回元素集合。
1.3 Element 接口对象相关函数
Element.hasAttribute(name),如果元素具有按指定 name 命名的属性,返回True。
Element.getAttribute(name),以字符串形式返回指定 name 命名的属性的值,如果不存在这样的标签,则返回空字符串。
Element.setAttribute(name,value),设置 name 标签指定的值。
Element.removeAttribute(name),删除 name 标签指定的元素。
文件解析示例
1、 XML文件(movies.xml)
<collection shelf="New Arrivals">
<movies title="Enemy Behind">
<type>War, Thriller</type>
<format>DVD</format>
<year>2003</year>
<rating>PG</rating>
<stars>10</stars>
<description>Talk about a US-Japan war</description>
</movies>
</collection>
2、 DOM解析XML文件(sax_movie.py)
from xml.dom.minidom import parse
import xml.dom.minidom
# 使用minidom解析器打开 XML 文档
DOMTree = xml.dom.minidom.parse('D:\\My-python\\XML\\movies.xml')
# 该解析器解析成功,返回一个文档对象DOMTree接收
collection = DOMTree.documentElement # 把所有的元素存入集合中
print(collection.toxml())
if collection.hasAttribute("shelf"):
print ("Root element : %s" % collection.getAttribute("shelf"))
# 获取movie元素下的子元素集合
movies = collection.getElementsByTagName("movies")
movies_record = []
# 打印每部电影的详细信息
for movie in movies:
if movie.hasAttribute("title"): # 判断是否存在title属性
movies_record.append(movie.getAttribute("title")) # 获取属性对应的值
type = movie.getElementsByTagName('type')[0] # 获取 type 标签对应的元素
movies_record.append(type.childNodes[0].data) # 获取 type 元素对应的值
format = movie.getElementsByTagName('format')[0]
movies_record.append(format.childNodes[0].data)
rating = movie.getElementsByTagName('rating')[0]
movies_record.append(rating.childNodes[0].data)
stars = movie.getElementsByTagName('stars')[0]
movies_record.append(stars.childNodes[0].data)
description = movie.getElementsByTagName('description')[0]
movies_record.append(description.childNodes[0].data)
print(movies_record)
3、 运行结果
<collection shelf="New Arrivals">
<movies title="Enemy Behind">
<type>War, Thriller</type>
<format>DVD</format>
<year>2003</year>
<rating>PG</rating>
<stars>10</stars>
<description>Talk about a US-Japan war</description>
</movies>
</collection>
Root element : New Arrivals
['Enemy Behind', 'War, Thriller', 'DVD', 'PG', '10', 'Talk about a US-Japan war']
DOM实现对XML文件内容的修改
1、 代码(DOM_edit_XML.py)
from xml.dom.minidom import parse
import xml.dom.minidom
# 使用minidom解析器打开 XML 文档
DOMTree = xml.dom.minidom.parse('D:\\My-python\\XML\\movies.xml')
# 该解析器解析成功,返回一个文档对象DOMTree接收
# 把所有的元素存入集合中
collection = DOMTree.documentElement
# 获取 stars 的 NodeList 对象集合
stars = collection.getElementsByTagName("stars")
stars_object = stars[0] # 获取列表第一个price节点(元素)
stars_object.firstChild.data = 12 # 修改第一个节点的值
print('修改数量成功!')
# 获取 movies 的 NodeList 对象集合
movies = collection.getElementsByTagName("movies")
collection.removeChild(movies[1])
print('删除节点成功')
f = open('D:\\My-python\\XML\\movies.xml','w',encoding='utf-8')
f.write(DOMTree.toxml())
f.close()
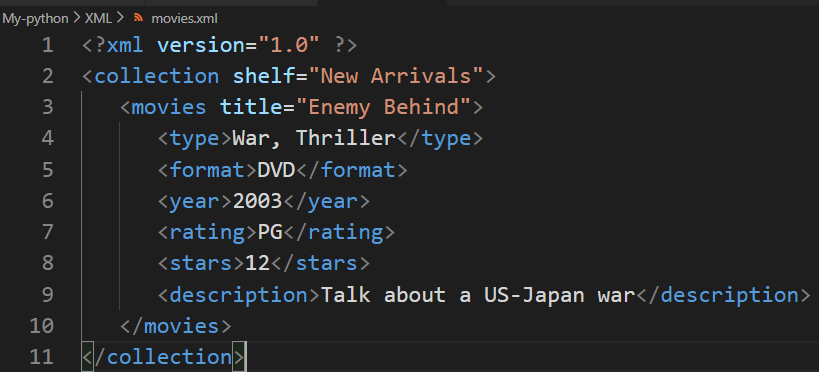
2、 修改结果
<?xml version="1.0" ?>
<collection shelf="New Arrivals">
<movies title="Enemy Behind">
<type>War, Thriller</type>
<format>DVD</format>
<year>2003</year>
<rating>PG</rating>
<stars>12</stars>
<description>Talk about a US-Japan war</description>
</movies>
</collection>
正是江南好风景

