论文阅记 Segmentation-Based Deep-Learning Approach for Surface-Defect
论文题目: Segmentation-Based Deep-Learning Approach for Surface-Defect
文献地址:https://arxiv.org/abs/1903.08536v3
源码地址:https://github.com/Wslsdx/Deep-Learning-Approach-for-Surface-Defect-Detection
最近接到表面缺陷检测的需求,在Github上查找Defect Detection开源代码时,“最先进的缺陷检测网络”赫然屹立于Github搜索结果的首位,还附带该代码对应的论文的题目,便前来膜拜。
Segmentation-Based Deep-Learning Approach for Surface-Defect(2019.06)
这篇论文主要是利用分割模型和分类模型进行表面瑕疵的检测,主要优势为:只需要25-30个有缺陷的样本就可完成分类,所用样本极少。
从目标检测、目标追踪最先进的文献来看,效果最好的模型都是建立在分割(segmentation)的基础上,像目标检测中的Mask R-CNN、单目标追踪中的Siam Mask,均包含Mask的分支。正如Siam Mask一作王强所述:
更为本质的,我们会发现,这个旋转的矩形框实际上就是 mask 的一种近似。我们所要预测的实际上就是目标物体的 mask。
利用 mask 才能得到精度本身的上界。
这篇关于表面缺陷检测的论文也是建立在分割的基础上,概括的来说,这篇论文提出的模型结构包含分割模型与分类模型,在两个模型融合的基础上进行物体表面的缺陷检测。与传统深度学习不一样的地方体现在,其可以通过较少的训练样本实现模型的训练,并获得很高的精度。这一设计使得模型可以更好的应用于工业领域。毕竟缺陷样本数据的采集在工业场景中是一大难题,就像故障检测中故障样本集很少一样。
表面缺陷检测的现状
工业生产过程中, 检查产品的表面是保证本身质量的关键。表面质量的监控往往通过人工的,通过训练的工人辨别复杂的表面缺陷, 这种控制方式是耗时、低效的。(就像最早日本丰田的生产线,每一个技工负责某一块产品的生产检测...) 工业4.0的发展,使得工业加工生产更趋向于生产线模式。
深度学习应用于缺陷检测还有一个公开问题就是需要大量的数据去训练具有百万级参数的模型,大数据量的要求在机器视觉领域带来的是数据标注的人工成本。
深度学习算法实际应用需要考虑三个方面的问题:
- 训练数据数量的需求
- 标注的需求
- 计算能力的需求
论文贡献
这篇文章提出了一个two-stage的模型,具有精度高、所需标注样本少、计算量小的特性。并且其提供了表面缺陷的开源数据集KolektorSDD。 399个图像【50种电子换向器】,52个有缺陷的样本,347个无缺陷样本。 分辨率1408*512。
其标注具有不同的类别,作者尝试了不同大小的标注方式,认为不同的标注方式对于模型的训练会有影响。
http://www.vicos.si/Downloads/KolektorSDD

实现细节
模型结构包含两个部分,其一为像素级的分割Segmentation network(下图左侧),用于生成分割掩码,确定缺陷的具体位置;其二为Decision network(下图右侧),用于生成二值分类输出,判断当前物体表面是否有缺陷。作者认为,在表面质量控制方面,是否有缺陷的决策比缺陷定位更重要。
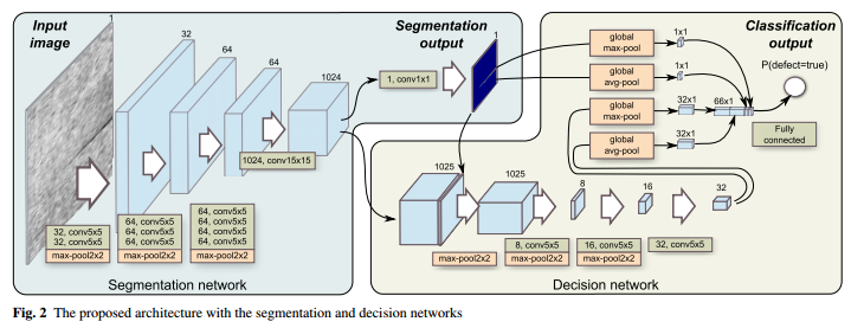
1. Segmentation network (左侧)
第一阶段:分割网络,对表面的缺陷进行像素级的定位,在高分辨率的图像中检查表面小缺陷。
这部分包含11个卷积层,3个最大池化层:
- 9个5*5卷积层;
- 1个15*15卷积层; --- 卷积层后面包含一个特征标准化层(BN)和ReLU层,增加收敛性
- 1个1*1卷积层; --- 源码中1*1卷积没有使用ReLU激活函数,使用的是sigmoid激活函数,用于生成二值掩码。
- 3个最大池化层 --- 用于降采样, 其步长为2。
卷积层使用的都是同卷积,即卷积层不进行降采样的操作,仅通过池化层进行降采样的操作。通道数量分别为32/64/64/1024/1, 最终生成的是一个单通道,8倍缩小于原图的segmentation output。
没有使用Dropout。
由于分割网络专注于在高分辨率的图像表面上查找小的缺陷,因此,网络需要满足两个需求:
- 具有较大的感受野;
- 能够捕捉到较小的特征细节。
以上两个需求就需要在网络设计上,具有下采样层,在比较深的层中使用尺寸大的卷积核。
☆☆☆使用最大池化层代替具有步长的卷积层,能够保证小但重要的细节在降采样的过程中幸存。
比较yolov3 和yolo v3-tiny版,在yolo v3-tiny的结构中,由于其层数较少,使用最大池化层,代替yolov3中具有步长的卷积层。
模型不需要在别的数据集上进行预训练,权重只需要使用服从正态分布随机初始化即可。
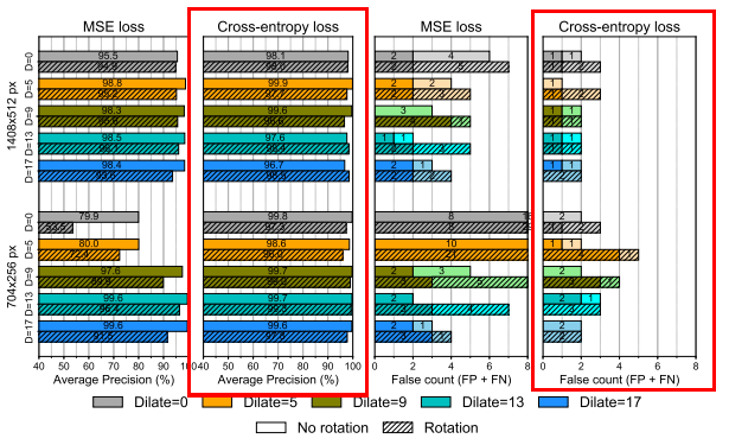
模型选择了MSE和交叉熵两种损失函数对模型进行评估,结果表明使用交叉熵损失作为该网络的损失函数最好。如下图所示。
segmentation network 实现
1 def build_model(self): # build_model()中包含两部分: 第一部分,分割网络; 第二部分:决策网络, 使用了嵌套函数的方式 2 def SegmentNet(input, scope, is_training, reuse=None): 3 with tf.variable_scope(scope, reuse=reuse): # 一个scope下的 4 with slim.arg_scope([slim.conv2d], 5 padding='SAME', 6 activation_fn=tf.nn.relu, 7 normalizer_fn=slim.batch_norm): # 为目标函数conv2d设置默认参数 8 net = slim.conv2d(input, 32, [5, 5], scope='conv1') 9 net = slim.conv2d(net, 32, [5, 5], scope='conv2') 10 net=slim.max_pool2d(net,[2,2],[2,2], scope='pool1') # [2,2]表示上下都是2的步长 11 12 net = slim.conv2d(net, 64, [5, 5],scope='conv3') 13 net = slim.conv2d(net, 64, [5, 5], scope='conv4') 14 net = slim.conv2d(net, 64, [5, 5], scope='conv5') 15 net=slim.max_pool2d(net, [2, 2], [2, 2], scope='pool2') 16 17 net = slim.conv2d(net, 64, [5, 5],scope='conv6') 18 net = slim.conv2d(net, 64, [5, 5], scope='conv7') 19 net = slim.conv2d(net, 64, [5, 5],scope='conv8') 20 net = slim.conv2d(net, 64, [5, 5], scope='conv9') 21 net=slim.max_pool2d(net,[2,2],[2,2],scope='pool3') 22 23 net = slim.conv2d(net, 1024, [15, 15], scope='conv10') # 1024的特征需要输出 24 features=net # 所以这里将其赋值给features的变量中,用于输出 25 net = slim.conv2d(net, 1, [1, 1],activation_fn=None, scope='conv11') 26 logits_pixel=net 27 net=tf.sigmoid(net, name=None) # 生成mask 经过了一层sigmoid激活函数 28 mask=net 29 return features,logits_pixel,mask
2. Decision network (右侧)
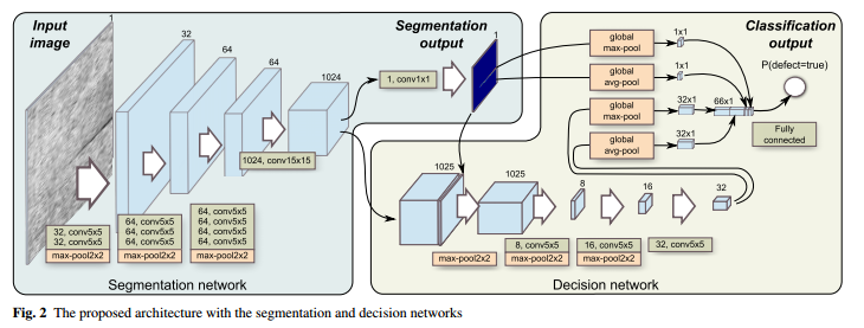
第二阶段: 决策网络,对二值图像进行分类
1. 附加网络,使用的是分割网络的输出和分割网络的特征,即上图中,通道数量包含1024+1 = 1025层。其结构包括:
3个5*5卷积层; 通道数量为 8 、 16、 32 。[1025-8-16-32]
3个最大池化层; --- 降采样 【步长为2】
这样,输出将会16倍缩小于原图。
2. 附加网络之后,包含一个全局池化层,分别对segmentation output 和 附加网络输出 进行全局最大和全局平均池化。最终将会组合生成 32+32+1+1 = 66 通道数量的输出。(由于是做的全局池化,所以每一个输出都是一个值,即消除了segmentation output 和附加网络输出维度不匹配的问题)
最后,通过一个全连接层,生成最终分类的输出。 [0, 1]表示缺陷出现的可能性。
分类问题,所以选择交叉熵损失函数。
Decision Network 实现
1 def DecisionNet(feature,mask, scope, is_training,num_classes=2, reuse=None): 2 with tf.variable_scope(scope, reuse=reuse): 3 with slim.arg_scope([slim.conv2d], 4 padding='SAME', 5 activation_fn=tf.nn.relu, 6 normalizer_fn=slim.batch_norm): 7 # 附加网络 8 net=tf.concat([feature,mask],axis=3) # 1024的特征是和mask进行合并 9 net = slim.max_pool2d(net, [2, 2], [2, 2], scope='pool1') 10 11 net = slim.conv2d(net, 8, [5, 5], scope='conv1') 12 net = slim.max_pool2d(net, [2, 2], [2, 2], scope='pool2') 13 14 net = slim.conv2d(net, 16, [5, 5], scope='conv2') 15 net = slim.max_pool2d(net, [2, 2], [2, 2], scope='pool3') 16 17 net = slim.conv2d(net, 32, [5, 5], scope='conv3') 18 19 vector1=math_ops.reduce_mean(net, [1,2], name='pool4', keepdims=True) # 全局平均 20 vector2=math_ops.reduce_max(net, [1,2], name='pool5', keepdims=True) # 全局最大 21 22 # segmentation network 输出的处理 23 vector3=math_ops.reduce_mean(mask, [1, 2], name='pool6', keepdims=True) 24 25 vector4=math_ops.reduce_max(mask, [1, 2], name='pool7', keepdims=True) # 全局池化操作就是reduce_max_mean 26 # 拼接 27 vector=tf.concat([vector1, vector2, vector3, vector4], axis=3) # 将全局内容合并 28 29 vector=tf.squeeze(vector, axis=[1, 2]) # # 删除张量shape中维度为1的, 可以指定维度 30 31 logits = slim.fully_connected(vector, num_classes,activation_fn=None) 32 output=tf.argmax(logits, axis=1) # 找logits中最大的那个变量 33 return logits,output
两个网络损失函数的处理:
1 loss_pixel = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=logits_pixel, labels=PixelLabel_reshape)) 2 loss_class = tf.reduce_mean(tf.nn.sparse_softmax_cross_entropy_with_logits(logits=logits_class,labels=Label)) 3 loss_total=loss_pixel+loss_class # 会把两个的损失叠加起来进行计算
训练过程:
训练两步走:
1. 单独训练分割网络
2. 分割网络权重冻结,训练决策网络
再进行微调,避免分割网络过拟合。
训练两步走,微调的实现:
1 optimizer = tf.train.GradientDescentOptimizer(self.__learn_rate)
2 train_var_list = [v for v in tf.trainable_variables()] 3 train_segment_var_list = [v for v in tf.trainable_variables() if 'segment' in v.name ] 4 train_decision_var_list = [v for v in tf.trainable_variables() if 'decision' in v.name]
5 optimize_segment = optimizer.minimize(loss_pixel,var_list=train_segment_var_list) # segment训练时使用 6 optimize_decision = optimizer.minimize(loss_class, var_list=train_decision_var_list) # decision训练时使用 7 optimize_total = optimizer.minimize(loss_total, var_list=train_var_list) # 最终一起训练时使用
决策层进行学习时,仅使用一个或两个样本每个batch。【限于GPU的内存】
分割层学习时,可以让batch size增加几倍,由于每个像素都是一个训练样本。
输入图像为灰度图像
作者并没有将8倍小于原图的segmentation利用插值的方式还原到原图的大小。作者认为8倍小于原图的尺寸已经够后续网络使用。 可能还是觉得模型的输出最主要的是分类,而分割的输出没有那么重要。 ---- 有没有缺陷 要比在哪更重要
实验的尝试:

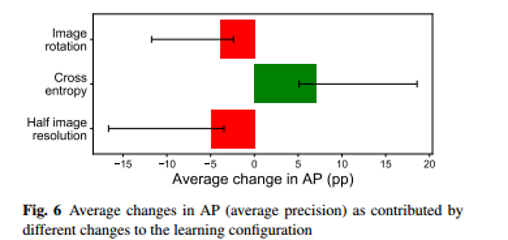
作者对标注类型的影响、损失函数的选择(分割网络)、输入分辨率的大小、是否对输入图像进行旋转 这四个方面对模型精度的影响进行探讨。从下图的结果中可以看出,分割网络使用交叉熵损失函数,模型的精度要明显优于MSE损失函数。
最佳的结果:
- dilate=5的标注方式 大注释要好一些
- cross-entropy loss function
- full image resolution (即使用1408*512的分辨率的图像)
- 没有任何旋转 No rotation

-------------------------------------------
算法届的小学生,虔诚而不迷茫,做一个懂生活并有趣的人!
如果觉得这篇文章对你有小小的帮助的话,记得在右下角点个 [推荐] 噢! 欢迎共同交流机器学习,机器视觉,深度学习~
欢迎转载,转载请声明出处!
 浙公网安备 33010602011771号
浙公网安备 33010602011771号