论文阅记 SRCNN
论文题目:Image Super-Resolution Using Deep Convolutional Networks
文献地址:https://arxiv.org/pdf/1501.00092.pdf
代码地址:http://mmlab.ie.cuhk.edu.hk/projects/SRCNN.html
参考代码地址(tensorflow版本):https://github.com/tegg89/SRCNN-Tensorflow
图像超分辨率重建:指通过低分辨率图像或图像序列恢复出高分辨率图像。高分辨率图像意味着图像具有更多的细节信息、更细腻的画质。这些细节在高清电视、医学成像、遥感卫星成像等领域有着重要的应用价值。【分辨率不是图像的大小!】
本篇是一篇非常经典的超分辨率技术,在深度学习或卷积神经网络(CNN)中,通常使用CNN进行图像分类,目标检测等。在SRCNN中,它被用于单幅图像的超分辨率(SR),这是计算机视觉中的一个经典问题。
简而言之,使用更好的SR方法,可以获得更好的图像质量,即使最初只得到一个小图像。
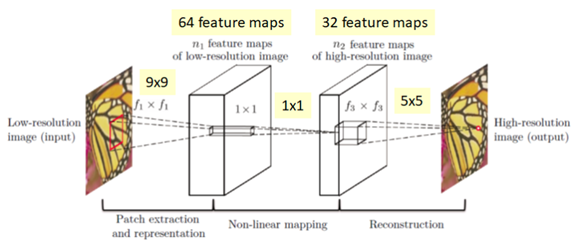
SRCNN网络结构
SRCNN网络并不深。只有3层,分别是patch提取与表示、非线性映射和重构,如下图所示:
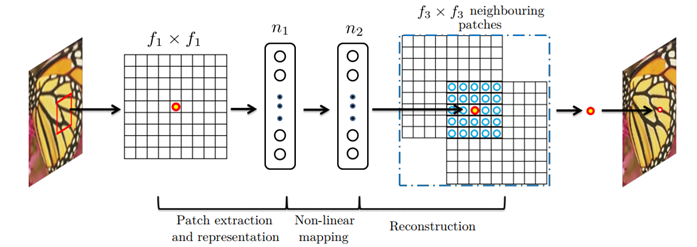
patch提取与表示
在输入到SRCNN网络之前,首先要知道低分辨率的输入是经过双三次插值的(即对高分辨率的原图进行两次插值,一次缩小,一次放大,得到的图像分辨率明显降低)。
X: 高分辨率图像
Y:低分辨率图像(X经过双三次样条插值得到)
第一层使用ReLU激活函数:
![]()
参数量:
- W1:c×f1×f1×n1
- B1: n1
其中,c是图像的通道数量,f1是卷积核的尺寸,n1是卷积核的格式。第一层中,c=1,f1=9,n1=64。
非线性映射
第二层进行非线性映射:
![]()
参数量:
- W2:n1×1×1×n2
- B2: n2
它是一个n维向量到n维向量的映射。当n1>n2的时候,可以想象类似于PCA的东西但是是以非线性的方式。
在第二层中 n2=32 。 (小于第一层)
重建
第三层,对图像进行重建,使用卷积核的个数将与原图像的通道数量相同。
![]()
参数量:
- W3:n2×f3×f3×c
- B3: c
在第三层中,f3=5.
综上所述,
- 网络形式:(conv1+relu)—(conv2+relu)—(conv3)
- 卷积核尺寸:9*9 — 1*1— 5*5。
- 网络输入:33×33
-
网络输出:21×21(卷积时无padding)
- 具体而言,会将原图划分为若干个33*33块,每个块生成21*21的图像,最后将若干21*21图像进行拼接还原,生成处理后的图像。
损失函数
损失函数使用比较传统的MSE。
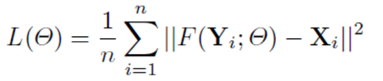
代码理解
使用的代码是tensorflow版的https://github.com/tegg89/SRCNN-Tensorflow。
代码中使用glob.glob得到所有训练集/测试集的图片。先取出3的整数倍的像素值, 以进行下面的图像模糊过程,两次插值,先缩小,再放大得到模糊的图像。
1 input_ = scipy.ndimage.interpolation.zoom(label_, (1./scale), prefilter=False) 2 input_ = scipy.ndimage.interpolation.zoom(input_, (scale/1.), prefilter=False)
模糊图像作为输入的原材料,模糊图像作为输出的原材料。由于网络不深,并且适用于不同大小的图像输入,作者将原材料裁剪成33*33(输入)和21*21(输出),并且分别添加到两个list中,一一对应,然后保存为.h5文件,便于调用。
测试过程中,作者代码中固定为仅对测试集的第3张图像进行处理,所以在运行后只会看到一张图像的结果。此处可以改为第1张图像,但改为批量测试,源代码结构需要大改。
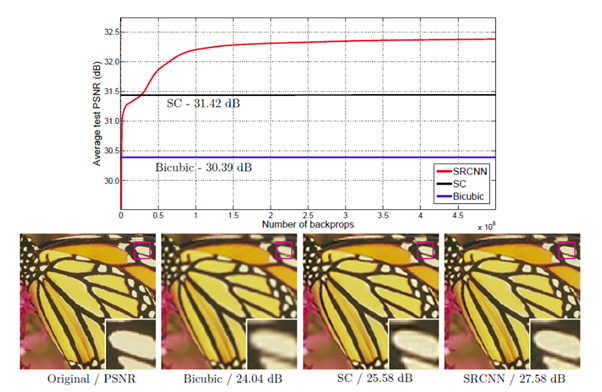
为了对论文处理过程有清晰的了解,需要对代码中添加模糊图像的保存,这样能够清晰的看到网络处理的作用。三次样条插值的模糊图像和处理后的图像如下图所示:

但在第一次测试蝴蝶图像时,出现的结果如下图所示【很好的看出了图像是拼接出来的...哈哈,感觉它暴露了自己】:

-------------------------------------------
算法届的小学生,虔诚而不迷茫,做一个懂生活并有趣的人!
如果觉得这篇文章对你有小小的帮助的话,记得在右下角点个 [推荐] 噢! 欢迎共同交流机器学习,机器视觉,深度学习~
欢迎转载,转载请声明出处!
