
网络爬虫作业
第一部分:
请分析作业页面,爬取已提交作业信息,并生成已提交作业名单,保存为英文逗号分隔的csv文件。文件名为:hwlist.csv 。
文件内容范例如下形式:
学号,姓名,作业标题,作业提交时间,作业URL
20194010101,张三,羊车门作业,2018-11-13 23:47:36.8,http://www.cnblogs.com/sninius/p/12345678.html
20194010102,李四,羊车门,2018-11-14 9:38:27.03,http://www.cnblogs.com/sninius/p/87654321.html
*注1:如制作定期爬去作业爬虫,请注意爬取频次不易太过密集;
*注2:本部分作业用到部分库如下所示:
(1)requests —— 第3方库
(2)json —— 内置库
代码如下
import requests import json import os from threading import Timer url='https://edu.cnblogs.com/Homework/GetAnswers?homeworkId=2420&_=1542959851766' try: r=requests.get(url,timeout=30) r.raise_for_status() r.encoding=r.apparent_encoding datas=json.loads(r.text)['data'] except: print("获取数据错误") else: table=list() for data in datas: table.append(str(data['StudentNo'])+','+data['RealName']+','+data['Title']+','+data['DateAdded'].replace('T',' ')+','+data['Url']) #print(table) filename='hwlist.csv' with open (filename,'w') as f: for table1 in table: f.write(table1+'\n')
爬取结果如下图所示:

第二部分:
在生成的 hwlist.csv 文件的同文件夹下,创建一个名为 hwFolder 文件夹,为每一个已提交作业的同学,新建一个以该生学号命名的文件夹,将其作业网页爬去下来,并将该网页文件存以学生学号为名,“.html”为扩展名放在该生学号文件夹中。
#创建名称为“hwFolder”的文件夹,用于存储爬取下来的作业页面 os.mkdir("hwFolder") os.chdir("hwFolder") for data in datas: os.mkdir(str(data['StudentNo'])) os.chdir(str(data['StudentNo'])) try: name=requests.get(data["Url"],timeout=30) name.raise_for_status name.encoding=name.apparent_encoding except Exception as e: print(e) else: with open(str(data["StudentNo"])+"html","wb") as f1: f1.write(name.content) os.chdir(os.path.pardir)
生成的文件夹如下图所示:
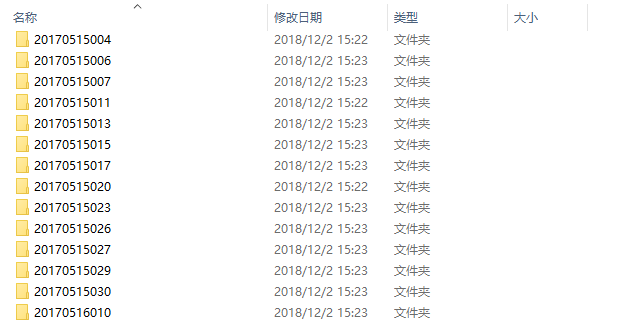
在这部分代码中由于python的os库我之前没有学过,所以只能在网上找了相关资料,然后参观了大佬们的博文才写出来
os库的DSCN网址如下:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号