论文阅记 M2Det: A Single-Shot Object Detector based on Multi-Level Feature Pyramid
论文题目:M2Det: A Single-Shot Object Detector based on Multi-Level Feature Pyramid
文献地址:https://arxiv.org/abs/1811.04533v3
源码地址:https://github.com/qijiezhao/M2Det
目前先进的目标检测算法是通过FPN(特征金字塔)的方式解决目标在检测的过程中规模(大小)变化的问题。
- one-stage
- DSSD
- RetinaNet
- RefineDet
- YOLO v3
- two-stage
- Mask-RCNN (其论文中尝试了不同的head,其中包括FPN)
作者认为,FPN只是利用原始设计的网络骨架简单的融合了一些特征构建了金字塔模型。(金字塔层数太少,融合的特征也太少)
因此,在FPN的基础上,提出了MLFPN(Multi-level Feature Pyramid)模型。(即多级特征金字塔模型)将MLFPN模型集成到SSD模型上,构建了一个one-stage模型M2Det。
- 融合了多级的特征(多层的),从网络主干中提取出来的基础特征;
- 将基本特征输入到交错连接的U型模型和特征融合模型中,U型模块的解码器层作为检测的特征。
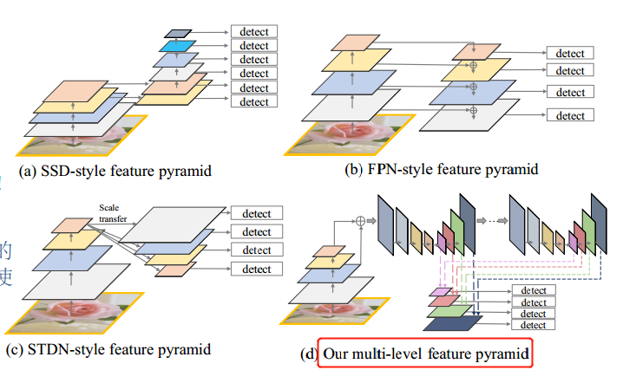
尺度变化现状
尺度变化问题是目标检测中的一大挑战。目前主要由两种策略去解决这一问题:
- 图像金字塔(image pyramid),也就是说输入图像是一系列不同尺度的图像;
a) 只有测试的时候可以被利用
b) 极大的增加内存和运算复杂度,效率低,实时性差
2. 特征金字塔(feature pyramid)
a) 可以在训练、测试的时候利用
b) 相较于图像金字塔,特征金字塔占用更少的内存,更少的运算量。
c) 很容易被继承到深度神经网络的架构中。
FPN的局限性:
- FPN中不同尺度所选的特征不具备代表性。因为它们只是由设计用于对象分类任务的主干的层(特性)构造而成。
也就是说,对于一张图像上相同大小的物体,有的本身就这么大,而有的是因为物体本身相对遥远。例如,红绿灯和遥远的行人。因此,FPN在给定深度的网络上,提取特征不同不同外观的物体效果可能会有所不同。
2. FPN中,每个特征只是由网络主干中的一层信息构成。
a) 更深层的特征一般会更具有识别力,对于目标分类的子任务。
b) 浅层的特征对于目标位置回归的子任务更有帮助。
c) 浅层特征适合描述简单外观的目标
d) 深层特征更适合描述复杂外观的描述
c,d是深层神经网络为什么有效的另一个角度的描述,对于识别物体中的简单外观的目标,应该通过浅层的特征识别,而复杂外观的目标,就应该运用深层的特征识别。
在实际中,具有相同大小实例的外观的复杂度可能完全不同,例如红绿灯和远处的行人,可能具有同样的尺寸,但人的外观就要复杂的多。
综上所述,金子塔中的特征主要或者仅由一层特征构成,效果不佳。
实现思路
该论文的目标就是在避免上述的弊端的同时,更好的进行特征融合。
- 从backbone中提取特征进行多级的特征融合作为标准特征(base feature);
- 将特征喂到MLFPN块中,包括TUM、FFM,SFAM进行更具有代表性的多级,多尺度的特征。
P.S.:
i. Thinned U-shape Modules(TUM) --U型微型模块
ii. Feature Fusion Modules(FFM) -- 特征融合模块
iii. Scale-wise Feature Aggregation Modules(SFAM) -- 多尺度特征融合
3.解码层(decorder layer) 形成的最终特征金字塔要比backbone层还要深。

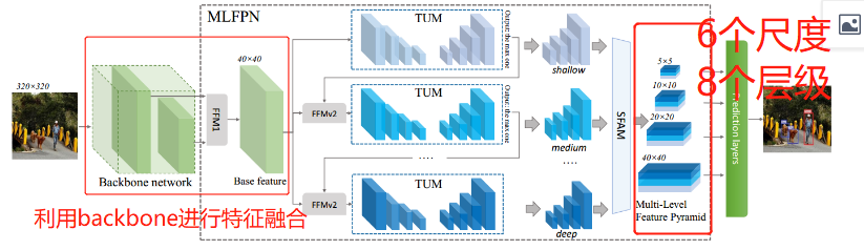
FFMv1,通过融合主干(backbone)特征映射,将语义信息丰富成基本特征(base feature)。
TUM, 每一个TUM会生成一组多尺度特征,然后利用多级交流节点TUMs和FFMv2s提取多级多尺度特征。
SFAM,将提取的多级、多尺度特征集成到多级金字塔中,通过尺度级联的特征操作和自适应的注意机制。
实现细节
FFMv1融合浅层和深层特征,并产生基础特征(base feature)。backbone network 可以选择VGG。
每一个TUM都会通过不同的尺度,生成一些特征图。
FFMv2融合基础特征和之前TUM输出的大的输出特征图。融合后的特征将会传输给下一个TUM (有些像残差网络)。
值得注意的是,第一个TUM并没有先验知识,只有通过基础特征学习到的知识(learns from Xbase)。
综上,多层、多尺度的输出的计算方式:
![]()
其中,F表示FFMv2操作,Tl表示第l-th个TUM的操作。
FFM:特征融合模块
FFMs会融合不同层级的特征,是构建多层特征金字塔的关键。使用1*1 的卷积层压缩通道,并使用一些列节点的操作集成这些特征。
- FFMv1使用了backbone中两种尺度的特征,采用上采样的方式缩放深层特征,在连接之前。
- FFMv2 base feature map + previous TUM output 是相同尺寸的。
两种类型的FFM的结构细节如下图所示。其中,左图为FFMv1, 右图为FFMv2。

- 在FFM v1和v2中都会使用1*1卷积降低输入feature map的通道数量。 如上图(a)中,FFMv1将1024的通道数量压缩到512的通道数量、将512的通道数量压缩到256的通道数量,融合生成(512+256 = 768)的通道数量;
- 在FFM v2中,由于输入feature map 的宽高是相同的,只需要将768的通道数量压缩到128,然后与另一个128的通道数量进行融合,生成256的通道数量;
- 这里使用的卷积是包含BN,ReLU的卷积层, 融合采用双线性插值(Blinear Upsample)
TUM
TUM结构细节如下图所示:
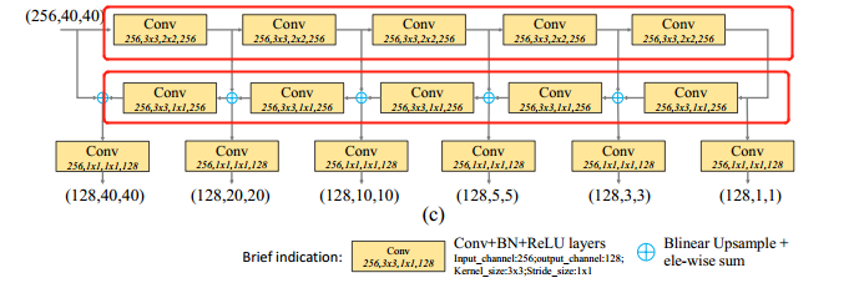
由8个TUM构成8个层级,每个TUM有6个尺度的输出,构成6个尺度。 共8个层级 6个尺度
上述结构分为编码层和解码层;【史上最花哨的模型,没有之一】
上采样(Blinear Upsample)采用对应元素相加的方式保证特征的平滑度。【并不会有维度度增大的问题】
SFAM:尺度融合模块
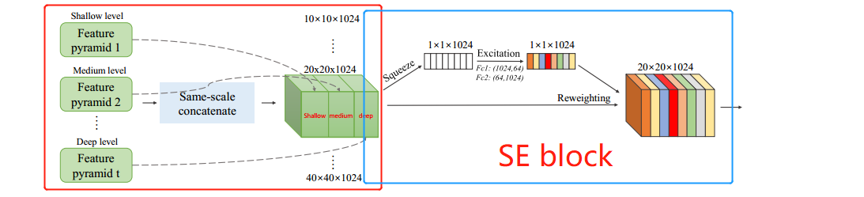
对不同层级、不同尺度的特征进行融合。简单来说,就是将8个层级中相同大小尺度的输出融合在一起,形成6个特征块。(128 * 8 =1024, 有8个层级)
SFAM中主要包含两个部分:
- 将8个层级中相同尺度的特征进行拼接,形成6个 ?*?*1024 的特征;
- SE block --- excitation 操作, 激发激励; 学习对各通道的依赖程度,也就是获取各通道的权重信息;
P.S.
Squeeze-and-Excitation Networks (SE Net)
卷积层的输出并没有考虑对各通道的依赖性,本文的目标就是让网络有选择性的增强信息量大的特征,使得后续处理可以充分利用这些特征,并对无用特征进行抑制。
使用全局平均池化生成各通道的统计量
实验对比
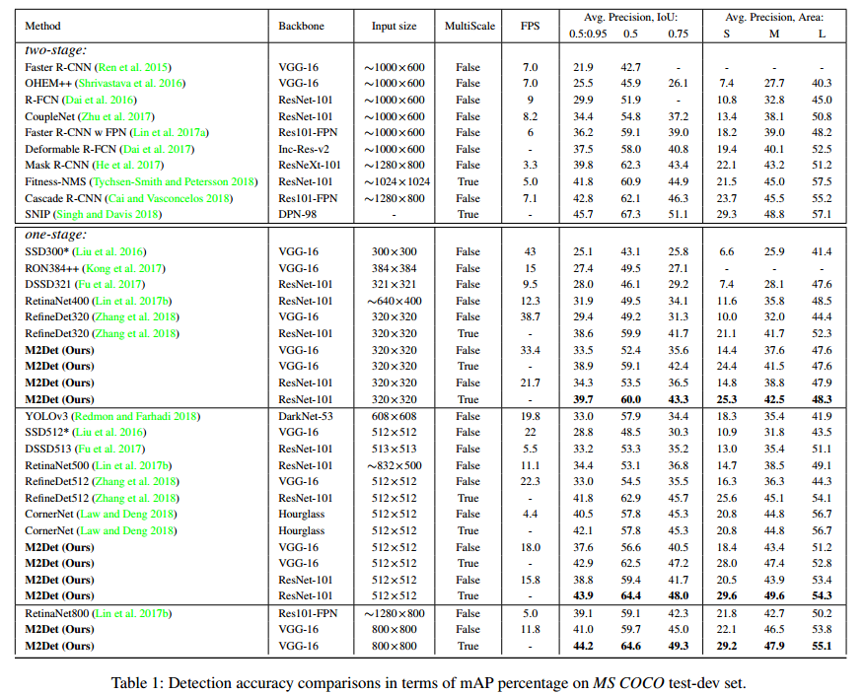
不同参数对于算法性能的影响,主要包括2个参数:
- TUM的个数 --- 也就是层级的个数 (前文介绍的是8个层级)
- Channels
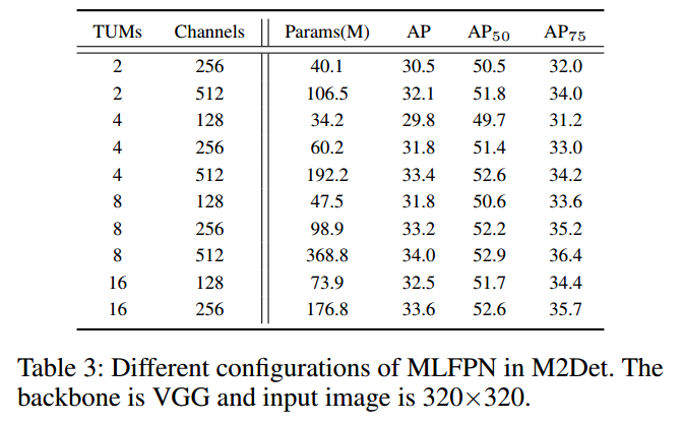
MLFPN可以适用于多种backbone,上述对比是VGG做backbone。
mAP与推理(测试)时间对比
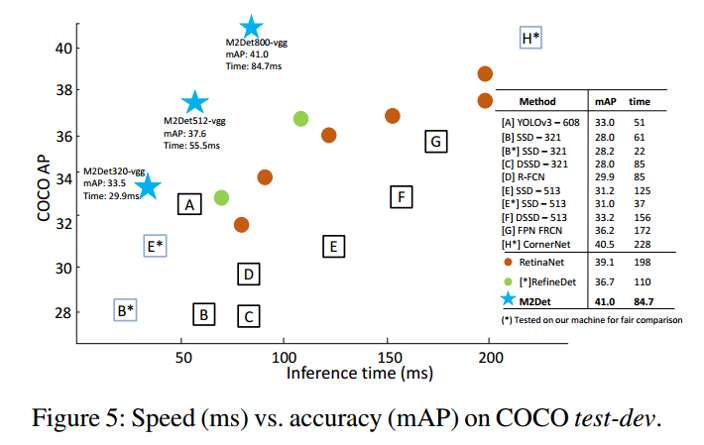
-------------------------------------------
算法届的小学生,虔诚而不迷茫,做一个懂生活并有趣的人!
如果觉得这篇文章对你有小小的帮助的话,记得在右下角点个 [推荐] 噢! 欢迎共同交流机器学习,机器视觉,深度学习~
欢迎转载,转载请声明出处!
 浙公网安备 33010602011771号
浙公网安备 33010602011771号