经典网络结构(七)DenseNet
论文题目:Densely Connected Convolutional Networks
文献地址:https://arxiv.org/pdf/1608.06993.pdf
源码地址:https://github.com/liuzhuang13/DenseNet
(非官方)源码地址:https://github.com/pudae/tensorflow-densenet

DenseNet的提出主要受ResNet和Inception思想的影响,在网络结构上要么深(ResNet),要么宽(Inception)。如果卷积网络在接近输入层和接近输出层的层之间包含更短的连接,那么在训练时卷积网络可以更深入、更准确、更高效。
在CIFAR和SVHN数据集上的效果

上表展示了不同深度L和不同growth rates k的DenseNet模型在CIFAR和SVHN上的训练的测试结果。可以看出DenseNet-BC(L=190, k=40)在所有CIFAR数据集上都优于现有的模型。在SVNH数据集中,DensNet(L=100,k=24)去的了最好的效果,作者认为250-layers DenseNet-BC没有取得较好的结果是由于SVHN相对较容易,过深的网络可能造成过拟合。
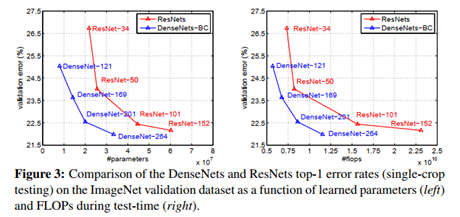
下图是DenseNet-BC和ResNet在Imagenet数据集上的对比,左图是参数量与验证误差的对比,提升还是很明显的,毕竟非劣解前沿!右边是flops(可以理解为计算复杂度)和验证物产的对比,也处于非劣解前沿的状态。
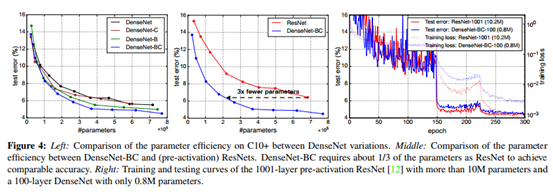
下图左侧图中展示了不同DenseNet的参数量与测试误差的对比;中间图比较了DenseNet-BC与ResNet参数量和测试误差的对比;右侧图中展示了DenseNet-BC与ResNet-1001训练误差和测试误差的对比,DenseNet-BC具有极少的参数量,但却可以达到与ResNet-1001差不多的精度。
优势
- 减轻了梯度消失的问题;
- 加强了特征的传递;
- 高效利用特征(reuse);
- 在一定程度上减少了参数量。
网络结构
深度学习中,虽然网络深度的加深有助于提高模型的表达能力,但随着深度的加深也会出现一个问题:输出和梯度的信息通过很多层时可能会消失。许多研究都在针对解决这一问题,如ResNets、Highway Networks、Stochastic depth 、 FractalNets等。尽管这些不同的方法在网络拓扑结构和训练过程中各不相同,但它们都有一个关键特征:它们创建了从早期层到后期层的捷径。
延续这一关键特征,为了确保网络中各层之间的信息流达到最大,作者将所有层连接起来!为了保持前馈特性,每一层都从前面的所有层获得额外的输入,并将自己的特性映射传递给后面的所有层。如下图所示,每一层均与其他层建立有连接。重要的是,与ResNets不同的是,不会在特征被传递到一个层之前通过求和来组合它们;相反,是通过连接这些特性来组合它们。
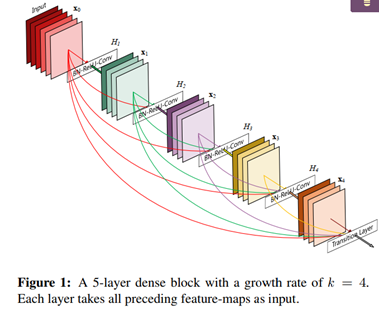
第l层包含l个输入,由之前所有卷积块的特征和输入图像组成。并且第l层的输出将会作为后续L-l个层的输入。因此,对于L-layer的网络,共包含L(L+1)/2个连接,而不是L个连接。简而言之,每一层的输入来与前面所有层的输出。
这种密集连接模式的一个可能与直觉相反的效果是,它比传统的卷积网络需要更少的参数,因为不需要重新学习冗余的特征映射。这怎么理解呢?一方面,其growth rate值较小,即每次输出的通道数量并不会成倍增加;另一方面,在Dense Block之间会包含Transition Layer(1*1卷积)进行通道数量减半,并且每个Dense Block内部的连接之间也包含1*1卷积进行通道数量减半,【详见后文表一的描述】输入通道数量的减少将会极大减少每个卷积核的厚度,即需要更少的参数。参数量的减少会使得Dense block这种结构具有正则化的效果,在一定程度上可以防止过拟合。
DenseNet的一个优点是网络更窄,这种"窄"在于通道数量成倍增长,在dense block中每个卷积层的输出feature map的数量都很小(小于100)。【由于包含不同层之间输出通道数量的融合,所以不能像现有的其他模型,每进行一次卷积运算,通道数量都会成倍增长。】
另一方面,DenseNet可以很好的减轻梯度消失的问题,因为每一层实际上都直接连接input和loss。
整篇论文中仅仅通过两个公式描述了DenseNet与ResNet的区别。
- ResNets,l表示第l层,Hl表示非线性变换(BN、ReLU、Pooling、Conv),xl表示第l层的输出,可以看出,ResNets是特征被传递到一个层之前通过求和来组合它们。
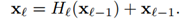
- DenseNet,[x0, x1,... ,xl-1]表示层0到l-1的输出feature map。整合操作Hl包含三种相关操作:BN、ReLU、3*3Conv,与ResNets不同。
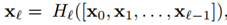
图一表示的是dense block,而下图二表示的则是一个DenseNet的结构图,这个结构图中包含了3个dense block。作者将DenseNet分成多个dense block,原因是希望各个dense block内的feature map的size统一,这样在做concatenation就不会有size的问题。
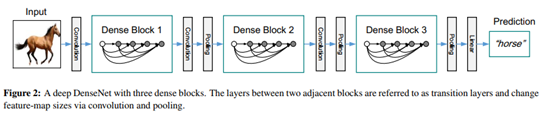
目前为止,关于DenseNet的具体结构还是有些朦胧。下表展示了不同深度DenseNet的具体结构,其中,Transition层中包括BN层和1×1卷积层,和 2×2平均池化层。
在表一的声明中,谈到了一个growth rate 参数k。该参数是做什么的呢?假设每个Hl产生k个feature map,即通道数量,那么第l层的输入的feature map将会包含 k0+k*(l-1)个通道数量。其中,k0表示输入层的通道数量。k实际上生成的就是通道数量,由于越靠后的层包含更多的输入,如果每层输出的通道数量过大,组合后的通道数量将会更大,将产生极大的参数量和运算量。因此,k值的设置实际上也是与其他网络结构的重要区别,也就是之前提到的DenseNet可以有很窄的层,即通道数量没有增长到成百上千,这样可以大大减少参数量。并且在每个Dense Block之间都会包含1*1卷积对输入feature map的通道数量减半;Dense Block中各个卷积操作也是采用Bottleneck layer操作,即先通过1*1卷积进行通道数量的减半,从而极大的减少参数量。
值得注意的是,上述DenseNet网络结构中Transition Layer使用的是平均池化,而不是最大池化。
总结
DenseNet的核心思想在于建立了不同层之间的连接关系,通过这种连接做出了比ResNet更好的网络结构,进一步减轻了梯度消失问题。并且网络很窄,极大的减少了参数量,有助于抑制过拟合的问题。参数量的减少也带来计算量的减少。经常出现在小目标检测的场景中。
-------------------------------------------
算法届的小学生,虔诚而不迷茫,做一个懂生活并有趣的人!
如果觉得这篇文章对你有小小的帮助的话,记得在右下角点个 [推荐] 噢! 欢迎共同交流机器学习,机器视觉,深度学习~
欢迎转载,转载请声明出处!
