基于知识图谱的运动推荐
基于知识图谱的的运动推荐
一、数据集
https://www.kaggle.com/datasets/edoardoba/fitness-exercises-with-animations(下载地址)
由于只是测试 第二个数据集是自己随机构造的
1、原始数据集
身体部位 运动要用到的器材 运动动图的路径 id 运动的名称 目标

用户 运动 对其评分
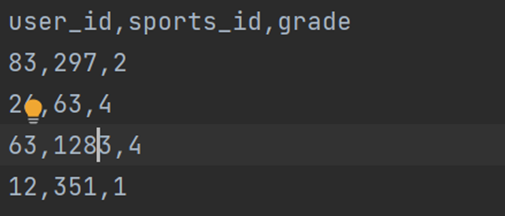
2、数据预处理
所有运动的名称
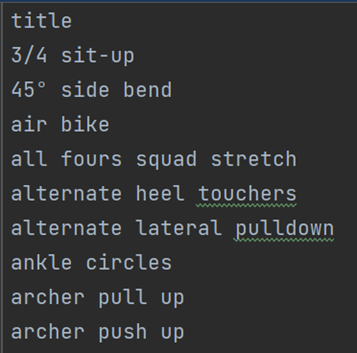
运动所要用到的身体部位

运动要用到的器材
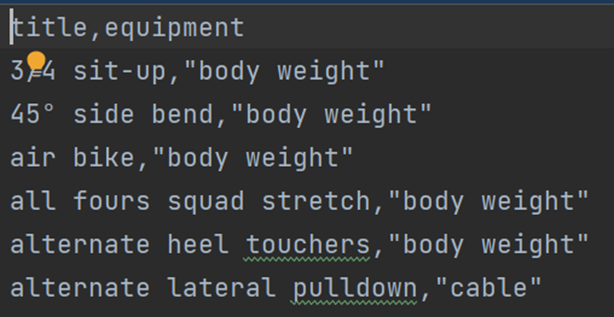
不同用户对不同运动的评分
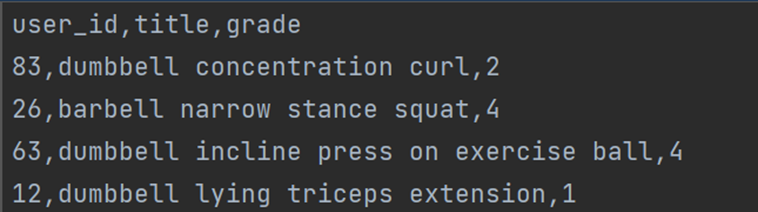
import pandas as pd
import re
pd.set_option('display.max_columns', None)
def FITNESS_EXERCISE():
pattern = re.compile("[A-Za-z0-9]+")
out_sports = open("dataset2/out_sports.csv", "w", encoding='utf-8')
out_sports.write("title\n")
out_bodypart = open("dataset2/out_bodypart.csv","w",encoding='utf-8') #写出来的csv存放在哪
out_bodypart.write("title,bodypart\n")
out_equipment = open("dataset2/out_equipment.csv","w",encoding='utf-8')
out_equipment.write("title,equipment\n")
out_gifUrl = open("dataset2/out_gifUrl.csv","w",encoding='utf-8')
out_gifUrl.write("title,gifUrl\n")
out_grade = open("dataset2/out_grade.csv", "w", encoding='utf-8')
out_grade.write("user_id,title,grade\n")
df = pd.read_csv("dataset2/fitness_exercises.csv", sep=",")
df1 = pd.read_csv("dataset2/combined.csv", sep=",")
print(df.head())
d_sport = dict()
s_sport = set()
for _, row in df.iterrows():
sport_id = row['id']
title = row['name']
d_sport[sport_id] = title
if title in s_sport:
continue
s_sport.add(title)
out_sports.write(f"{title}\n")
bodypart = row['bodyPart']
bodypart = "\"" + bodypart + "\""
out_bodypart.write(f"{title},{bodypart}\n")
equipment = row['equipment']
equipment = "\"" + equipment + "\""
out_equipment.write(f"{title},{equipment}\n")
gifUrl = row['gifUrl']
gifUrl = "\"" + gifUrl + "\""
out_gifUrl.write(f"{title},{gifUrl}\n")
for _, row in df1.iterrows():
user_id = row['user_id']
sport_id = row['sports_id']
if(sport_id in d_sport):
title = d_sport[sport_id]
grade = row['grade']
out_grade.write(f"{user_id},{title},{grade}\n")
# print(d_sport)
# print(s_sport)
if __name__ == "__main__":
FITNESS_EXERCISE()
生成的csv文件如下
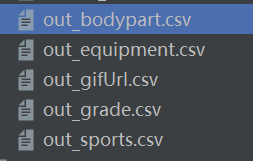
将这几个csv文件放到 D:\Neo4j\neo4j-community-4.4.8\import(下载的neo4j的安装目录下)
3、用neo4j 构建知识图谱
启动neo4j (neo4j需要配置环境变量)具体见https://blog.csdn.net/xuan314708889/article/details/103858493?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522165922866416782388053719%2522%252C%2522scm%2522%253A%252220140713.130102334..%2522%257D&request_id=165922866416782388053719&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2allsobaiduend~default-1-103858493-null-null.142v35pc_rank_34&utm_term=neo4j%E9%85%8D%E7%BD%AE%E7%8E%AF%E5%A2%83%E5%8F%98%E9%87%8F&spm=1018.2226.3001.4187
打开cmd 输入 neo4j.bat console
在浏览器打开 http://localhost:7474/
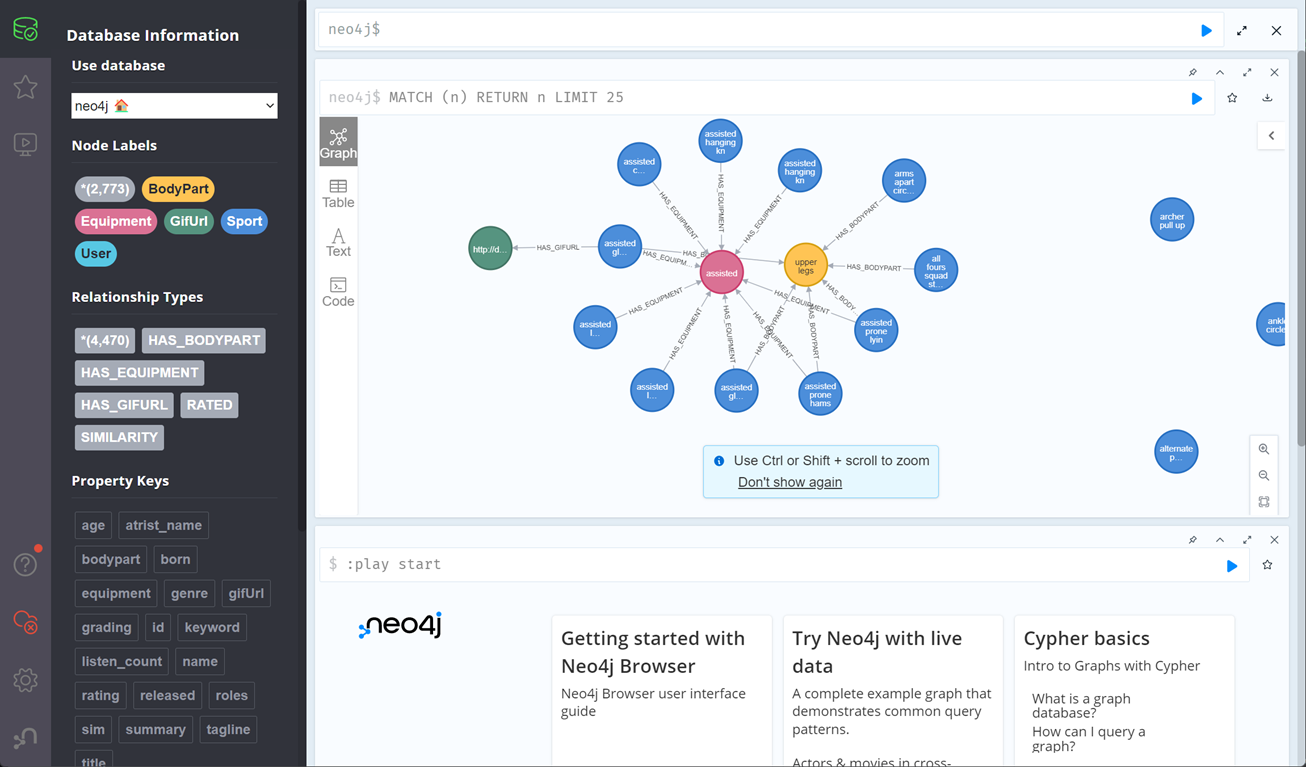
(每个运动有属性:器材 身体部位 gifURL )
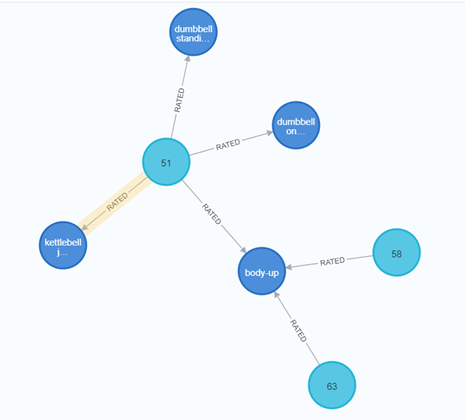
( 每个用户有对其做过的运动的评分 )
4、通过计算用户与用户之间的相似度(余弦相似度)进行推荐
(基于用户的协调过滤推荐)
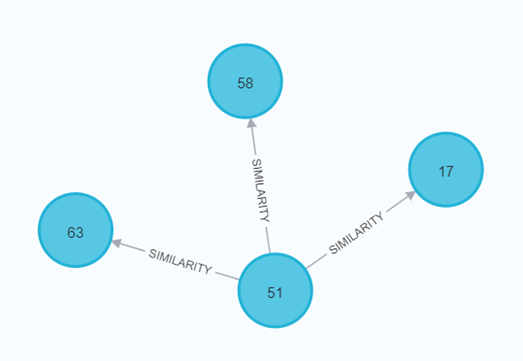
(计算每个用户之间的相似度)
#基于用户的协同过滤推荐
from neo4j import GraphDatabase
import pandas as pd
uri = "neo4j://localhost:7687"
driver = GraphDatabase.driver(uri, auth=("neo4j", "12345"))
k = 10 # nearest neighbors (most similar users) to consider
sports_common = 1 # how many movies in common to be consider an user similar
users_common = 1 # minimum number of similar users that have seen the movie to consider it
threshold_sim = 0.1 # threshold to consider users similar
def load_data():
with driver.session() as session:
session.run("""MATCH ()-[r]->() DELETE r""")
session.run("""MATCH (r) DELETE r""")
print("Loading sports...")
#加载数据,创建Movie标签,title属性的实体
session.run("""
LOAD CSV WITH HEADERS FROM "file:///out_sports.csv" AS csv
CREATE (:Sport {title: csv.title})
""")
print("Loading gradings...")
#加载评分数据, MERGE是搜索给定模式,如果存在,则返回结果如果它不存在于图中,则它创建新的节点/关系并返回结果。
session.run("""
LOAD CSV WITH HEADERS FROM "file:///out_grade.csv" AS csv
MERGE (m:Sport {title: csv.title})
MERGE (u:User {id: toInteger(csv.user_id)})
CREATE (u)-[:RATED {grading : toInteger(csv.grade)}]->(m)
""")
#加载影片类型数据
print("Loading bodypart...")
session.run("""
LOAD CSV WITH HEADERS FROM "file:///out_bodypart.csv" AS csv
MERGE (m:Sport {title: csv.title})
MERGE (g:BodyPart {bodypart: csv.bodypart})
CREATE (m)-[:HAS_BODYPART]->(g)
""")
print("Loading equipment...")
#加载关键词数据
session.run("""
LOAD CSV WITH HEADERS FROM "file:///out_equipment.csv" AS csv
MERGE (m:Sport {title: csv.title})
MERGE (k:Equipment {equipment: csv.equipment})
CREATE (m)-[:HAS_EQUIPMENT]->(k)
""")
print("Loading gifUrl...")
#制片人
session.run("""
LOAD CSV WITH HEADERS FROM "file:///out_gifUrl.csv" AS csv
MERGE (m:Sport {title: csv.title})
MERGE (p:GifUrl {gifUrl: csv.gifUrl})
CREATE (m)-[:HAS_GIFURL]->(p)
""")
def queries():
while True:
userid = int(input("请输入要为哪位用户推荐锻炼,输入其ID即可: "))
m = int(input("为该用户推荐多少个锻炼呢? "))
genres = []
if int(input("是否需要过滤掉不需要的锻炼部位?(输入0或1)")):#过滤掉不喜欢的类型
with driver.session() as session:
try:
q = session.run(f"""MATCH (g:BodyPart) RETURN g.bodypart AS bodypart""")
result = []
for i, r in enumerate(q):
result.append(r["bodypart"])#找到图谱中所有的电影类型
df = pd.DataFrame(result, columns=["bodypart"])
print()
print(df)
inp = input("输入不需要的锻炼类型索引即可,例如:1 2 3 ")
if len(inp) != 0:
inp = inp.split(" ")
genres = [df["bodypart"].iloc[int(x)] for x in inp]
except:
print("Error")
with driver.session() as session:#找到当前ID评分的电影
q = session.run(f"""
MATCH (u1:User {{id : {userid}}})-[r:RATED]-(m:Sport)
RETURN m.title AS title, r.grading AS grade
ORDER BY grade DESC
""")
print()
print("Your ratings are the following:")
result = []
for r in q:
result.append([r["title"], r["grade"]])
if len(result) == 0:
print("No ratings found")
else:
df = pd.DataFrame(result, columns=["title", "grade"])
print()
print(df.to_string(index=False))
print()
session.run(f"""
MATCH (u1:User)-[s:SIMILARITY]-(u2:User)
DELETE s
""")
#找到当前用户评分的电影以及这些电影被其他用户评分的用户,with是把查询集合当做结果以便后面用where 余弦相似度计算
session.run(f"""
MATCH (u1:User {{id : {userid}}})-[r1:RATED]-(m:Sport)-[r2:RATED]-(u2:User)
WITH
u1, u2,
COUNT(m) AS sports_common,
SUM(r1.grading * r2.grading)/(SQRT(SUM(r1.grading^2)) * SQRT(SUM(r2.grading^2))) AS sim
WHERE sports_common >= {sports_common} AND sim > {threshold_sim}
MERGE (u1)-[s:SIMILARITY]-(u2)
SET s.sim = sim
""")
Q_GENRE = ""
if (len(genres) > 0):
Q_GENRE = "AND ((SIZE(gen) > 0) AND "
Q_GENRE += "(ANY(x IN " + str(genres) + " WHERE x IN gen))"
Q_GENRE += ")"
#找到相似的用户,然后看他们喜欢什么电影 Collect:将所有值收集到一个集合list中
q = session.run(f"""
MATCH (u1:User {{id : {userid}}})-[s:SIMILARITY]-(u2:User)
WITH u1, u2, s
ORDER BY s.sim DESC LIMIT {k}
MATCH (m:Sport)-[r:RATED]-(u2)
OPTIONAL MATCH (g:BodyPart)--(m)
WITH u1, u2, s, m, r, COLLECT(DISTINCT g.bodypart) AS gen
WHERE NOT((m)-[:RATED]-(u1)) {Q_GENRE}
WITH
m.title AS title,
SUM(r.grading * s.sim)/SUM(s.sim) AS grade,
COUNT(u2) AS num,
gen
WHERE num >= {users_common}
RETURN title, grade, num, gen
ORDER BY grade DESC, num DESC
LIMIT {m}
""")
print("Recommended sports:")
result = []
for r in q:
result.append([r["title"], r["grade"], r["num"], r["gen"]])
if len(result) == 0:
print("No recommendations found")
print()
continue
df = pd.DataFrame(result, columns=["title", "avg grade", "num recommenders", "bodypart"])
print()
print(df.to_string(index=False))
print()
if __name__ == "__main__":
if int(input("是否需要重新加载并创建知识图谱?(请选择输入0或1)")):
load_data()
queries()
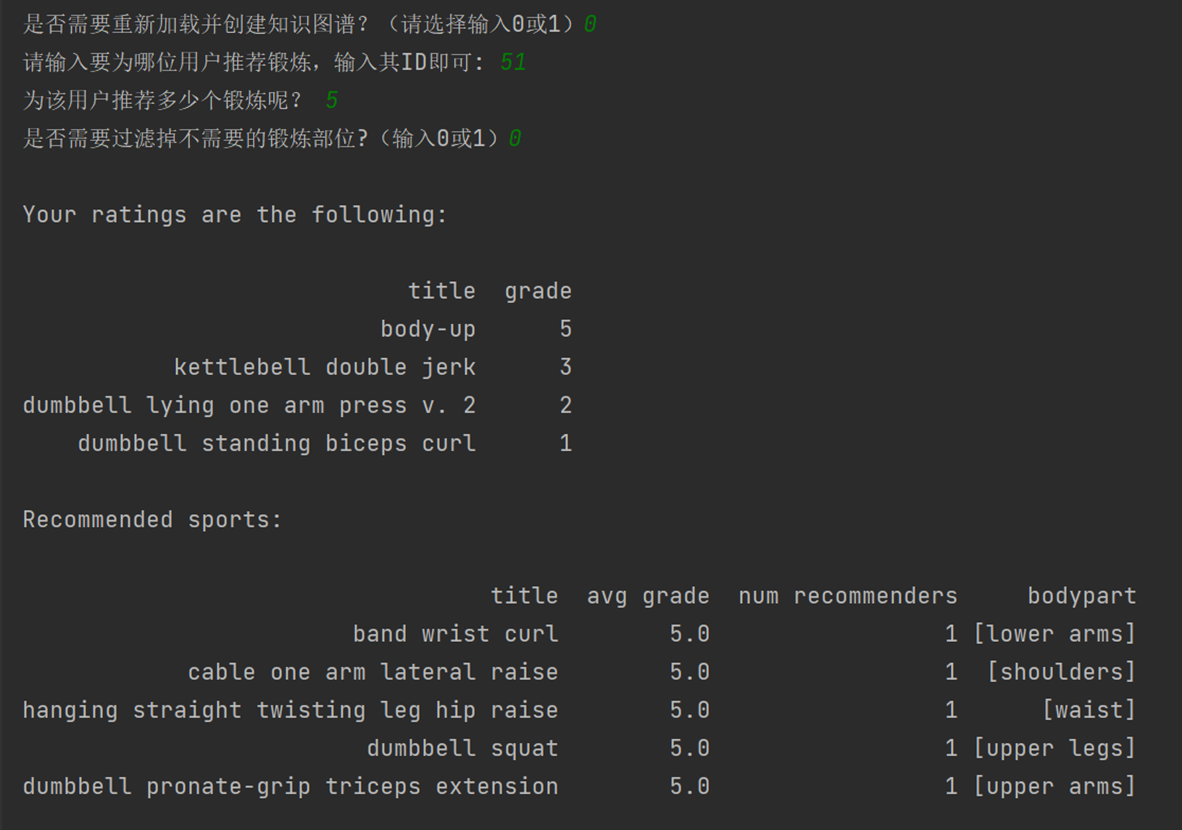
运行结果如下
posted on 2022-08-03 12:01 monster-little 阅读(310) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号