【源码解读】YOLO v3 训练 - 02 网络结构
首先,看一下YOLO v3 中的网络结构。
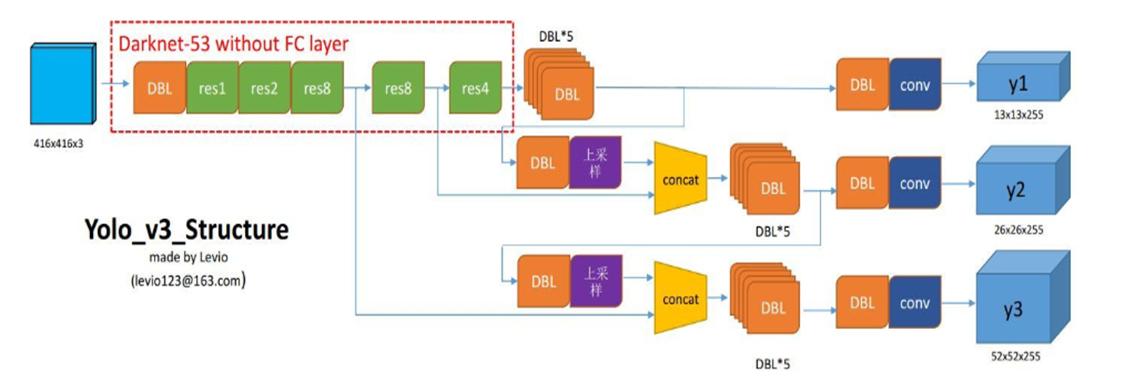
YOLO v3 的整体流程
番外步骤: 对训练集图片标记后产生的数据进行K-Means处理,筛选9个anchor-box。
详见:https://www.cnblogs.com/monologuesmw/p/12761653.html
进入YOLO v3的结构中:
1. 图像缩放。将训练集的图片缩放至416*416中,包括两种缩放的方式:等比缩放和非等比缩放(非等比缩放一般只在训练中)图像缩放至416*416以后,便可以作为YOLO v3 结构的输入。
2. Darknet-53下采样过程,其内部的结构可以看成一个3*3,步长(1*1)(fitters:32)的same卷积 和 若干个(一个3*3,步长(2*2),fitters总是比前面的fitters多一倍的窄卷积 和 fitters减半的1*1卷积、fitters恢复的3*3同卷积 )组成的残差组合块(组合的意思是,一个3*3步长(2*2)其实不是卷积块的内容,但二者有依存关系)。 这样就会将416*416*3 的图像转换为13*13*1024的feature_map。过程中会包含26*26*512的feature_map 和 52*52*256 的feature_map。其内部是这样定义的,步长(1,1)的为同卷积,步长为(2*2)的为窄卷积(使用步长为2的卷积代替pool操作)。
3. 多尺度预测与特征融合上采样,YOLO v3与v2结构上的不同点就在于v3增添了多尺度的预测和特征融合的上采样(不同大小的特征适应于不同大小物体的检测)。并且卷积的结构没有池化层,在卷积层后都会搭载一个Leaky-ReLU的激活函数,并且在激活函数的输入中不使用偏执bias。
在生成13*13*1024后,会再经历两对1*1和3*3卷积,使得三种尺度的feature_map变为13*13*512, 26*26*256。(因为最大尺度的是52*52*256),然后通过上采样的方式,13*13*512变为26*26*512 ,26*26*256变为52*52*256, 这样便可以与高尺度的拼接融合。生成最终的13*13*255、26*26*255 、52*52*255的feature_map输出。
P.S. 上采样的内部机制实际上是最近邻域插值的方式使维度翻倍。
先一睹YOLOv3具体的网络结构:

代码解析
1. Darknet53部分
1 darknet = Model(inputs, darknet_body(inputs)) # 此处返回了第一个下采样13*13 (?,416*416*32)->(?,13*13*1024)
darknet_body(x)内部
1 def darknet_body(x): 2 '''Darknent body having 52 Convolution2D layers 3 有52个卷积层(2D) 4 ''' 5 x = DarknetConv2D_BN_Leaky(32, (3, 3))(x) # (内置same卷积)输出的x-》416*416*32 6 x = resblock_body(x, 64, 1) # num_filters = 64 , num_blocks = 1(重复次数) 返回结果208*208*64 7 x = resblock_body(x, 128, 2) # 返回结果 104*104*128 8 x = resblock_body(x, 256, 8) # 返回结果 52*52*256 9 x = resblock_body(x, 512, 8) # 返回结果 26*26*512 10 x = resblock_body(x, 1024, 4) # 返回结果 13*13*1024 5组重复的resblock_body()单元 11 return x # 第一个下采样特征生成
上述代码是Darknet53的主体部分。
a. 其中,第5行是 一个3*3,步长(1*1)(fitters:32)的same卷积。 其中包含:
- 1个Darknet的2维卷积Conv2D层,即DarknetConv2D();
- 1个批归一化(BN)层,即BatchNormalization();
- 1个LeakyReLU层,斜率是0.1,LeakyReLU是ReLU的变换;
1 def DarknetConv2D_BN_Leaky(*args, **kwargs): 2 """Darknet Convolution2D followed by BatchNormalization and LeakyReLU.""" 3 no_bias_kwargs = {'use_bias': False} 4 no_bias_kwargs.update(kwargs) 5 return compose( 6 DarknetConv2D(*args, **no_bias_kwargs), 7 BatchNormalization(), 8 LeakyReLU(alpha=0.1))
b. 第6-9行,为若干个残差块组。(1+2+8+8=19个重复次数)fitters的通道数会逐渐倍增(深度逐渐加深)。最终返回的x为13*13*1024。
- ZeroPadding2D():填充x的边界为0,由(?, 416, 416, 32)转换为(?, 417, 417, 32)。
因为下一步卷积操作的步长为2,所以图的边长需要是奇数;--- 需要padding
- DarknetConv2D_BN_Leaky()是DarkNet的2维卷积操作,核是(3,3),步长是(2,2),
注意,这会导致特征尺寸变小,由(?, 417, 417, 32)转换为(?, 208, 208, 64)。由于num_filters是64,所以产生64个通道。
- compose():输出预测图y,功能是组合函数,先执行1x1的卷积操作,再执行3x3的卷积操作,filter先降低2倍后恢复,最后与输入相同,都是64; --- 残差块的另一分支
- x = Add()([x, y])是残差(Residual)操作,将x的值与y的值相加。残差操作可以避免,在网络较深时所产生的梯度弥散问题(Vanishing Gradient Problem)。
1 def resblock_body(x, num_filters, num_blocks): 2 '''A series of resblocks starting with a downsampling Convolution2D 3 ''' 4 # Darknet uses left and top padding instead of 'same' mode 5 x = ZeroPadding2D(((1, 0), (1, 0)))(x) # 增加一圈0 x有(?,416,416,32)-> (?,417,417,32) Keras中的方法 6 x = DarknetConv2D_BN_Leaky(num_filters, (3, 3), strides=(2, 2))(x) # 步长上下2,则是窄卷积, 因此上述需padding(才会没有边缘遗失) 7 for i in range(num_blocks): # 此时,x的输出为208*208*64 (重复次数的循环) 8 y = compose( 9 DarknetConv2D_BN_Leaky(num_filters//2, (1, 1)), # 此时的输出为208*208*32 降一半 10 DarknetConv2D_BN_Leaky(num_filters, (3, 3)))(x) # 此时的输出为208 * 208 *64 恢复 11 x = Add()([x, y]) # 将残差块的结果加到源网络的结构上 (不影响运算) 208*208*64 12 return x
2. Darknet输出至y1,y2,y3部分(即13*13*1024至13*13*255. etc)
A. 生成y1 ----> 13*13*255
1 x, y1 = make_last_layers(darknet.output, 512, num_anchors*(num_classes+5))
make_last_layers()的内部
该函数已经是 特征图输出的计算部分,结合结构图来观察,在13*13*1024的地方至13*13*255的y1处的运算:
- 第1步,x执行多组1x1的卷积操作和3x3的卷积操作,filter先缩小再恢复,最后与输入的filter保持不变,仍为512(num_filters),则x由(?, 13, 13, 1024)转变为(?, 13, 13, 512);
- 第2步,x先执行3x3的卷积操作,再执行不含BN和Leaky的1x1的卷积操作,作用类似于全连接操作,生成预测矩阵y;
- 从结构上可以看出,x此时有两个任务,一个是继续y的运算,作为y1特征的输出;另一个是需要上采样到26*26的y2中。,所以分为了x和y两个部分,同时也会返回这两个部分。
1 def make_last_layers(x, num_filters, out_filters): 2 '''6 Conv2D_BN_Leaky layers followed by a Conv2D_linear layer 3 ''' 4 x = compose( 5 DarknetConv2D_BN_Leaky(num_filters, (1, 1)), 6 DarknetConv2D_BN_Leaky(num_filters*2, (3, 3)), 7 DarknetConv2D_BN_Leaky(num_filters, (1, 1)), 8 DarknetConv2D_BN_Leaky(num_filters*2, (3, 3)), 9 DarknetConv2D_BN_Leaky(num_filters, (1, 1)))(x) # 此时13*13*512 10 y = compose( 11 DarknetConv2D_BN_Leaky(num_filters*2, (3, 3)), 12 DarknetConv2D(out_filters, (1,1)))(x) 13 return x, y
B. 生成y2 ---》26*26*255 此部分会涉及到尺度特征融合的部分,即13*13*512的上采样过程。
- 13*13*512--》13*13*256
- 13*13*256 上采样 26*26*256
- 融合后的结果 26*26*768 (原来的是26*26*512,融合后即512+256 = 768)
1 # 第二部分 26*26*256 的y2 2 x = compose( 3 DarknetConv2D_BN_Leaky(256, (1,1)), # 此时x的为13*13*256 4 UpSampling2D(2))(x) # x需要参加的上采样 此时的x为26*26*256 5 x = Concatenate()([x, darknet.layers[152].output]) # 把之前结果的第152层的输出提取,即26*26*512的输出 即13*13*1024的前一层输出 6 x, y2 = make_last_layers(x, 256, num_anchors*(num_classes+5))
C. 生成y3 ----》52*52*255 此部分包含26*26*256的上采样过程
- 26*26*256 --》 26*26*128
- 26*26*128上采样到52*52*128
- 融合后的结果52*52*384 (128+256=384)
1 # 第三部分 52*52*128*18(18=3*(1+5)1个类别,3个锚框) 的y3 2 x = compose( 3 DarknetConv2D_BN_Leaky(128, (1,1)), 4 UpSampling2D(2))(x) # 同样需要26的x 的上采样 5 x = Concatenate()([x,darknet.layers[92].output]) 6 x, y3 = make_last_layers(x, 128, num_anchors*(num_classes+5))
当然,此时返回的这个x就没有什么任务了。
模型结构创建完毕。
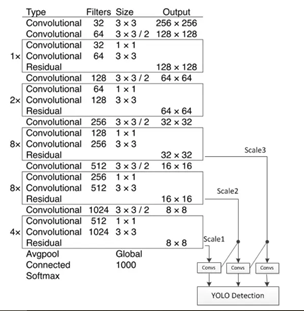
可以看出,Darknet的框架是由多组Conv+Conv+Residual的结构叠加而成的。
即1+1+1*2+1+2*2+1+8*2+1+8*2+1+4*2 = 52
配置文件中 ############# 的分割 就是结构中darknet的结束。
-------------------------------------------
算法届的小学生,虔诚而不迷茫,做一个懂生活并有趣的人!
如果觉得这篇文章对你有小小的帮助的话,记得在右下角点个 [推荐] 噢! 欢迎共同交流机器学习,机器视觉,深度学习~
欢迎转载,转载请声明出处!
