

本章问题
1.根据下面给出的声明和数据,对每个表达式进行求值并写出它的值。在对每个表达式进行求值时使用原先给出的值(也就是说,某个表达式的结果不影响后面的表达式)。假定ints数组在内存中的起始位置是100,整型值和指针的长度都是四个字节。
int ints[20] = {10, 20, 30, 40, 50, 60, 70, 80, 90, 100, 110,120,130,140,150, 160,170,180,190,200}; (other declarations) int *ip = ints + 3;
| 表达式 | 值 | 表达式 | 值 |
| ints | ip | ||
| ints[4] | ip[4] | ||
| ints + 4 | ip+4 | ||
| *ints + 4 | *ip+4 | ||
| *(ints + 4) | *(ip+4) | ||
| ints[-2] | ip[-2] | ||
| &ints | &ip | ||
| &ints[4] | &ip[4] | ||
| &ints + 4 | &ip+4 | ||
| &ints[-2] | &ip[-2] |
answer:
表达式 值 表达式 值 ints 100 ip 112 ints[4] 50 ip[4] 80 ints + 4 116 ip+4 128 *ints + 4 14 *ip+4 44 *(ints + 4) 50 *(ip+4) 80 ints[-2] illegal ip[-2] 20 &ints 100 &ip illegal &ints[4] 116 &ip[4] 128 &ints + 4 116 &ip+4 illegal &ints[-2] illegal &ip[-2] 104
2.表达式array[i+j]和i+j[array]是不是相等?
answer: No,the second one is the same as array[j] + i,jue to the precedence of the operators.
(不相等,因为第二个相当于array[j]+i,由于操作符的优先性)
3.下面的声明试图按照从1开始的下标访问数组data,它能行吗?
int actual_data[20]; int *data = actual_data - 1;
answer: The assignment is illegal,as the pointer it attempts to compute is off the left end of the array;the technique should be avoided for this reason,Nevertheless,it will work on most machines.
(这个赋值语句是非法的,这个指针尝试访问数组第一位的前一位,应该避免这个原因使用这个技巧,然而,在大多数机器上它是可以运行的)
4.下面的循环用于测试某个字符串是否回文,请对它进行重写,用指针变量代替下标。
char buffer[SIZE]; int front,rear; ... front = 0; rear = strlen(buffer) - 1; while(front < rear){ if(buffer[front] != buffer[rear]) break; front += 1; rear -= 1; } if(front >= rear){ printf("It is a palindrome\n"); }
answer:
char buffer[SIZE]; char *front,*rear; front = buffer; rear = buffer; while(*rear != '\0') rear++; rear--; while(front < rear){ if(*front != *rear) break; front++; rear--; } if(front >= rear){ printf("It is a palindrome\n"); }
5.指针在效率上可能强于下标,这是使用它们的动机之一,那么什么时候使用下标是合理的,尽管它可能在效率上有所损失?
answer:It is often true that 80% of a program's run time is spent executing 20% of its code,The efficiency of statements in the other 80% of the code is not significant,so the use of pointers is not justified by the gain in efficiency.
(程序的80%的运行时间是花费在20%的代码上,其他80%的语句的效率不是很重要,所以合理的使用指针来增加它的有效性,但使用指针带来的效益抵不上其他方面的损失)
6.在你的机器上编译函数try1到try5,并分析结果的汇编代码,你的结论是什么?
answer:
/*根据自己的操作系统和机器得到汇编源码 linux上可用*/ gcc -S main.c -o main.s
#define SIZE 50 int x[SIZE]; int y[SIZE]; int i; void try1() { for(i = 0; i < SIZE; i++){ x[i] = y[i]; } } /*try1的汇编代码*/ .file "main.c" .comm x,200,32 //分配空间 .comm y,200,32 .comm i,4,4 .text .globl try1 .type try1, @function //声明函数try1 try1: .LFB0: //对i进行初始化 .cfi_startproc pushq %rbp .cfi_def_cfa_offset 16 .cfi_offset 6, -16 movq %rsp, %rbp .cfi_def_cfa_register 6 movl $0, i(%rip) jmp .L2 .L3: //将x数组的值赋给y数组并且i加1 movl i(%rip), %ecx movl i(%rip), %eax cltq movl y(,%rax,4), %edx movslq %ecx, %rax movl %edx, x(,%rax,4) movl i(%rip), %eax addl $1, %eax movl %eax, i(%rip) .L2: //把i与49做比较 movl i(%rip), %eax cmpl $49, %eax jle .L3 nop popq %rbp .cfi_def_cfa 7, 8 ret .cfi_endproc .LFE0: .size try1, .-try1 .ident "GCC: (Ubuntu 5.4.0-6ubuntu1~16.04.4) 5.4.0 20160609" .section .note.GNU-stack,"",@progbits
#define SIZE 50 int x[SIZE]; int y[SIZE]; int i; int *p1,*p2; void try2() { for(p1 = x,p2 = y;p1 - x < SIZE;) *p1++ = *p2++; }
/*try2的汇编源码*/
.file "main.c" .comm x,200,32 //分配空间 .comm y,200,32 .comm i,4,4 .comm p1,8,8 .comm p2,8,8 .text .globl try2 .type try2, @function try2: .LFB0: .cfi_startproc pushq %rbp .cfi_def_cfa_offset 16 .cfi_offset 6, -16 movq %rsp, %rbp .cfi_def_cfa_register 6 movq $x, p1(%rip) //初始化p1 p2 movq $y, p2(%rip) jmp .L2 .L3: //*p1++ = *p2++ movq p1(%rip), %rax leaq 4(%rax), %rdx movq %rdx, p1(%rip) movq p2(%rip), %rdx leaq 4(%rdx), %rcx movq %rcx, p2(%rip) movl (%rdx), %edx movl %edx, (%rax) .L2: //比较p1-x和199的值 movq p1(%rip), %rax movq %rax, %rdx movl $x, %eax subq %rax, %rdx movq %rdx, %rax cmpq $199, %rax jle .L3 nop popq %rbp .cfi_def_cfa 7, 8 ret .cfi_endproc .LFE0: .size try2, .-try2 .ident "GCC: (Ubuntu 5.4.0-6ubuntu1~16.04.4) 5.4.0 20160609" .section .note.GNU-stack,"",@progbits
#define SIZE 50 int x[SIZE]; int y[SIZE]; int i; int *p1,*p2; void try3() { for(i = 0,p1 = x,p2 = y; i < SIZE;i++){ *p1++ = *p2++; } }
/*try3的汇编源码*/
.file "main.c" .comm x,200,32 .comm y,200,32 .comm i,4,4 .comm p1,8,8 .comm p2,8,8 .text .globl try3 .type try3, @function try3: .LFB0: .cfi_startproc pushq %rbp .cfi_def_cfa_offset 16 .cfi_offset 6, -16 movq %rsp, %rbp .cfi_def_cfa_register 6 movl $0, i(%rip) //初始化i p1 p2 movq $x, p1(%rip) movq $y, p2(%rip) jmp .L2 .L3: //*p1++ = *p2++ movq p1(%rip), %rax leaq 4(%rax), %rdx movq %rdx, p1(%rip) movq p2(%rip), %rdx leaq 4(%rdx), %rcx movq %rcx, p2(%rip) movl (%rdx), %edx movl %edx, (%rax) movl i(%rip), %eax //i++ addl $1, %eax movl %eax, i(%rip) .L2: //把i与49做比较 movl i(%rip), %eax cmpl $49, %eax jle .L3 nop popq %rbp .cfi_def_cfa 7, 8 ret .cfi_endproc .LFE0: .size try3, .-try3 .ident "GCC: (Ubuntu 5.4.0-6ubuntu1~16.04.4) 5.4.0 20160609" .section .note.GNU-stack,"",@progbits
#define SIZE 50 int x[SIZE]; int y[SIZE]; int i; int *p1,*p2; void try4() { register int *p1,*p2; register int i; for(i = 0,p1 = x,p2 = y;i < SIZE;i++) *p1++ = *p2++; } /*try4的汇编源码*/ .file "main.c" .comm x,200,32 .comm y,200,32 .comm i,4,4 .comm p1,8,8 .comm p2,8,8 .text .globl try4 .type try4, @function try4: .LFB0: .cfi_startproc pushq %rbp .cfi_def_cfa_offset 16 .cfi_offset 6, -16 movq %rsp, %rbp .cfi_def_cfa_register 6 pushq %r13 //寄存器变量p1 p2 i分配寄存器,并将寄存器中原来的值保存到栈中 pushq %r12 pushq %rbx .cfi_offset 13, -24 .cfi_offset 12, -32 .cfi_offset 3, -40 movl $0, %ebx movl $x, %r12d movl $y, %r13d jmp .L2 .L3: //*p1++ = *p2++ movq %r12, %rax leaq 4(%rax), %r12 movq %r13, %rdx leaq 4(%rdx), %r13 movl (%rdx), %edx movl %edx, (%rax) addl $1, %ebx //i++ .L2: //比较i与49的大小 cmpl $49, %ebx jle .L3 nop popq %rbx //恢复原寄存器变量 popq %r12 popq %r13 popq %rbp .cfi_def_cfa 7, 8 ret .cfi_endproc .LFE0: .size try4, .-try4 .ident "GCC: (Ubuntu 5.4.0-6ubuntu1~16.04.4) 5.4.0 20160609" .section .note.GNU-stack,"",@progbits
首先要注意windows和linux中的汇编语言的差异,绝大多数 Linux 程序员以前只接触过DOS/Windows 下的汇编语言,这些汇编代码都是 Intel 风格的。但在 Unix 和 Linux 系统中,更多采用的还是 AT&T 格式,具体差异参考:http://www.ibm.com/developerworks/cn/linux/l-assembly/index.html
其次从这四个程序的汇编代码上的差异可以看出,最特别的当然是try4的寄存器变量,如果不用寄存器变量,在计算的时候要先把值移到特定的寄存器中再计算,用寄存器变量就少了这一步,然后有计数器i变量可以减少不少的工作,然后就是指针的计算和数组的计算中的乘法问题,指针直接加4,而数组每次需要获取i的值后再乘以整型长度
7.测试你对前一个问题的结论,方法是运行每一个函数并对它们的执行时间进行计时,把数组元素增加到几千个,增加试验的准确性,因为此时复制所占用的时间远远超过程序不相关部分所占用的时间。同样,在一个循环内部调用函数,让它重复执行足够多的次数,这样你可以精确的为执行时间计时。为这个试验两次编译程序,一次不使用任何优化措施,另一次使用优化措施,如果你的编译器可以选择,请选择优化措施以获得最佳速度。
answer:
我的系统是ubuntu,所以ubuntu下计算时间的方法参考于:http://blog.csdn.net/swqqcs/article/details/7997660
另外使用的编译器是gcc,gcc的优化选项参考于:http://blog.csdn.net/misiter/article/details/7514428
把SIZE的值定为10000,然后分别看看使用优化和不使用优化的时间:
注意:系统运行的时间是不能确定的,由于众多因素,每次运行的结果都将不同,所以我是运行十次取平均值,也有很大的误差,
具体请参考:http://blog.csdn.net/yuyin86/article/details/6616566
| 单位:s | 优化-O2 | 不优化-O0 |
| try1 | 0.000056 | 0.000149 |
| try2 | 0.000042 | 0.000125 |
| try3 | 0.000043 | 0.000139 |
| try4 | 0.000023 | 0.000066 |
8.下面的声明取自某个源文件:
int a[10]; int *b = a;
但在另一个源文件中,却发现了这样的代码:
extern int *a; extern int b[]; int x,y; ... x = a[3]; y = b[3];
请解释一下,当两条赋值语句执行时会发生什么?(假定整型和指针的长度都是4个字节)
answer:在第一个赋值语句中,编译器认为a是一个指针变量,所以它提取存储在那里的指针值,并加上12(3个整型长度),然后对这个结果执行间接访问操作。但a实际上是整型数组的起始位置,所以作为“指针”获得的这个值实际上是数组的第一个整型元素,它与12相加,其结果解释为一个地址,然后对它执行间接访问,作为结果,它将提取一些任意内存位置的内容,或者由于某种地址错误而导致程序失败。
第二个赋值中,编译器认为b是个数组名。所以它把12(3的调整结果)加到b的存储地址,然后间接访问操作从那里获得值,事实上b是一个指针变量,所以从内存中提取的后面三个字实际上是从另外的任意变量中取得的,这个问题说明了指针和数组虽然存在关联,但绝不会是相同的。
9.编写一个声明,初始化一个名叫coin_values的整型数组,各个元素的值分别表示当前各种美元硬币的币值。
answer:
int coin_values[] = {1, 5, 10, 25, 50, 100};
10.给定下列声明
int array[4][2];
请写出下面每个表达式的值,假定数组的起始位置为1000,整型值在内存中占据了2个字节的空间。
表达式 值
array
array+2
array[3]
array[2]-1
&array[1][2]
&array[2][0]
answer:
表达式 值
array 1000
array+2 1008
array[3] 1012
array[2]-1 1006
&array[1][2] 1008
&array[2][0] 1008
11.给定下列声明:
int array[4][2][3][6];
表达式 值 X的类型
array
array+2
array[3]
array[2]-1
array[2][1]
array[1][0]+1
array[1][0][2]
array[0][1][0]+2
array[3][1][2][5]
&array[3][1][2][5]
计算上表中各个表达式的值。同时,写出变量X所需的声明,这样表达式不用进行强制类型转换就可以赋值给x,假定数组的起始位置为1000,整型值在内存中占4个字节。
answer:
表达式 值 X的类型
array 1000 int (*x)[2][3][6]
array+2 1288 int (*x)[2][3][6]
array[3] 1432 int (*x)[3][6]
array[2]-1 1216 int (*x)[3][6]
array[2][1] 1360 int (*x)[6]
array[1][0]+1 1168 int (*x)[6]
array[1][0][2] 1192 int *x;
array[0][1][0]+2 1080 int *x;
array[3][1][2][5] can't tell int x;
&array[3][1][2][5] 1572 int *x;
12.C的数组按照行主序存储,什么时候需要使用这个信息?
answer:When performing any operation that accesses the elements in the order in which they appear in memory.For example, initializing an array,reading or writing more than one element of an array,and flattening an array by incrementing a pointer to access its underlying memory all qualify.
(当执行任何“按照元素在内存中出现的顺序对元素进行访问”的操作时。例如,初始化一个数组,读取或写入超过一个的数组元素,通过移动指针访问数组的底层内存“圧扁”数组等都属于这类操作)
13.给定下列声明
int array[4][5][3];
把下列各个指针表达式转化为下标表达式。
表达式 下标表达式
*array
*(array+2)
*(array+1)+4
*(*(array+1)+4)
*(*(*(array+3)+1)+3)
*(*(*array+1)+2)
*(**array+2)
**(*array+1)
***array
answer:
表达式 下标表达式
*array array[0]
*(array+2) array[2]
*(array+1)+4 array[1]+4
*(*(array+1)+4) array[1][4]
*(*(*(array+3)+1)+3) array[3][1][3]
*(*(*array+1)+2) array[0][1][2]
*(**array+2) array[0][0][2]
**(*array+1) array[0][1][0]
***array array[0][0][0]
14.多维数组的各个下标必须单独出现在一对方括号内,在什么条件下,下列这些代码段可以通过编译而不会产生任何警告信息。
int array[10][20]; ... i = array[3,4];
answer:If i were declared a s apointer to an integer,there is no error.
(如果i是一个指向整型的指针,这里就没有错)
15.给定下列声明
unsigned int which; int array[SIZE];
下面两条语句哪条更合理?为什么?
if(array[whilch] == 5 && which < SIZE)... if(which < SIZE && array[which] == 5)...
answer:The second makes more sense,if which is out of range,using it as a subscript could crash the program.
(第二条语句更有意义,如果which已经超出数组范围了,它作为下标将会使程序崩溃)
16.在下面的代码中,变量array1和array2有什么区别(如果有的话)?
void function(int array1[10]){ int array2[10]; ... }
answer:There are several differences.Being an argument,array1 is actually a pointer variable;it points to the array passed as the actual argument,and its value can be chaned by the function.No space for this array is allocated in this function,and there is no guarantee that the argument actually passed has ten elements.On the other hand,array2 is apointer constant,so its value annot be changed,it points to the space allocated in this function for ten integers.
(有许多的不同,array1是实参作为参数传递给函数的指针,它指向实际的数组参数,并且它的值可以改变,在这个函数里不会为array1分配空间,它不能保证函数实际只有十个元素,另一方面,array2是一个指针常量,所以它不能被改变,它在这个函数中指向一个有十个整型元素的数组)
17.解释下面两种const关键字用法的显著区别所在。
void function(int const a,int const b[]);
answer:The first parameter is a scalar(标量).so the function gets a copy of the value,Changes made to the copy do not affect the original argument,so the const keyword is not what prevents the original argument from being modified.The second parameter is actually a pointer to an integer,the pointer is a copy and can be modified without affecting the original argument,but the function could conceivably use indirection on the pointer to modify one of the caller's values,the const keyword prevents this modification.
(第一个参数是一个标量,所以函数获得的是原值的拷贝,这个拷贝的值的改变不会影响原值,所以这个const关键字的作用不是保护原值被修改,第二个参数实际上是一个整型指针,这个指针是一个拷贝并且可以改变而与原值无关,不过这个函数可以间接访问调用的值并且可以改变该值,所以const关键字用于防止这种修改)
18.下面的函数原型可以改为什么形式?但保持结果不变。
void function(int array[3][2][5]);
answer:
void function(a[][2][5]);
or
void function(int (*array)[2][5]);
19.在程序8.2的关键字查找例子中,字符指针数组的末尾增加了一个NULL指针,这样我们就不需要知道表的长度,那么矩阵方案应该如何修改,使其达到同样的效果呢?写出用于访问修改后的矩阵的for语句。
程序8.2 关键字查找 #include <stdio.h> int lookup_keyword(char const * const desired_word, char const *keyword_table[],int const size) { char const **kwp; for(kwp = keyword_table; kwp < keyword_table + size; kwp++) if(strcmp(desired_word,*kwp) == 0) return kwp - keyword_table; return -1; }
char const *keyword[] = { "do" "for" "if" "register" "return" "switch" "while" NULL };
answer:
for(kwp = keyword_table; **kwp != '\0';kwp++)
编程练习
1.编写一个数组的声明,把数组的某些特定位置初始化为特定的值。这个数组的名字应该叫char_value,它包含3×6×4×5个无符号字符。下面的表中列出的这些位置应该用相应的值进行静态初始化。
| 位置 | 值 | 位置 | 值 | 位置 | 值 |
| 1,2,2,3 | ‘A' | 1,1,1,1 | ' ' | 1,3,2,2 | 0xf3 |
| 2,4,3,2 | '3' | 1,4,2,3 | '\n' | 2,2,3,1 | '\121' |
| 2,4,3,3 | 3 | 2,5,3,4 | 125 | 1,2,3,4 | 'x' |
| 2,1,1,2 | 0320 | 2,2,2,2 | '\'' | 2,2,1,1 | '0' |
那些在上表未提到的位置应该被初始化为二进制值0而不是字符’\0',注意:应该使用静态初始化,在你的解决方案中不应该存在任何可执行代码!尽管并非解决方案的一部分,你可能很想编写一个程序,通过打印数组的值来验证它的初始化,由于某些值并不是可打印的字符,所以请把这些字符用整型的形式打印出来(用八进制或十六进制输出会更方便一些)。注意,用两种方法解决这个问题,一次在初始化列表中使用嵌套的花括号,另一次则不使用,这样你就能深刻理解嵌套花括号的作用。
answer:
#include <stdio.h> unsigned char char_value[3][6][4][5] ={ { 0 }, { { 0 }, { {0}, {0,' '}, }, { {0}, {0}, {0,0,0,'A'}, {0,0,0,0,'x'} }, { {0}, {0}, {0,0,0xf3}, }, { {0}, {0}, {0,0,0,'\n'} }, { 0 } }, { {0}, { {0}, {0,0,0320}, }, { {0}, {0,'0'}, {0,0,'\''}, {0,'\121'} }, { 0 }, { {0}, {0}, {0}, {0,0,'3',3} }, { {0}, {0}, {0}, {0,0,0,0,125} } } }; int main() { printf("%c ",char_value[1][2][2][3]); printf("%d ",char_value[1][1][1][1]); printf("%x\n",char_value[1][3][2][2]); printf("%c ",char_value[2][4][3][2]); printf("%d ",char_value[1][4][2][3]); printf("%x\n",char_value[2][2][3][1]); printf("%d ",char_value[2][4][3][3]); printf("%d ",char_value[2][5][3][4]); printf("%c\n",char_value[1][2][3][4]); printf("%o ",char_value[2][1][1][2]); printf("%c ",char_value[2][2][2][2]); printf("%c\n",char_value[2][2][1][1]); }
没有括号的就不写了,不想那么深刻的理解嵌套花括号的作用:)
2.美国联邦政府使用下面这些规则计算1995年每个公民的个人收入所得税:
|
If Your Taxable income is over |
But not Over | Your Tax is |
of the Amout Over |
| $0 | $23350 | 15% | $0 |
| 23350 | 56550 | 3502.50+28% | 23350 |
| 56550 | 117950 | 12798.50+31% | 56550 |
| 117950 | 256500 | 31832.50+36% | 117950 |
| 256500 | - | 81710.50+39.6% | 256500 |
为下面的函数原型编写函数定义:
float single_tax(float income);
参数income表示应征税的个人收入,函数的返回值就是income应该征收的税额。
answer:
/*普通的方法*/ float single_tax(float income){ if(income > 256500) return 81710.5 + 0.396 * (income - 256500); else if(income > 117950) return 31832.5 + 0.36 * (income - 117950); else if(income > 56550) return 12798.5 + 0.31 * (income - 56550); else if(income > 23350) return 3502.5 + 0.28 * (income - 23350); else if(income > 0) return 0.15 * income; else return 0; }
/*查表法*/
#include <float.h> static double income_limits[] = { 0, 23350, 56550, 117950, 256500, DBL_MAX }; static float base_tax[] = { 0, 3502.5, 12798.5, 31832.5, 81710.5 }; static float percentage[] = { 0.15, 0.28, 0.31, 0.36, 0.396 } double single_tax(double income) { int category; for(category = 1; income >= income_limits[category]; category++) ; category--; return base_tax[category] + percentage[category] * (income - income_limits[category]); } /*DBL_MAX定义在float.h中, Maximum finite representable floating-point number. 意思是浮点数中的最大值*/
3.单位矩阵就是一个正方形矩阵,它除了主对角线元素值为1以外,其余元素的值均为0,例如:
1 0 0 0 1 0 0 0 1
就是一个3×3单位矩阵,编写一个名叫identity_matrix的函数,它接受一个10×10整型矩阵为参数,并返回一个布尔值,提示该矩阵是否为单位矩阵。
answer:
int identity_matrix(int matrix[][10]){ int i,j; for(i = 0; i < 10; i++) for(j = 0; j < 10; j++){ if(i == j){ if(matrix[i][j] != 1) return FALSE; }else{ if(matrix[i][j] != 0) return FALSE; } } return TRUE; }
4.修改前一个问题中的identity_matrix函数,它可以对数组进行扩展,从而能够接受任意大小的矩阵参数。函数的第一个参数应该是一个整型指针,你需要第二个参数,用于指定矩阵的大小。
answer:
#define TRUE 1 #define FALSE 0 int identity_matrix(int *matrix,int n){ int row; int column; for(row = 0; row < n; row++){ for(column = 0; column < n; column++){ if(*matrix++ != (row == column)) return FALSE; } } return TRUE; }
5.如果A是个x行y列的矩阵,B是个y行z列的矩阵,把A和B相乘,其结果将是另一个x行z列的矩阵C。这个矩阵的每个元素是由下面的公式决定的:
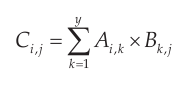
例如:

结果矩阵中14这个值是通过2×-2加上-6×-3得到的。
编写一个函数,用于执行两个矩阵的乘法。函数的原型如下:
void matrix_multiply(int *m1, int *m2, int *r, int x, int y, int z);
m1是一个x行y列的矩阵,m2是一个y行z列的矩阵,这两个矩阵应该相乘,结果存储于r中,它是一个x行z列的矩阵。记住,你应该对公式做些修改,以适应C语言下标从0而不是从1开始这个事实!
answer:
#include <stdio.h> void matrix_multiply(int *m1, int *m2, int *r, int x, int y, int z); void main(){ int m1[3][2] = {{2, -6}, {3, 5}, {1, -1}}; int m2[2][4] = {{4, -2, -4, -5}, {-7, -3, 6, 7}}; int r[3][4] = {0}; matrix_multiply(m1,m2,r,3,2,4); for(int i = 0; i < 3; i++){ for(int j = 0; j < 4; j++) printf("%d ",r[i][j]); printf("\n"); } } void matrix_multiply(int *m1, int *m2, int *r, int x, int y, int z) { int i,j; for(i = 0; i < x; i++){ for(j = 0; j < z; j++){ int k; int *p1 = m1 + i * y; int *p2 = m2 + j; for(k = 0; k < y; k++){ *r += *p1 * *p2; p1++; p2 += z; } r++; } } }
注意到m1m2是个二维数组,而函数中只使用了一个整型指针(差点以为题目出错了),标准答案中解释是用圧扁数组的方法,建议不使用这种方法,原因是请看警告:
expected ‘int *’ but argument is of type ‘int (*)[4]’
void matrix_multiply(int *m1, int *m2, int *r,...
还是好好的使用int (*)[4] 或者int m1[][4]吧
6.如你所知,C编译器为数组分配下标时总是从0开始,而且当程序使用下标访问数组元素时,它并不检查下标的有效性,在这个项目中,你将要编写一个函数,允许用户访问“伪数组”,它的下标范围可以任意指定,并伴以完整的错误检查。下面是你将要编写的这个函数的原型:
int array_offset(int arrayinfo[],...);
这个函数接受一些用于描述伪数组的维数信息以及一组下标值,使用这个函数,用户既可以以向量的形式分配内存空间,也可以使用mallco分配空间,但按照多维数组的形式访问这些空间,这个数组之所以被称为“伪数组”是因为编译器以为它是个向量,尽管这个函数允许它按照多维数组的形式进行访问。
这个函数的参数如下:
参数 含义
arrayinfo 一个可变长度的整型数组,包含一些关于伪数组的信息。arrayinfo[0]指定伪数组具有的
维数,它的值必须在1和10之间。arrayinfo[1]和arrayinfo[2]给出第一维的下限和上限。
arrayinfo[3]和arrayinfo[4]给出第2维的下限和上限,依次类推。
... 参数列表的可变部分可能包含多达10个的整数,用于标识伪数组中某个特定位置的下标
值。你必须使用va_参数访问它们,当函数被调用时,arrayinfo[0]参数将会被传递。
公式根据下面给出的下标值计算一个数组的位置。变量s1,s2等代表下标参数s1,s2等。变量lo1和hi1代表下标s1的下限和上限,它们来源于arrayinfo参数,其余各维以此类推。变量loc表示伪数组的目标位置,它用一个距离伪数组起始位置的整型偏移量表示。
对于一维数组:
loc = s1 - lo1
对于二维伪数组:
loc = (s1 - lo1) × (hi2 - lo2 + 1) + s2 - lo2
对于三维伪数组:
loc = [(s1 - lo1) × (hi2 - lo2 + 1) + s2 - lo2] × (hi3 - lo3 + 1) + s3 - lo3
对于四维伪数组:
loc = [[(s1 - lo1) × (hi2 - lo2 + 1) + s2 - lo2] × (hi3 - lo3 + 1) + s3 - lo3] × (hi4 - lo4 + 1) + s4 - lo4
一直到第十维为止,都可以类似的使用这种方法推导出loc的值。你可以假定arrayinfo是个有效的指针,传递给array_offset的下标参数也是正确的。对于其他情况你必须进行错误检查,可能出现的一些错误有:维的数目不处于1到10之间,下标小于low值,low值大于其对应的high值等,如果检测到这些或者其他错误,函数应该返回-1.
提示:把下标参数都复制到一个局部数组中,你接着便可以把计算过程以循环的形式编码,对每一维都使用一次循环。
举例:假定arrayinfo包含值2,4,6,1,5,-3,3.这些值提示我们所处理的是三维伪数组,第一个下标范围从4到6,第二个下标范围从1到5,第三个下标范围从-3到3,在这个例子中,array_offset被调用时将有三个下标参数传递给它,下面显示了几组下标值以及它们所代表的偏移量:

answer:
//使用下标
int array_offset(int arrayinfo[],...) { int temp[10]; int offset = 0; va_list var_list; int i; if(arrayinfo[0] <= 1 || arrayinfo[0] > 10) return -1; va_start(var_list,arrayinfo); for(i = 0; i < arrayinfo[0]; i++){ temp[i] = va_arg(var_list,int); } va_end(var_list); for(i = 0; i < arrayinfo[0]; i++){ if(i % 2 == 0 && arrayinfo[2 * i] >= temp[i] && arrayinfo[2 * i + 1] <= temp[i]) return -1; offset *= (arrayinfo[2 * i] - arrayinfo[2 * i - 1] + 1); offset += temp[i] - arrayinfo[2 * i - 1]; } return offset; }
//使用指针 int array_offset(int arrayinfo[],...) { int ndim; int offset; int hi,lo; int i; int s[10]; va_list subscripts; va_start(subscripts,arrayinfo); ndim = *arrayinfo++; if(ndim >= 1 && ndim <= 10){ for(i = 0; i < ndim; i += 1) s[i] = va_arg(subscripts,int); va_end(subscripts); offset = 0; for(i = 0; ndim;ndim--,i++){ lo = *arrayinfo++; hi = *arrayinfo++; if(s[i] < lo || s[i] > hi) return -1; offset *= hi - lo + 1; offset += s[i] - lo; } return offset; } return -1; }
7.修改问题6中的array_offset函数,使它访问以列主序存储的伪数组,也就是最左边的下标率先变化。这个新函数,array_offset2,在其它方面应该与原先那个函数一样,计算这些数组下标的公式如下所示。

举例:假定arrayinfo包含值2,4,6,1,5,-3,3.这些值提示我们所处理的是三维伪数组,第一个下标范围从4到6,第二个下标范围从1到5,第三个下标范围从-3到3,在这个例子中,array_offset被调用时将有三个下标参数传递给它,下面显示了几组下标值以及它们所代表的偏移量:

answer:
int array_offset(int arrayinfo[],...) { int ndim; int offset; int hi,lo; int i; int s[10]; int *sp; va_list subscripts; va_start(subscripts,arrayinfo); ndim = *arrayinfo++; arrayinfo += ndim * 2; sp = s + ndim; if(ndim >= 1 && ndim <= 10){ for(i = 0; i < ndim; i += 1) s[i] = va_arg(subscripts,int); va_end(subscripts); offset = 0; while(ndim >= 1){ hi = *--arrayinfo; lo = *--arrayinfo; if(*--sp > hi || *sp < lo) return -1; offset *= hi - lo + 1; offset += *sp - lo; } return offset; } return -1; }
8.皇后是国际象棋中威力最大的棋子,在下面所示的棋盘上,皇后可以攻击位于箭头所覆盖位置的所有棋子。

我们能不能把8个皇后放在棋盘上,它们中任何一个都无法攻击其余的皇后?这个问题被称为八皇后问题,你的任务是编写一个程序,找到八皇后问题的所有答案,看看一共有多少种答案。
提示:如果你采用一种叫做回溯法的技巧,就很容易编写出这个程序,编写一个函数,把皇后放在某行的第一列,然后检查它是否与棋盘上的其他皇后互相攻击,如果存在互相攻击,函数把皇后移到该行的第二列再进行检查,如果每列都存在互相攻击的情况,函数就应该返回,但是如果皇后可以放在这个位置,函数接着应该递归的调用自身,把一个皇后放在下一行,当递归调用返回时,函数再把原先那个皇后移到下一列。当一个皇后成功的放置于最后一行时,函数应该打印出棋盘,显示8个皇后的位置。
#include <stdio.h>
int board[8][8];
//打印解决方案
void print_board()
{
int row;
int column;
static int n_solutions;
n_solutions += 1;
printf("Solution #%d:\n",n_solutions);
for(row = 0; row < 8; row++){
for(column = 0; column < 8; column++){
if(board[row][column])
printf("Q");
else
printf("+");
}
putchar('\n');
}
putchar('\n');
}
//检测board[row][column]的上半部分的方向上是否有其他皇后
int conflicts(int row, int column)
{
int i;
for(i = 1; i < 8; i++){
if(row - i >= 0 && board[row - i][column])
return 1;
if(column - i >= 0 && board[row][column - i])
return 1;
if(column + i < 8 && board[row][column + i])
return 1;
if(row - i >= 0 && column - i >= 0 && board[row - i][column - i])
return 1;
if(row - i >= 0 && column + i < 8 && board[row - i][column + i])
return 1;
}
return 0;
}
//回溯法调用自身
void place_queen(int row)
{
int column;
for(column = 0; column < 8; column++){
board[row][column] = 1;
if(row == 0 || !conflicts(row,column))
if(row < 7)
place_queen(row + 1);
else
print_board();
board[row][column] = 0;
}
}
int main()
{
place_queen(0);
return 0;
}
关于回溯法和八皇后问题都相当的有趣并且很实用,在这里分享一个链接:
知乎-如何用 C++ 在 10 行内写出八皇后?https://www.zhihu.com/question/28543312
还可以去搜搜其他的思路,挺有意思的。

