AI健身计数
AI健身计数
一、jupyter notebook部分
(姿势估计 mediapipe)
1、环境的配置
下载mediapipe包
pip install mediapipe==0.8.9 -i https://mirrors.aliyun.com/pypi/simple/
下载open-cv包
pip install opencv-python -i https://mirrors.aliyun.com/pypi/simple/
2、单张图片的识别
# opencv-python
import cv2
# mediapipe人工智能工具包
import mediapipe as mp
# 进度条库
from tqdm import tqdm
# 时间库
import time
# 导入python绘图matplotlib
import matplotlib.pyplot as plt
# 使用ipython的魔法方法,将绘制出的图像直接嵌入在notebook单元格中
%matplotlib inline
# 定义可视化图像函数
def look_img(img):
'''opencv读入图像格式为BGR,matplotlib可视化格式为RGB,因此需将BGR转RGB'''
img_RGB = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
plt.imshow(img_RGB)
plt.show()
# 导入solution
mp_pose = mp.solutions.pose
# # 导入绘图函数
mp_drawing = mp.solutions.drawing_utils
# 导入模型
pose = mp_pose.Pose(static_image_mode=True, # 是静态图片还是连续视频帧
model_complexity=1, # 选择人体姿态关键点检测模型,0最快但性能差,2性能好但是慢
smooth_landmarks=True, # 是否平滑关键点
min_detection_confidence=0.5, # 置信度阈值
min_tracking_confidence=0.5) # 追踪阈值
# 从图片文件读入图像,opencv读入为BGR格式
img = cv2.imread('person1.jfif')
# BGR转RGB
img_RGB = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
# 将RGB图像输入模型,获取预测结果
results = pose.process(img_RGB)
# 可视化
mp_drawing.draw_landmarks(img, results.pose_landmarks, mp_pose.POSE_CONNECTIONS)
look_img(img)
# 在三维真实物理坐标系中可视化以米为单位的检测结果
mp_drawing.plot_landmarks(results.pose_world_landmarks, mp_pose.POSE_CONNECTIONS)
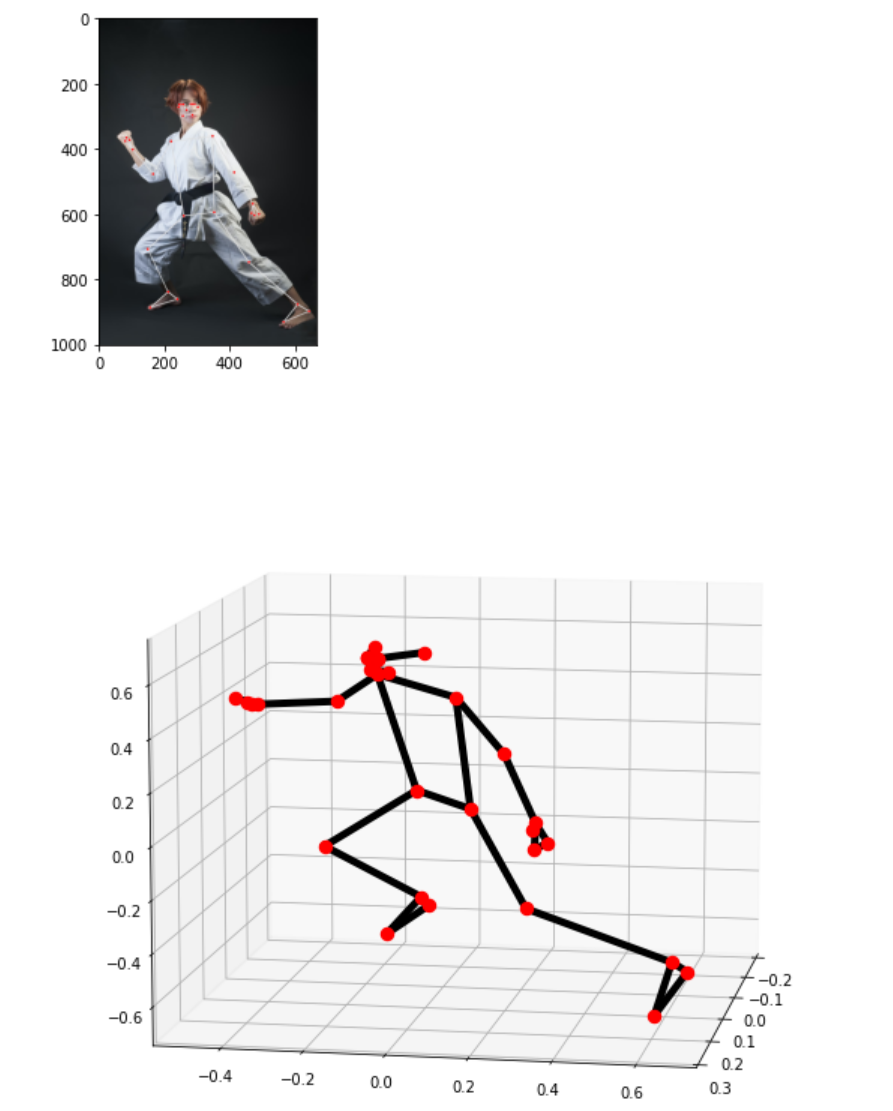
3、 摄像头实时检测
# opencv-python
import cv2
# mediapipe人工智能工具包
import mediapipe as mp
# 进度条库
from tqdm import tqdm
# 时间库
import time
# 导入solution
mp_pose = mp.solutions.pose
# # 导入绘图函数
mp_drawing = mp.solutions.drawing_utils
# 导入模型
pose = mp_pose.Pose(static_image_mode=False, # 是静态图片还是连续视频帧
model_complexity=2, # 选择人体姿态关键点检测模型,0性能差但快,2性能好但慢,1介于两者之间
smooth_landmarks=True, # 是否平滑关键点
enable_segmentation=True, # 是否人体抠图
min_detection_confidence=0.5, # 置信度阈值
min_tracking_confidence=0.5) # 追踪阈值
# 处理帧函数
def process_frame(img):
# BGR转RGB
img_RGB = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
# 将RGB图像输入模型,获取预测结果
results = pose.process(img_RGB)
# 可视化
mp_drawing.draw_landmarks(img, results.pose_landmarks, mp_pose.POSE_CONNECTIONS)
# look_img(img)
# 在三维真实物理坐标系中可视化以米为单位的检测结果
# mp_drawing.plot_landmarks(results.pose_world_landmarks, mp_pose.POSE_CONNECTIONS)
# # BGR转RGB
# img_RGB = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
# # 将RGB图像输入模型,获取预测结果
# results = hands.process(img_RGB)
# if results.multi_hand_landmarks: # 如果有检测到手
# # 遍历每一只检测出的手
# for hand_idx in range(len(results.multi_hand_landmarks)):
# hand_21 = results.multi_hand_landmarks[hand_idx] # 获取该手的所有关键点坐标
# mpDraw.draw_landmarks(img, hand_21, mp_hands.HAND_CONNECTIONS) # 可视化
return img
# 调用摄像头逐帧实时处理模板
# 不需修改任何代码,只需修改process_frame函数即可
# 同济子豪兄 2021-7-8
# 导入opencv-python
import cv2
import time
# 获取摄像头,传入0表示获取系统默认摄像头
cap = cv2.VideoCapture(1)
# 打开cap
cap.open(0)
# 无限循环,直到break被触发
while cap.isOpened():
# 获取画面
success, frame = cap.read()
if not success:
print('Error')
break
## !!!处理帧函数
frame = process_frame(frame)
# 展示处理后的三通道图像
cv2.imshow('my_window',frame)
if cv2.waitKey(1) in [ord('q'),27]: # 按键盘上的q或esc退出(在英文输入法下)
break
# 关闭摄像头
cap.release()
# 关闭图像窗口
cv2.destroyAllWindows()
英文状态下按q退出
可以运行 就不放丑照了
4、摄像头实时检测的提升
(不同身体部位加入了不同颜色的结点)
# opencv-python
import cv2
# mediapipe人工智能工具包
import mediapipe as mp
# 进度条库
from tqdm import tqdm
# 时间库
import time
# 导入solution
mp_pose = mp.solutions.pose
# # 导入绘图函数
mp_drawing = mp.solutions.drawing_utils
# 导入模型
pose = mp_pose.Pose(static_image_mode=False, # 是静态图片还是连续视频帧
model_complexity=2, # 选择人体姿态关键点检测模型,0性能差但快,2性能好但慢,1介于两者之间
smooth_landmarks=True, # 是否平滑关键点
min_detection_confidence=0.5, # 置信度阈值
min_tracking_confidence=0.5) # 追踪阈值
def process_frame(img):
# 记录该帧开始处理的时间
start_time = time.time()
# 获取图像宽高
h, w = img.shape[0], img.shape[1]
# BGR转RGB
img_RGB = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
# 将RGB图像输入模型,获取预测结果
results = pose.process(img_RGB)
if results.pose_landmarks: # 若检测出人体关键点
# 可视化关键点及骨架连线
mp_drawing.draw_landmarks(img, results.pose_landmarks, mp_pose.POSE_CONNECTIONS)
for i in range(33): # 遍历所有33个关键点,可视化
# 获取该关键点的三维坐标
cx = int(results.pose_landmarks.landmark[i].x * w)
cy = int(results.pose_landmarks.landmark[i].y * h)
cz = results.pose_landmarks.landmark[i].z
radius = 10
if i == 0: # 鼻尖
img = cv2.circle(img,(cx,cy), radius, (0,0,255), -1)
elif i in [11,12]: # 肩膀
img = cv2.circle(img,(cx,cy), radius, (223,155,6), -1)
elif i in [23,24]: # 髋关节
img = cv2.circle(img,(cx,cy), radius, (1,240,255), -1)
elif i in [13,14]: # 胳膊肘
img = cv2.circle(img,(cx,cy), radius, (140,47,240), -1)
elif i in [25,26]: # 膝盖
img = cv2.circle(img,(cx,cy), radius, (0,0,255), -1)
elif i in [15,16,27,28]: # 手腕和脚腕
img = cv2.circle(img,(cx,cy), radius, (223,155,60), -1)
elif i in [17,19,21]: # 左手
img = cv2.circle(img,(cx,cy), radius, (94,218,121), -1)
elif i in [18,20,22]: # 右手
img = cv2.circle(img,(cx,cy), radius, (16,144,247), -1)
elif i in [27,29,31]: # 左脚
img = cv2.circle(img,(cx,cy), radius, (29,123,243), -1)
elif i in [28,30,32]: # 右脚
img = cv2.circle(img,(cx,cy), radius, (193,182,255), -1)
elif i in [9,10]: # 嘴
img = cv2.circle(img,(cx,cy), radius, (205,235,255), -1)
elif i in [1,2,3,4,5,6,7,8]: # 眼及脸颊
img = cv2.circle(img,(cx,cy), radius, (94,218,121), -1)
else: # 其它关键点
img = cv2.circle(img,(cx,cy), radius, (0,255,0), -1)
# 展示图片
# look_img(img)
else:
scaler = 1
failure_str = 'No Person'
img = cv2.putText(img, failure_str, (25 * scaler, 100 * scaler), cv2.FONT_HERSHEY_SIMPLEX, 1.25 * scaler, (255, 0, 255), 2 * scaler)
# print('从图像中未检测出人体关键点,报错。')
# 记录该帧处理完毕的时间
end_time = time.time()
# 计算每秒处理图像帧数FPS
FPS = 1/(end_time - start_time)
scaler = 1
# 在图像上写FPS数值,参数依次为:图片,添加的文字,左上角坐标,字体,字体大小,颜色,字体粗细
img = cv2.putText(img, 'FPS '+str(int(FPS)), (25 * scaler, 50 * scaler), cv2.FONT_HERSHEY_SIMPLEX, 1.25 * scaler, (255, 0, 255), 2 * scaler)
return img
# 调用摄像头逐帧实时处理模板
# 不需修改任何代码,只需定义process_frame函数即可
# 同济子豪兄 2021-7-8
# 导入opencv-python
import cv2
import time
# 获取摄像头,传入0表示获取系统默认摄像头
cap = cv2.VideoCapture(1)
# 打开cap
cap.open(0)
# 无限循环,直到break被触发
while cap.isOpened():
# 获取画面
success, frame = cap.read()
if not success:
break
## !!!处理帧函数
frame = process_frame(frame)
# 展示处理后的三通道图像
cv2.imshow('my_window', frame)
if cv2.waitKey(1) in [ord('q'),27]: # 按键盘上的q或esc退出(在英文输入法下)
break
# 关闭摄像头
cap.release()
# 关闭图像窗口
cv2.destroyAllWindows()
可以运行 不放丑照了
5、视频处理
# opencv-python
import cv2
# mediapipe人工智能工具包
import mediapipe as mp
# 进度条库
from tqdm import tqdm
# 时间库
import time
# 导入solution
mp_pose = mp.solutions.pose
# # 导入绘图函数
mp_drawing = mp.solutions.drawing_utils
# 导入模型
pose = mp_pose.Pose(static_image_mode=False, # 是静态图片还是连续视频帧
model_complexity=2, # 选择人体姿态关键点检测模型,0性能差但快,2性能好但慢,1介于两者之间
smooth_landmarks=True, # 是否平滑关键点
min_detection_confidence=0.5, # 置信度阈值
min_tracking_confidence=0.5) # 追踪阈值
def process_frame(img):
'''
B站:同济子豪兄(https://space.bilibili.com/1900783)
微信公众号:人工智能小技巧
'''
# 记录该帧开始处理的时间
start_time = time.time()
# 获取图像宽高
h, w = img.shape[0], img.shape[1]
# BGR转RGB
img_RGB = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
# 将RGB图像输入模型,获取预测结果
results = pose.process(img_RGB)
if results.pose_landmarks: # 若检测出人体关键点
# 可视化关键点及骨架连线
mp_drawing.draw_landmarks(img, results.pose_landmarks, mp_pose.POSE_CONNECTIONS)
for i in range(33): # 遍历所有33个关键点,可视化
# 获取该关键点的三维坐标
cx = int(results.pose_landmarks.landmark[i].x * w)
cy = int(results.pose_landmarks.landmark[i].y * h)
cz = results.pose_landmarks.landmark[i].z
radius = 10
if i == 0: # 鼻尖
img = cv2.circle(img,(cx,cy), radius, (0,0,255), -1)
elif i in [11,12]: # 肩膀
img = cv2.circle(img,(cx,cy), radius, (223,155,6), -1)
elif i in [23,24]: # 髋关节
img = cv2.circle(img,(cx,cy), radius, (1,240,255), -1)
elif i in [13,14]: # 胳膊肘
img = cv2.circle(img,(cx,cy), radius, (140,47,240), -1)
elif i in [25,26]: # 膝盖
img = cv2.circle(img,(cx,cy), radius, (0,0,255), -1)
elif i in [15,16,27,28]: # 手腕和脚腕
img = cv2.circle(img,(cx,cy), radius, (223,155,60), -1)
elif i in [17,19,21]: # 左手
img = cv2.circle(img,(cx,cy), radius, (94,218,121), -1)
elif i in [18,20,22]: # 右手
img = cv2.circle(img,(cx,cy), radius, (16,144,247), -1)
elif i in [27,29,31]: # 左脚
img = cv2.circle(img,(cx,cy), radius, (29,123,243), -1)
elif i in [28,30,32]: # 右脚
img = cv2.circle(img,(cx,cy), radius, (193,182,255), -1)
elif i in [9,10]: # 嘴
img = cv2.circle(img,(cx,cy), radius, (205,235,255), -1)
elif i in [1,2,3,4,5,6,7,8]: # 眼及脸颊
img = cv2.circle(img,(cx,cy), radius, (94,218,121), -1)
else: # 其它关键点
img = cv2.circle(img,(cx,cy), radius, (0,255,0), -1)
# 展示图片
# look_img(img)
else:
scaler = 1
failure_str = 'No Person'
img = cv2.putText(img, failure_str, (25 * scaler, 100 * scaler), cv2.FONT_HERSHEY_SIMPLEX, 1.25 * scaler, (255, 0, 255), 2 * scaler)
# print('从图像中未检测出人体关键点,报错。')
# 记录该帧处理完毕的时间
end_time = time.time()
# 计算每秒处理图像帧数FPS
FPS = 1/(end_time - start_time)
scaler = 1
# 在图像上写FPS数值,参数依次为:图片,添加的文字,左上角坐标,字体,字体大小,颜色,字体粗细
img = cv2.putText(img, 'FPS '+str(int(FPS)), (25 * scaler, 50 * scaler), cv2.FONT_HERSHEY_SIMPLEX, 1.25 * scaler, (255, 0, 255), 2 * scaler)
return img
# 视频逐帧处理代码模板
# 不需修改任何代码,只需定义process_frame函数即可
# 同济子豪兄 2021-7-10
def generate_video(input_path='./videos/three-hands.mp4'):
filehead = input_path.split('/')[-1]
output_path = "out-" + filehead
print('视频开始处理',input_path)
# 获取视频总帧数
cap = cv2.VideoCapture(input_path)
frame_count = 0
while(cap.isOpened()):
success, frame = cap.read()
frame_count += 1
if not success:
break
cap.release()
print('视频总帧数为',frame_count)
# cv2.namedWindow('Crack Detection and Measurement Video Processing')
cap = cv2.VideoCapture(input_path)
frame_size = (cap.get(cv2.CAP_PROP_FRAME_WIDTH), cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
# fourcc = int(cap.get(cv2.CAP_PROP_FOURCC))
# fourcc = cv2.VideoWriter_fourcc(*'XVID')
fourcc = cv2.VideoWriter_fourcc(*'mp4v')
fps = cap.get(cv2.CAP_PROP_FPS)
out = cv2.VideoWriter(output_path, fourcc, fps, (int(frame_size[0]), int(frame_size[1])))
# 进度条绑定视频总帧数
with tqdm(total=frame_count-1) as pbar:
try:
while(cap.isOpened()):
success, frame = cap.read()
if not success:
break
# 处理帧
# frame_path = './temp_frame.png'
# cv2.imwrite(frame_path, frame)
try:
frame = process_frame(frame)
except:
print('error')
pass
if success == True:
# cv2.imshow('Video Processing', frame)
out.write(frame)
# 进度条更新一帧
pbar.update(1)
# if cv2.waitKey(1) & 0xFF == ord('q'):
# break
except:
print('中途中断')
pass
cv2.destroyAllWindows()
out.release()
cap.release()
print('视频已保存', output_path)
generate_video(input_path='./badminton.mp4')
(此处找了一个打羽毛球的视频)

二、Google Colabor部分
(示例深蹲)(需要进入谷歌)
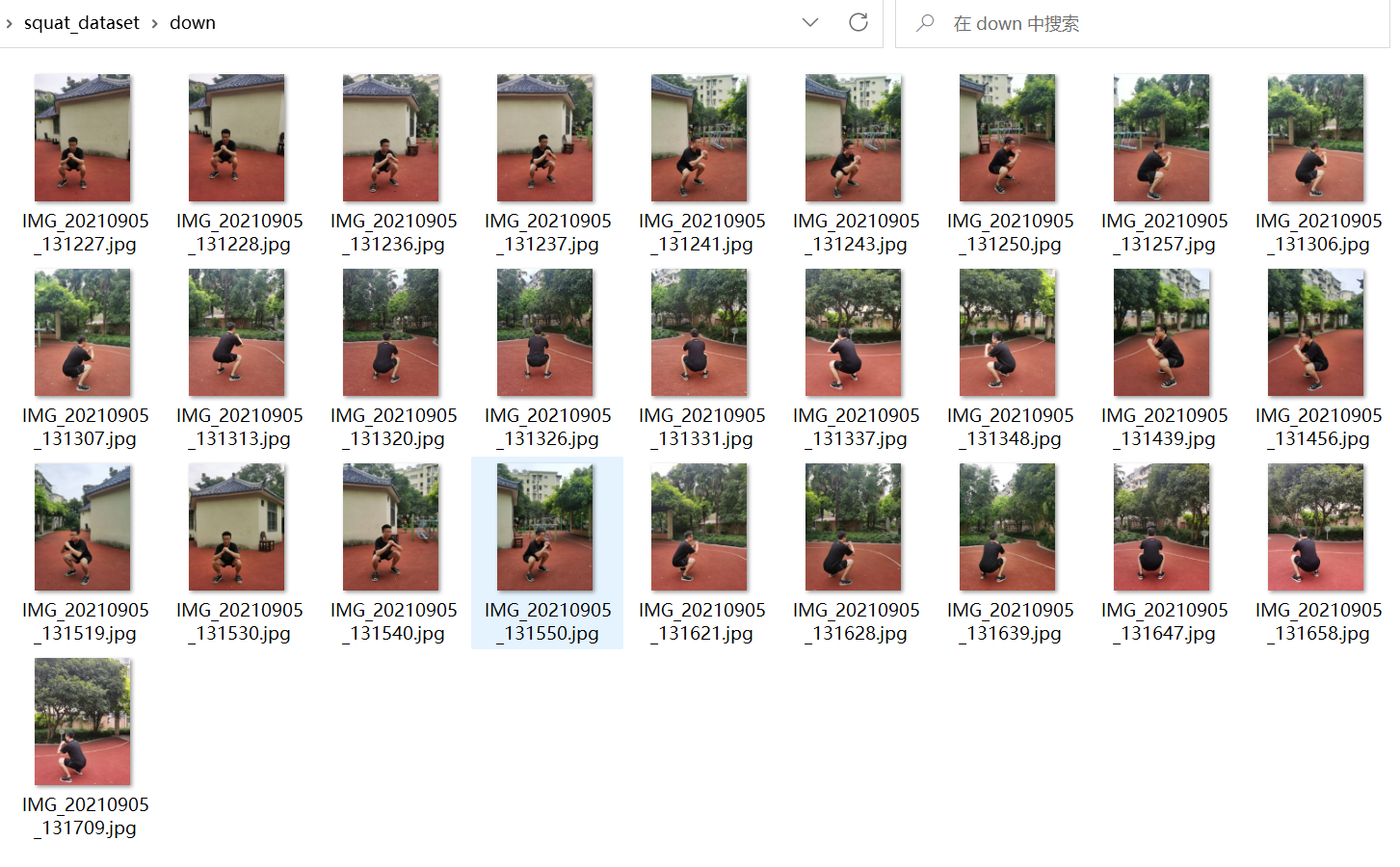
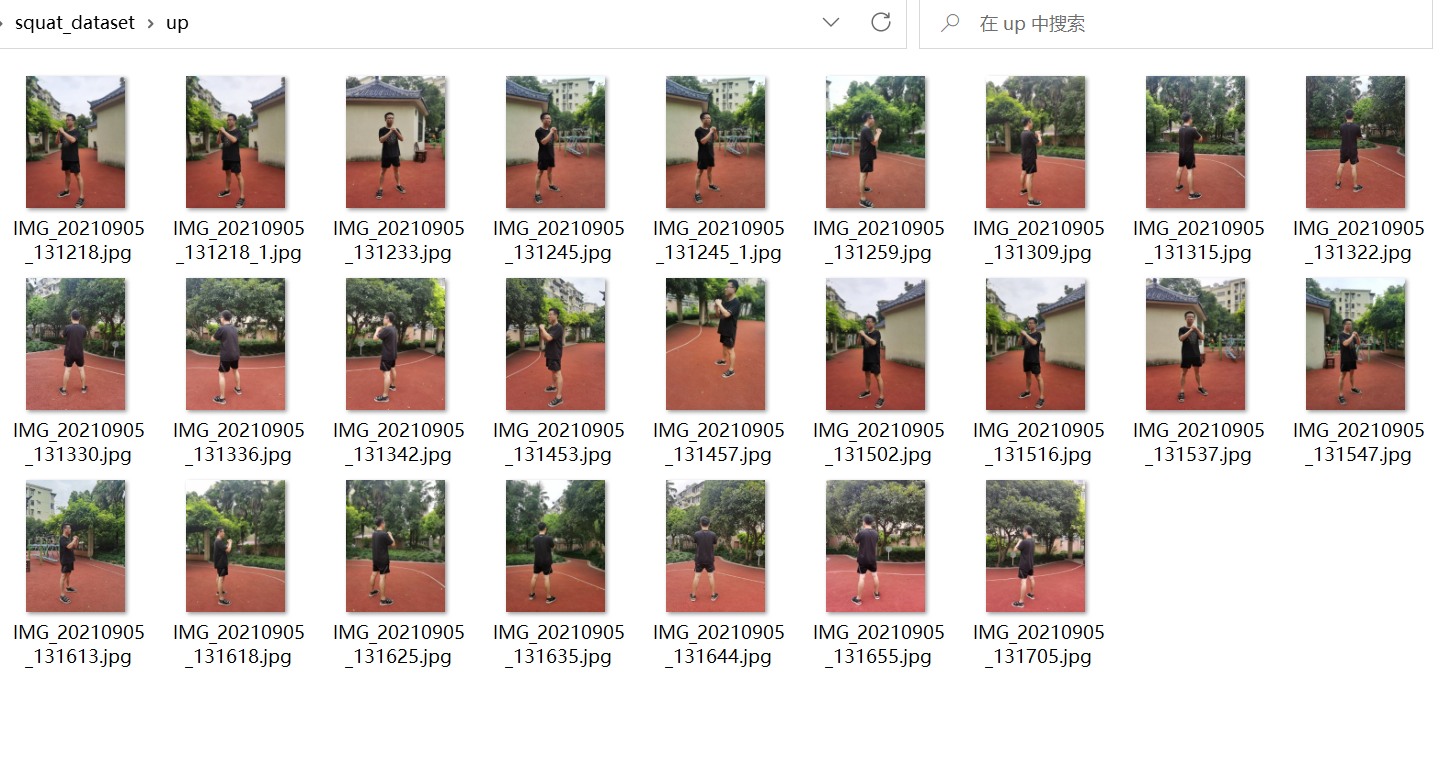
1、数据集
squat_dataset
- down
- up
2、数据集处理
- 对每个图片进行处理 对每个图片识别出有33个关节点
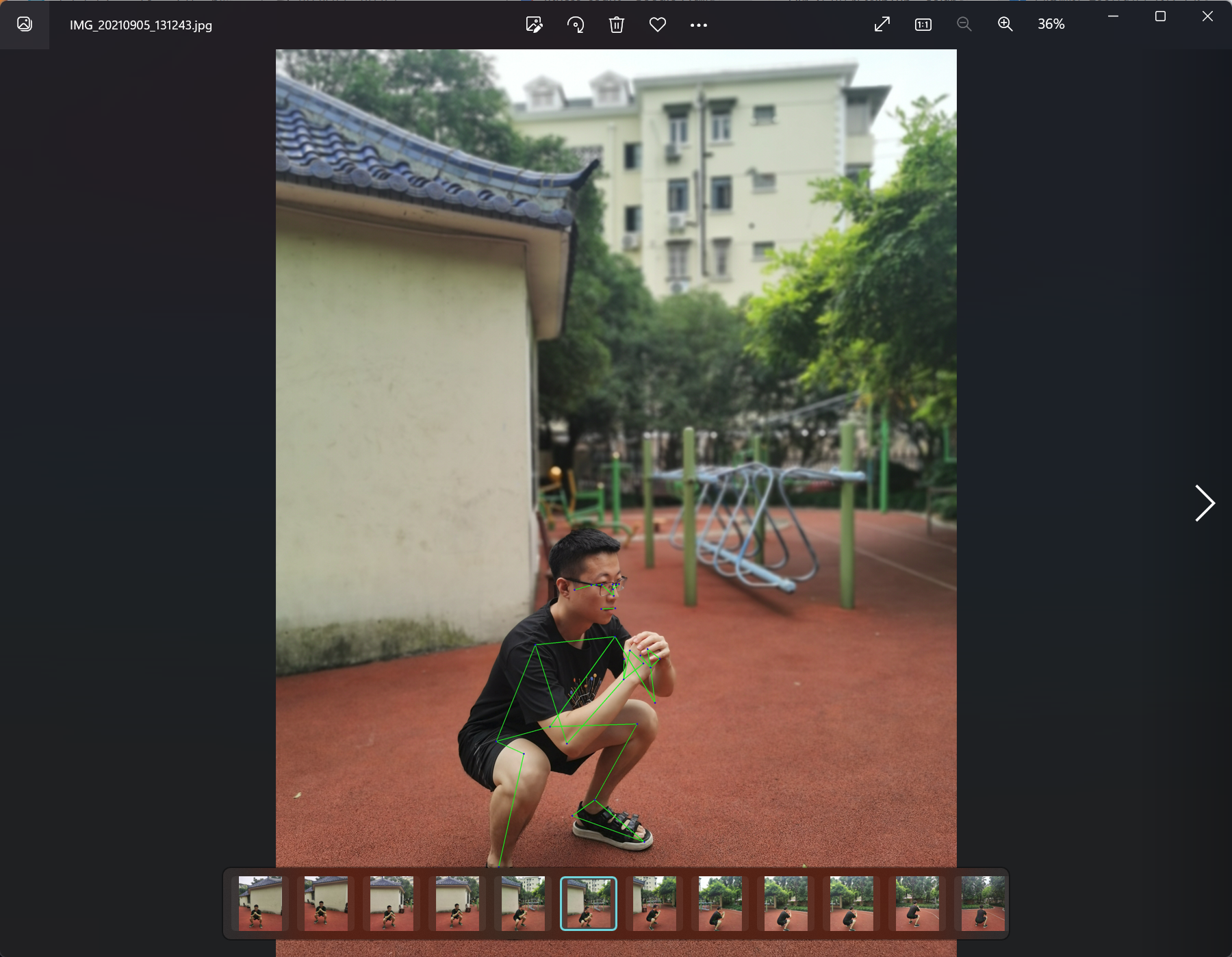
- 每个点在3维坐标系下有x y z ,生成的csv中 每个图片有3*33=99个数据
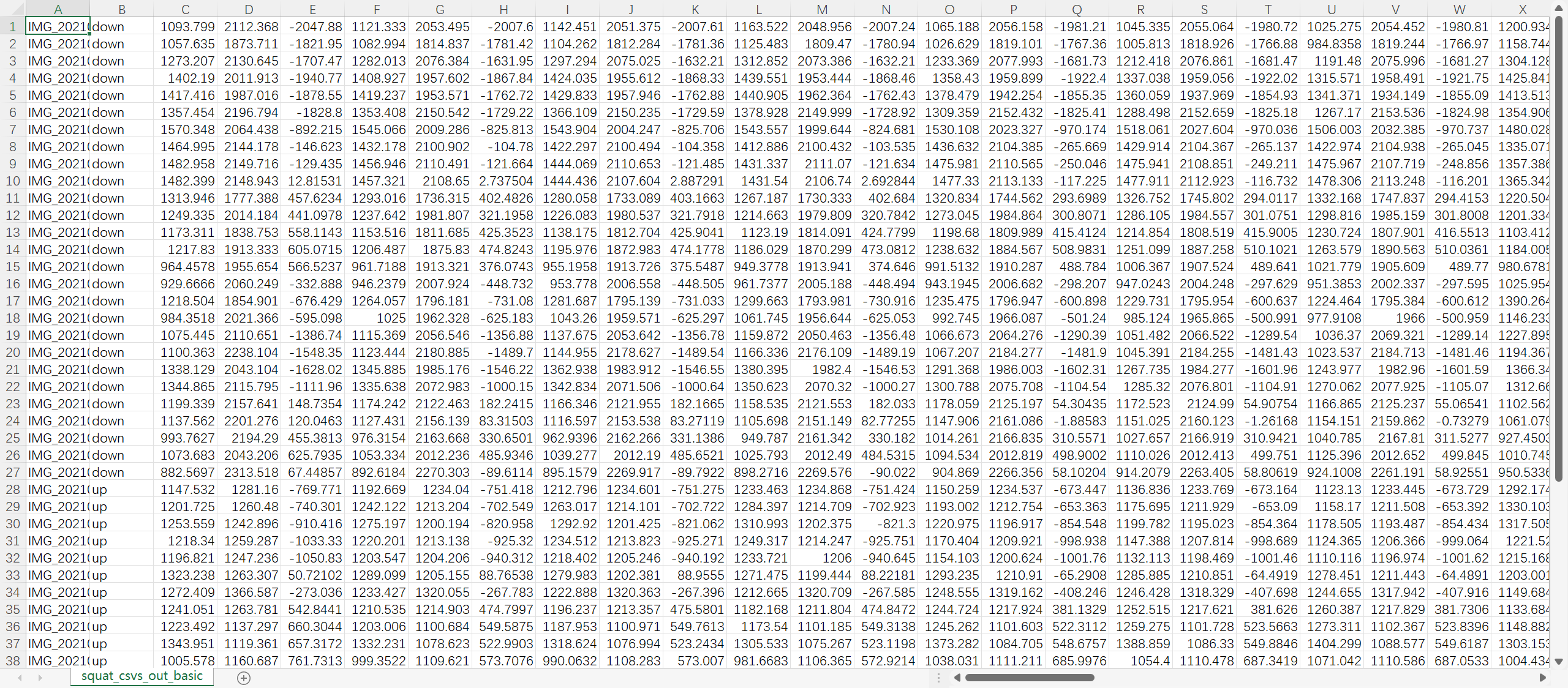
- 对视频进行预测

三、 安卓开发部分
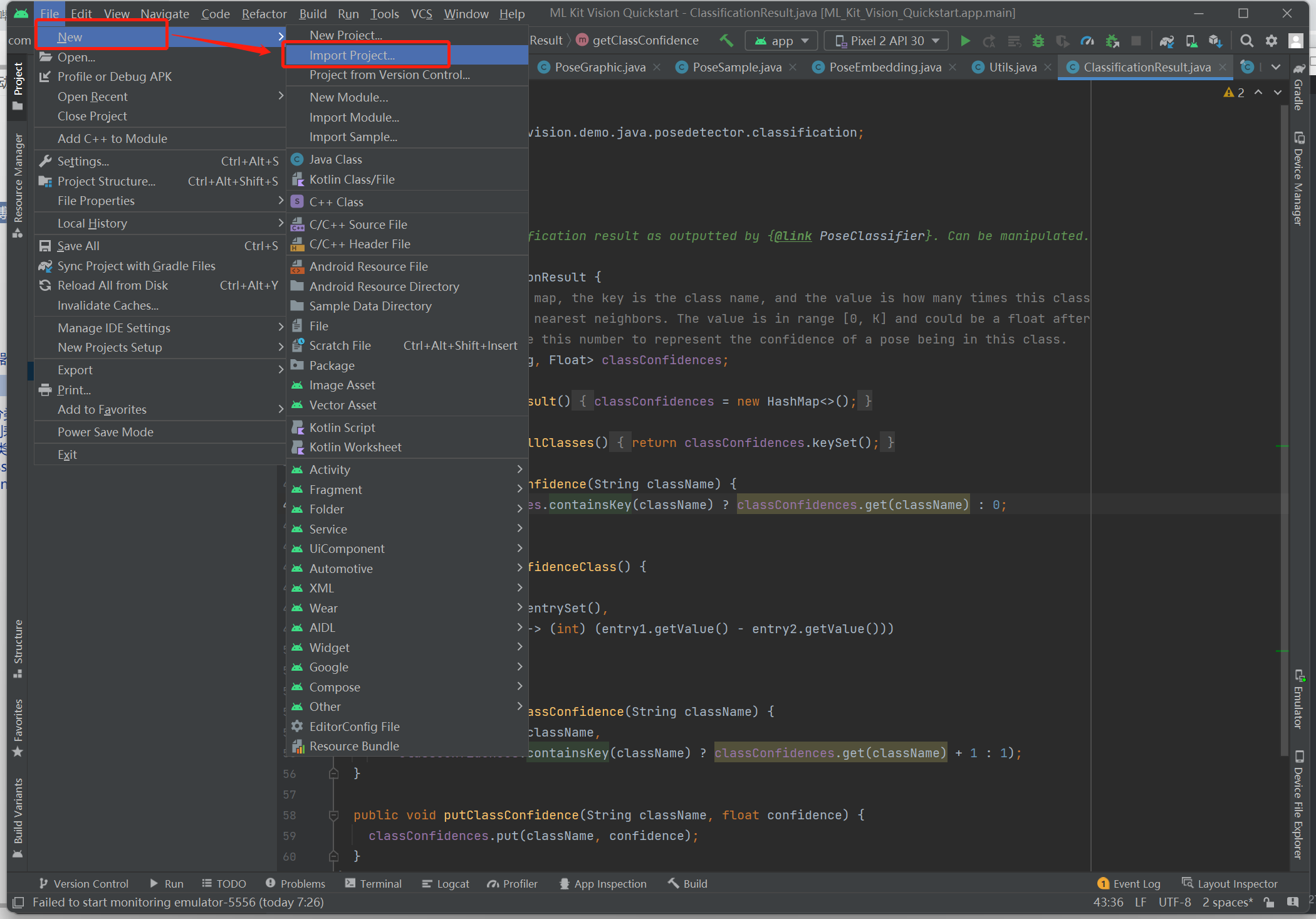
1、导入项目
2、添加一个device
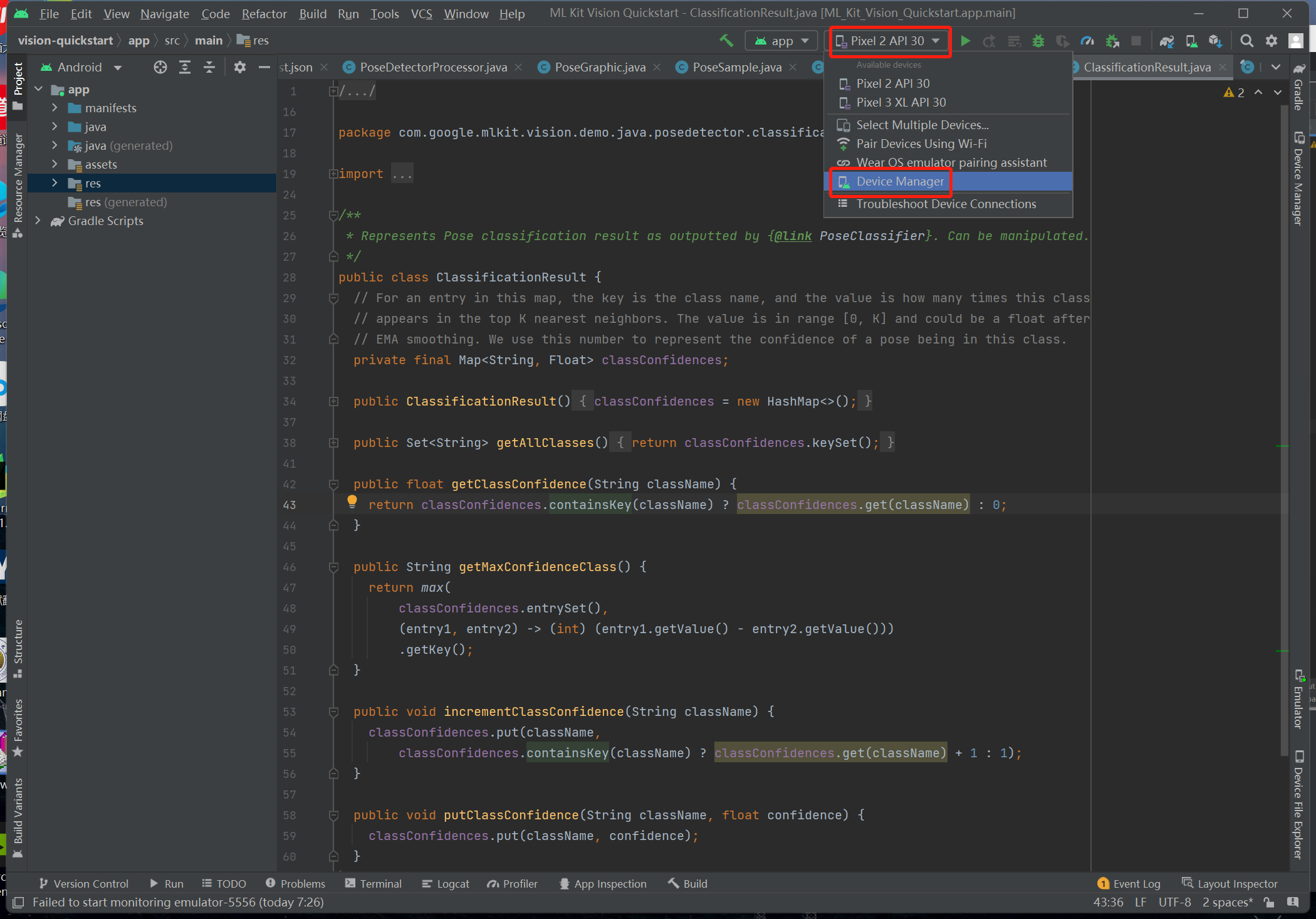
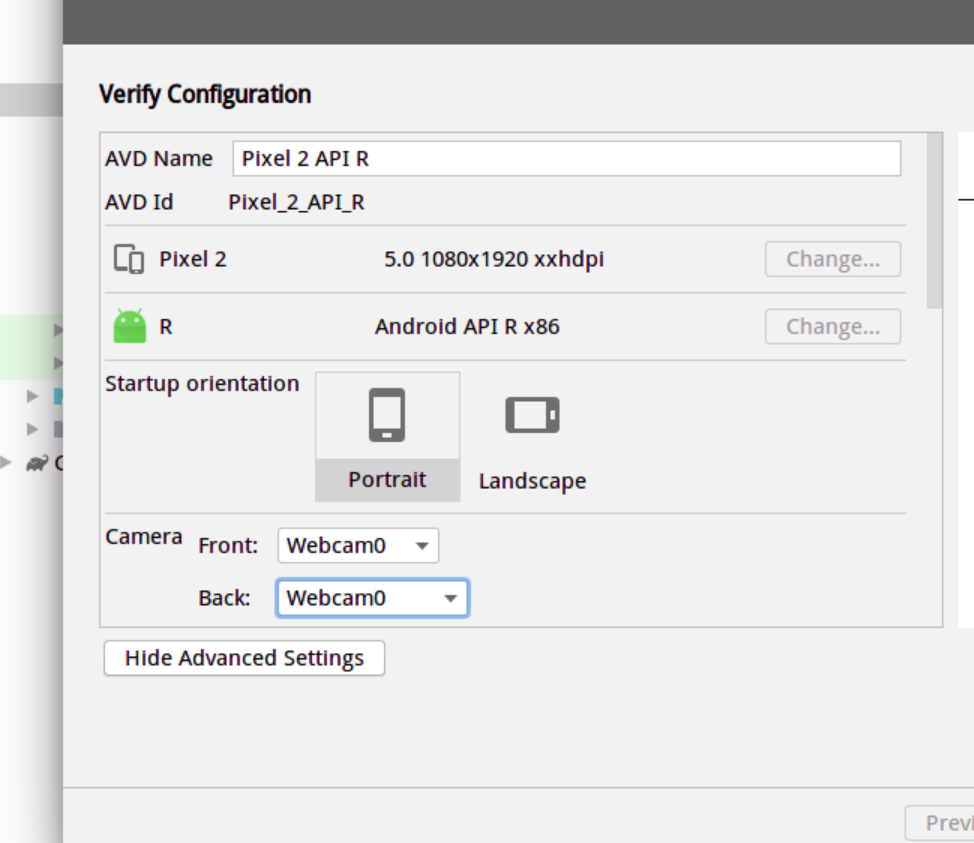
(API选择30 选择高级设置下面的摄像机为webcam0)
3、运行
点击运行键

注意:在右上角设置中 打开深蹲计数器
代码来自同济自豪兄 侵权删
posted on 2022-07-31 10:52 monster-little 阅读(510) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号