机器学习(二)之决策树(ID3)
Contents
- 理论基础
- 熵
- 信息增益
- 算法实现 Python
- 模型的保存与读取
- 总结
理论基础
决策树(Decision Tree, DT):决策树是一种基本的分类与回归方法。由于模型呈树形结构,可以看做是if-then规则的集合,具有一定的可读性,可视化效果好。
决策树的建立包括3个步骤:特征选择、决策树生成和决策树的修剪。
模型的建立实际上就是通过某种方式,递归地选择最优的特征,并通过数据的划分,将无序的数据变得有序。(对于分类而言,希望的是将一些多类别的数据划分到各自的类别中,实现从数据的混杂到条理,这也就是无序到有序的概念)
如下图所示,PLAN1和PLAN2描述了通过两个不同的特征,数据从无序变到有序的情况。从划分结果可以看出,特征1相对于特征2要更优一些,划分结果数据的有序程度更高。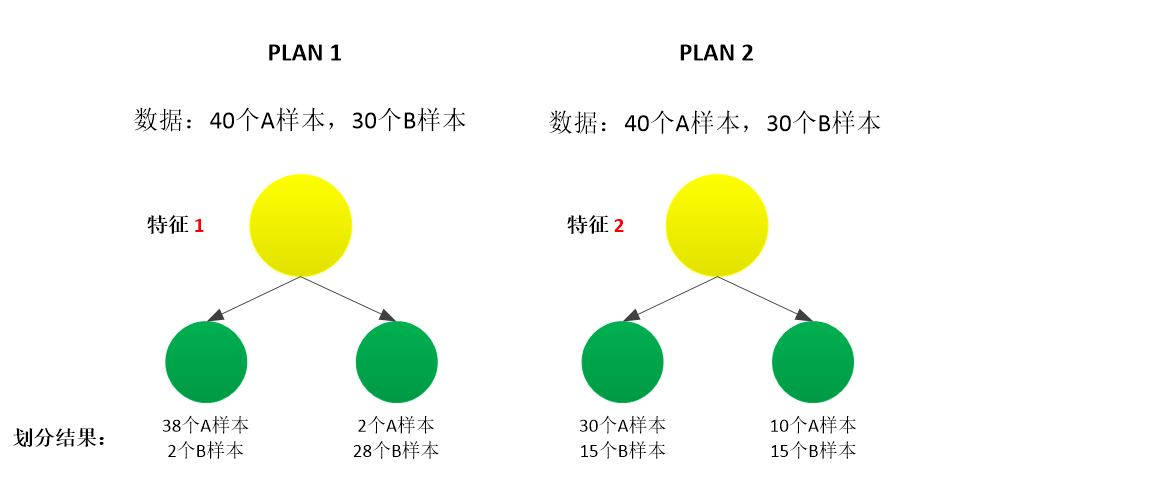
因此,在构造决策树时,第一个需要解决的问题就是如何确定出哪个特征划分数据是起决定性作用的,或者说先使用哪个特征进行划分能够使数据的不确定性减少的更多,从而使数据变得更有序,分类效果更好,也就是接下来要介绍的熵和信息增益的概念(Id3)。当找到最优的特征后,数据集依据此特征划分为几个数据子集,这些数据会分布在该决策点的所有分支中。此时,如果某个分支下的数据属于同一类型,则该分支下的数据分类已经完成,无需进行下一步的数据集分类;如果分支下的数据属于不同类型,就需要继续对数据集进行划分,按照与划分原始数据集相同的原则,再次确定出该数据子集中的最优特征,对数据进行分类,直到所有的特征已经遍历完成,或者所有叶结点分支下的数据具有相同的分类。
上述描述了两种决策树停止的方式:
- 当某分支下的数据属于同一类型时;
- 当分支下所有的特征都已遍历完。
决策树的各种算法思想是一致的,都是要让数据从无序变为有序,只是不同算法选择特征的方式不同,本篇Id3算法是基于熵和信息增益的方式选择特征,在下一篇的CART算法,采用基尼系数的方式。
在介绍Id3的具体理论之前,先来看一看决策树的基本结构(其结构与二叉树有相似之处):
- 左图中,圆圈为属性(特征),也是内部节点,在结构化数据中就是数据的列名;矩形为类,也被称为叶节点,也就是数据的标签。
- 右图中,为一个简易的相亲决策的实例,对应的绿色部分为属性,包括年龄、长相、收入、是否为公务员等。箭头上的为划分的依据,对于离散数据,依据离散的属性进行划分即可,例如帅或中等,丑;对于连续数据,可以以某一范围进行划分,例如小于等于30岁和大于30岁。橙色部分为叶节点,即决策目标:见或不见。
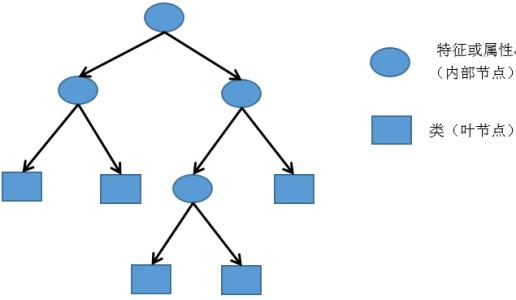
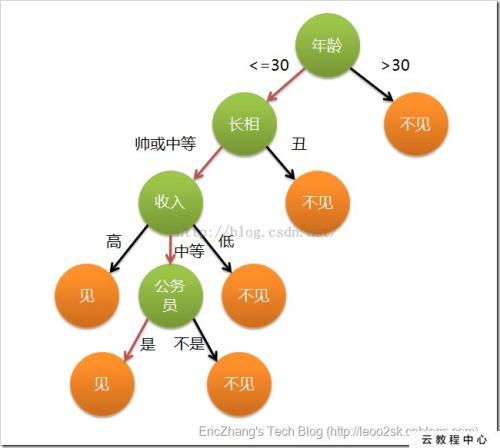
从上图可以看出,决策树具有良好的可读性。
熵
熵:即对随机变量不确定性程度的度量。熵越小,随机变量的不确定性越小,即节点的“纯度”越大。 纯度越大可以理解为节点中所包含的样本数据尽可能的属于同一类别(很纯),也就是pi趋向于0或1。从下图中也可以看出,当概率值偏向于0或1时,熵最小,即不确定性越小。 ---- 熵值越小,纯度越高!
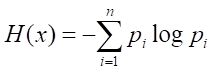
从上式可以看出,当随机变量只包含两类时,即
![]()
注:上式有一个约定,即当p=0时,plog p = 0;
此时,熵的分布如下图所示: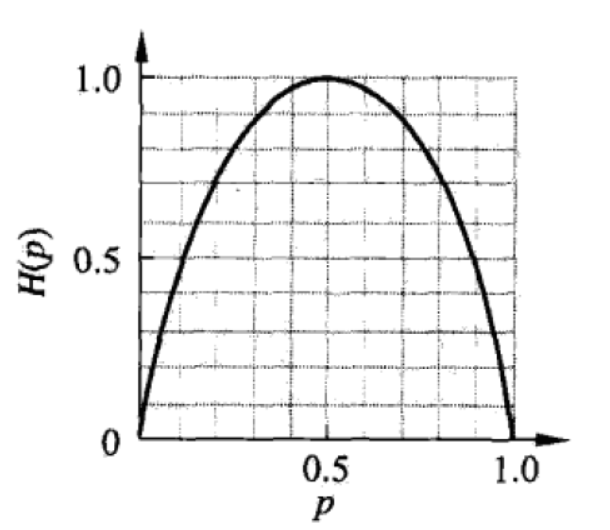 当p=0.5时,也就是随机变量的两个值发生是等概率的,此时事件发生的不确定性最大,熵也最大; 当p=0或p=1时,此时为确定事件,不存在不确定性,熵为0。从开篇的两种PLAN的划分结果也可以看出,PLAN2的每个概率都更接近于0.5,其数据的可分程度更低,不确定性更高。 再换一句话说,也就是通过某个特征对数据进行分类,并没有起到什么作用,还是随机猜的情形。
当p=0.5时,也就是随机变量的两个值发生是等概率的,此时事件发生的不确定性最大,熵也最大; 当p=0或p=1时,此时为确定事件,不存在不确定性,熵为0。从开篇的两种PLAN的划分结果也可以看出,PLAN2的每个概率都更接近于0.5,其数据的可分程度更低,不确定性更高。 再换一句话说,也就是通过某个特征对数据进行分类,并没有起到什么作用,还是随机猜的情形。
以表3-1中的数据为例,在选择特征是否有脚蹼时,5条数据中,有2条数据表示是鱼类,3条数据表示不是鱼类,则其熵为 -2/5 log 2/5 - (1-2/5) log (1-2/5)。
在选择了某一属性后,此时的熵即为在该属性确定以后的条件熵:![]() 。条件熵是用于衡量当随机变量Y确定了以后,随机变量X的不确定性。
。条件熵是用于衡量当随机变量Y确定了以后,随机变量X的不确定性。
信息增益
信息增益:表示得知随机变量Y(属性)的信息而使得X的信息不确定性减少的程度。也就是说,信息增益越大,纯度提升越大。
通过对熵和条件熵概念的理解,信息增益(也称为互信息)可以表示为:
![]()
为了便于理解上式可以写成:
![]()
其中,v表示特征包含几种可能的取值,即该特征下分支的个数。对不同分支下的数据计算熵,并赋予权重。熵的计算和权重的赋值,均是在当前取值的数据条件下。
例如,表3-1中的数据,在特征是否有脚蹼下,包含两种可能的取值,即是、否:
- 当Dv为 是 时,其共包含4个样本,其中属于鱼类的有两个样本,不属于鱼类的有两个样本,则上式的右半部分可以表示为 4/5 * [- (2/4 * log(2/4) + 2/4 * log(2/4) )]
- 当Dv为 否 时,其共包含1个样本,属于鱼类零个样本,不属于鱼类一个样本,则上式右半部分可以表示为 1/5 * [- (1/1 * log 1/1 + 0/1 * log0/1)]
可以看出,Dv(节点)的数据越多,节点影响越大。
决策树就是通过信息增益的方式选择特征(不同的特征具有不同的信息增益),选择方式是选择信息增益最大,也就是选择能够使数据的不确定性减少最多的特征。
通过上述的介绍,决策树的训练数据集用于求各随机变量的概率pi。
- 熵描述的是事物的不确定性;
- 信息增益描述的是不确定性降低了多少。
决策树的特点:
- 优点:计算复杂度不高,输出结果易于理解,对中间值的缺失不敏感,可以处理不相关特征数据。
- 缺点:可能会产生过度匹配的问题
- 适用数据类型:数值型和标称型
算法实现
算法的实现需要通过以下步骤来实现:
1. 计算给定数据的熵
2. 划分数据集
3. 选择信息增益最大的特征
4. 定义叶子节点
5. 生成决策树
具体实例如下:

1. 将上述表格量化,生成数据
1 import math, operator 2 3 def createDataSet(): 4 ''' 5 生成一个简单的数据集 6 :return: 数据 标签 7 ''' 8 dataSet = [[1,1,'yes'], 9 [1,1,'yes'], 10 [1,0,'no'], 11 [0,1,'no'], 12 [0,1,'no']] 13 labels = ['no surfacing', 'flippers'] 14 return dataSet, labels
2. 计算给定数据的熵(具体操作见函数注释)
此处计算的只是数据的熵,dataSet是经过步骤3,根据特征划分好的数据【已经是特征下的数据,即38个A,两个B这种】。因此,此处需要做的事情:
- 统计当前数据中每个标签出现的次数
- 根据出现的次数,计算各标签出现的概率,然后进行熵的计算
1 def calcshannonEnt(dataSet): 2 ''' 3 计算数据的熵H(x) 4 根据熵的计算公式,需要计算出每一类(标签)在当前数据中出现的次数(用于计算概率) 5 因此: 6 1. 统计给定数据中,各类(标签)出现的次数 7 2. 根据各类出现的次数,计算熵H(x) 8 :param dataSet: 给定数据 9 :return: 数据的熵 一个确切的值 10 ''' 11 numEntries = len(dataSet) # 有几条数据 12 13 # 统计给定的数据中各个标签出现的次数 用于计算概率 14 labelCounts = {} # 用来记录已经选择过得特征 15 for featVec in dataSet: # 每一条数据 16 currentLabel = featVec[-1] # 每条数据的标签 17 if currentLabel not in labelCounts.keys(): # 当前标签是否没有出现, 通过字典的键来实现 18 labelCounts[currentLabel] = 0 # 没有出现过, 字典先增 并初始化为0 19 labelCounts[currentLabel] += 1 # 不管出现过,还是没有出现过, 都需要在字典的值中+1 进行出现次数的统计 【所以上一行代码中将新出现的标签的出现次数置为0】 20 shannonEnt = 0.0 21 # 熵的计算 22 for key in labelCounts: 23 prob = float(labelCounts[key])/numEntries # 计算概率 24 shannonEnt -= prob * math.log(prob, 2) # 计算熵 数据的熵 需要所有类别都进行求和 衡量数据的复杂程度 25 return shannonEnt
3. 对每个特征划分数据
对数据进行按特征进行划分,需要遍历特征,将特征传入(列号axis,例如是否有脚蹼,传入1),并对当前特征下的不同属性进行遍历(属性值value,例如是否有脚蹼下的否,传入0)。然后,便可以将数据中满足没有脚蹼的数据划分为一类,划分完的数据将会去除是否有脚蹼这一属性。在下述代码中,会看到通过extend 和 append的操作,将当前属性的数据去除。
1 def splitDataSet(dataSet, axis, value): 2 ''' 3 对一个特征的一个属性进行划分,在数据中去除数据中当前特征符合当前属性值的数据, 生成不包含当前特征对应的属性的值 的数据 4 根据 axis 的设定值value进行数据划分,也就是说,axis是输入的是特征的序号, 而value是该特征对应的类型,意在寻找符合该特征类型的数据 5 而最终需要的返回的是 符合该特征类型, 并除去该特征的数据 (因为该特征已经作为了父节点) 6 :param dataSet: 待划分数据集 7 :param axis: 数据的第几个特征 8 :param value: axis特征对应的值 9 :return: 符合该特征的其余特征 标签数据 10 ''' 11 retDataSet = [] 12 for featVec in dataSet: 13 if featVec[axis] == value: 14 reducedFeatVec = featVec[:axis] 15 reducedFeatVec.extend(featVec[axis+1:]) # 两头拼 extend拼接不新增维度 16 retDataSet.append(reducedFeatVec) # 整体拼 append拼接新增维度 17 return retDataSet
需要说明的是:
(1)在划分数据集函数中,传递的参数dataSet列表的引用,在函数内部对该列表对象进行修改,会导致列表内容发生改变,于是,为了消除该影响,我们应该在函数中创建一个新的列表对象,将对列表对象操作后的数据集存入新的列表对象中
(2)需要区分一下append()函数和extend()函数
这两种方法的功能类似,都是在列表末尾添加新元素,但是在处理多个列表时,处理结果有所不同:
比如:a=[1,2,3],b=[4,5,6]
那么a.append(b)的结果为:[1,2,3,[4,5,6]],即使用append()函数会在列表末尾添加人新的列表对象b
而a.extend(b)的结果为:[1,2,3,4,5,6]
4. 选择信息增益最大的特征
1 def chooseBestFeatureToSplit(dataSet): 2 ''' 3 选择当前最适合做分类的特征 4 1. 计算数据集的熵 H(x) 5 2. 按照特征循环(数据去掉标签), 6 2.1 在循环中,把每个特征的值都拿出来 7 2.2 去重,便可以看出该特征有几种情况 也就是有多少个分支 8 2.3 根据每一种情况 选取该类型的数据 也是数据划分 用到splitDataSet, 分支循环 (两层训话嵌套) 9 3. 计算当前特征的熵 根据循环结果 和 联合熵的计算 10 4. 计算信息增益 并 贪婪的选择增益最大的 11 :param dataSet: 数据集 12 :return: 当前最适合做分类的特征的坐标 13 ''' 14 # 特征的个数 15 numFeatures = len(dataSet[0]) - 1 # 长度减1 把标签去了 为了只选取特征 16 # 计算数据的熵 17 baseEntropy = calcshannonEnt(dataSet) # 计算整个数据的熵 18 bestInfoGain = 0.0 19 bestFeature = -1 20 21 for i in range(numFeatures): # 在特征中循环 22 featList = [example[i] for example in dataSet] # 所有数据中,该类特征的值 23 uniqueVals = set(featList) # 去重了 就是该类特征会分成几种情况, 也就是说如果以该特征划分 有几个分支 24 newEntropy = 0.0 25 for value in uniqueVals: # 分支的循环 26 subDataSet = splitDataSet(dataSet, i, value) # 按照特征, 分支划分数据集 27 prob = len(subDataSet) / float(len(dataSet)) 28 newEntropy += prob * calcshannonEnt(subDataSet) 29 infoGain = baseEntropy - newEntropy # 信息增益的求取--》I(x,y) = H(x) - H(x|y) 30 if infoGain > bestInfoGain: 31 bestInfoGain = infoGain 32 bestFeature = i 33 return bestFeature
5. 定义叶子节点
1 def majorityCnt(classList): 2 ''' 3 定义叶子节点 4 :param classList: 5 :return: 返回排序结果最优的作为节点 6 ''' 7 classCount = {} 8 for vote in classList: 9 if vote not in classCount.keys(): 10 classCount[vote] = 0 11 classCount[vote] += 1 12 sortedClassCount = sorted(classCount.items(), key=operator.itemgetter(1), reverse=True) # 字典排序 13 return sortedClassCount[0][0]
6. 创建决策树
1 def createTree(dataSet, labels): 2 ''' 3 递归生成决策树 4 :param dataSet: 数据集 5 :param labels: 标签 6 :return: 字典形式的决策树 7 ''' 8 classList = [example[-1] for example in dataSet] # 取标签 9 if classList.count(classList[0]) == len(classList): 10 return classList[0] 11 12 if len(dataSet[0]) == 1: 13 return majorityCnt(classList) 14 bestFeat = chooseBestFeatureToSplit(dataSet) 15 bestFeatLabel = labels[bestFeat] 16 myTree = {bestFeatLabel: {}} 17 # del(labels[bestFeat]) # del 会直接修改原数据 造成 'no surfacing' is not in list 的错误 18 subLabels = labels[:] 19 del(subLabels[bestFeat]) 20 featValues = [example[bestFeat] for example in dataSet] # 该特征下的值 21 uniquevals = set(featValues) 22 # 根据该标签下的值进行划分 递归 23 for value in uniquevals: 24 subLabels = subLabels[:] 25 myTree[bestFeatLabel][value] = createTree(splitDataSet(dataSet, bestFeat, value), subLabels) 26 return myTree
需要注意的是,第17行注释的代码,直接del 回修改原数据,造成'no surfacing' is not in list 的错误。应使用第18行19行的代码。
7. 决策树使用接口
在生成了决策树模型后,便可以使用测试数据进行验证。
1 def classify(inputTree, featLabels, testVec): 2 ''' 3 分类函数 4 :param inputTree: 决策树 5 :param featLabels: 特征标签 6 :param testVec: 测试向量 7 :return: 8 ''' 9 firstStr=next(iter(inputTree)) 10 # 下一个字典 11 secondDict=inputTree[firstStr] 12 featIndex=featLabels.index(firstStr) 13 14 for key in secondDict.keys(): 15 if testVec[featIndex] == key: 16 if type(secondDict[key]).__name__ == 'dict': 17 classLabel=classify(secondDict[key], featLabels, testVec) 18 else: 19 classLabel=secondDict[key] 20 return classLabel
8. 调用
1 data, label = createDataSet() 2 # ret = splitDataSet(data, 1, 1) 3 # print(ret) 4 shannon = calcshannonEnt(data) 5 print(shannon) 6 bestFeat = chooseBestFeatureToSplit(data) 7 mytree = createTree(data, label) 8 print(mytree) 9 result = classify(mytree, label, [0, 0]) 10 print(result)
生成字典形式的决策树模型
![]()
测试结果:
![]()
模型的保存与读取
构造决策树是一项比较耗时的任务,构造好的决策参数可以将其保存下来,以便之后调用,而不用每次对数据分类时都重新学习一遍。回顾之前Knn算法的流程是无法构建持久化分类器的,难以通过参数保存模型。
在python中,模型的保存和读取有很多中方式,这里先介绍四种情况:
1. 将模型依格式直接写为txt
(无论模型是什么样的格式)进行存储;读取时,将txt读入,并使用eval转换为原来的格式。
(决策树模型是字典格式)
模型保存:
1 def save_obj(obj, name): 2 ''' 3 将字典保存成txt 用于存储模型的参数 4 :param obj: 要保存的文件 5 :param name: 要命名的名字 6 :return: 没有返回值 会在电脑中保存一个txt 7 ''' 8 f = open(name + '.txt', 'w') 9 f.write(str(obj)) 10 f.close()
模型读取:(将字符串类型的字典转化为字典,当然字符串类型的列表元组什么的都可以)
1 def load_obj(name): 2 ''' 3 将txt读入, 并字典形式的字符串转成字典 4 :param name: 要读取文件的名字 不需要加.txt 5 :return: 返回一个字典类型的变量 其中包含模型的各种参数 6 ''' 7 f = open(name + '.txt','r') 8 a = f.read() 9 # info_all = {} # 不需要给它命名格式 10 info_all = eval(a) 11 f.close() 12 return info_all
调用:
1 save_obj(mytree, 'mytree') 2 mytree1 = load_obj('mytree')
2. 使用pickle模块依模型格式写为txt
(无论模型是什么样的格式)进行存储;读取时,也使用pickle模块进行读取。
需要注意的是在python3中,使用pickle模块需要使用byte的存储可读取格式,即‘rb’, ‘wb’,否则会出现下述错误,python2中不需要。
模型存储:(需导入pickle模块)
1 def storeTree(inputTree, filename): 2 ''' 3 模型存储 pickle 方式 4 :param inputTree: 决策树模型 5 :param filename: 保存文件名 6 :return: 7 ''' 8 # import pickle 9 fw = open(filename, 'wb') 10 pickle.dump(inputTree, fw) 11 fw.close()
模型读取:
1 def grabTree(filename): 2 ''' 3 读取文件 4 :param filename: 文件名 5 :return: 返回读取信息 6 ''' 7 # import pickle 8 fr = open(filename, 'rb') 9 return pickle.load(fr)
调用:
1 storeTree(mytree, 'mytree.txt') 2 my_tree1 = grabTree('mytree.txt')
3. 使用dill直接保存工作区
(有时会有保存所有工作区的需求)
1 dill.dump_session('mytree.pkl')
4. numpy存储
(这种方式会改变变量的类型转变为ndarray,适合numpy数组形式的变量)
1 np.save('A机各列信息.npy', info_all) 2 info_all_A = np.load('A机各列信息.npy')
总结
总结:
开始处理数据集时,首先需要测量集合中数据的不一致性,也就是熵,然后寻找最优方案划分数据集,直到数据集中的所有数据属于同一分类。
本文主要介绍的是决策树中的ID3算法,是通过信息增益划分数据,还有基尼系数等别的类型的决策树。例如C4.5,CART等。决策树一般很少单独使用,会结合随机森林使用。
-------------------------------------------
算法届的小学生,虔诚而不迷茫,做一个懂生活并有趣的人!
如果觉得这篇文章对你有小小的帮助的话,记得在右下角点个 [推荐] 噢! 欢迎共同交流机器学习,机器视觉,深度学习~
欢迎转载,转载请声明出处!
