
reids数据结构(四) ziplist
1.为什么使用
优势:
在普通的双向链表中因为保存了前一个结点和后一个节点的指针,所有容易照成空间的浪费,而且链表中的数据可以保存在不连续的内存空间中,这就很容易产生大量的内存碎片,从而影响内存的分配和读写效率.
为了解决内存利用率和内存碎片的问题,redis设计了ziplist.ziplist中的元素都保存在同一块连续的内从空间中,并且节点中只保存了前一个节点的长度,没有保存前一个和后一个节点的地址.
缺点:
为了方便从后向前遍历,redis在ziplist中还保存了最后一个元素的地址.这样设计同时也带来了插入元素的时候需要重新分配内存地址并且复制原来元素的问题,所以ziplist不适合保存很多的元素.而且因为保存了前一个元素的长度,而redis为了节省空间根据不同的长度redis使用不同的字节数来保存,在更新和删除元素的时候还能造成级联更新的问题.所以在保存数据量较少的数据时,ziplist才有优势.
2.ziplist的内部结构
2.1ziplist的整体结构
struct ziplist<T> { int32 zlbytes; // 整个压缩列表占用的字节数 int32 zltail_offset; // 最后一个元素距离压缩列表起始位置的偏移量,用于快速定位到最后一个节点 int16 zllength; // 真个ziplist中元素的个数 T[] entries; // 元素内容列表,挨个挨个紧凑存储
int8 zlend; // 标志压缩列表的结束,值恒为 0xFF }
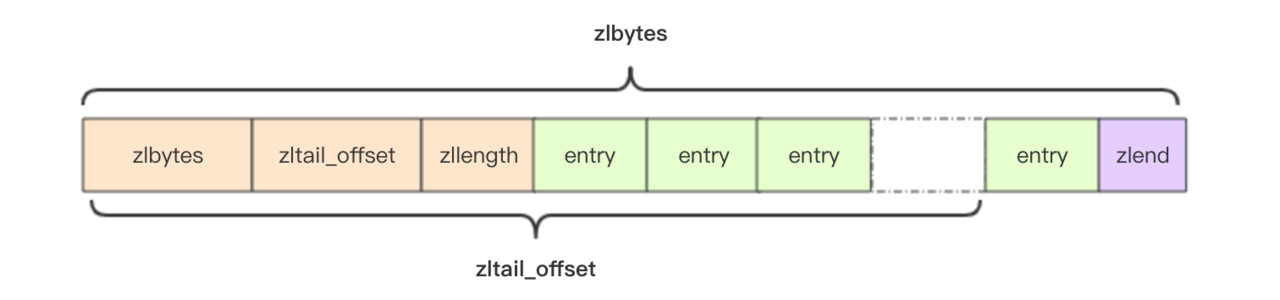
整个ziplist是一个字节数组,数组的[0,3]字节固定为zlbyets,[4,7]字节固定为zltail,[8-9]字节固定为zllen,然后紧跟着保存了zlentry,其中zlentry中保存了真实的数据.最后一个字节固定为zlend.
zlbytes:真个ziplist所占用的字节数.
zltail_offset:ziplist中最后一个元素的指针,用于快速定位到最后一个元素,方便从后向前遍历和从列表最后插入,删除元素.
zllength:整个ziplist列表中元素的总个数,最大为2^16-1个元素,如果ziplist中元素的个数超过了2^16-1个,那么这个值也不会改变,固定为2^16-1个.所以当该值为2^16-1的时候,ziplist中的元素的数量是大约等于2^16-1的,如果想要知道具体的元素的个数,就需要遍历整个ziplist,这个是非常耗时的,所以在使用ziplist的时候最好不要超过2^16-1个.
2.2 zlEntry的结构
struct entry { int<var> prevlen; // 前一个 entry 的字节长度 int<var> encoding; // 元素类型编码 optional byte[] content; // 元素内容 }
prevlen:表示前一个entry的字节长度,当倒着遍历ziplist的时候需要这个字段来确定上一个元素的位置.这是个边长的整数.上一个元素的字节长度小于254的时候使用一个字节表示,当大于等于254的时候使用5个字节表示长度,第一个字节固定为254,后面四个字节表示字符串的长度.为什么是254不是255?因为255已经被用来当作ziplist的结束符了,所以这里只能使用254了.
encoding:content的编码方式,redis通过这个字段表示表示content的编码类型以及content的长度.下面我们详细介绍一下这个字段是怎么表示不同的编码类型和长度的.
1、00xxxxxx 最大长度位 63 的短字符串,后面的 6 个位存储字符串的位数,剩余的字节就是字符串的内容。
2、01xxxxxx xxxxxxxx 中等长度的字符串,后面 14 个位来表示字符串的长度,剩余的字节就是字符串的内容。
3、10000000 aaaaaaaa bbbbbbbb cccccccc dddddddd 特大字符串,需要使用额外 4 个字节来表示长度。第一个字节前缀是 10,剩余 6 位没有使用,统一置为零。后面跟着字符串内容。不过这样的大字符串是没有机会使用的,压缩列表通常只是用来存储小数据的。
4、11000000 表示 int16,后跟两个字节表示整数。
5、11010000 表示 int32,后跟四个字节表示整数。
6、11100000 表示 int64,后跟八个字节表示整数。
7、11110000 表示 int24,后跟三个字节表示整数。
8、11111110 表示 int8,后跟一个字节表示整数。
9、11111111 表示 ziplist 的结束,也就是 zlend 的值 0xFF。
10、1111xxxx 表示极小整数,xxxx 的范围只能是 (0001~1101), 也就是 1~13,因为0000、1110、1111 都被占用了。读取到的 value 需要将 xxxx 减 1,也就是整数 0~12 就是最终的 value。
content:content 字段在结构体中定义为 optional 类型,表示这个字段是可选的,对于很小的整数而言,它的内容已经内联到 encoding 字段的尾部了
3.级联更新
因为zlEntry中保存了前一个元素的长度,而且这个长度又是一个边长的整数,所以当一个zlEntry的前面的元素改变(内容改变或者被删除,或者插入了新的元素)时,可能造成prevlen长度的改变,而prevlen长度的改变又会使整个zlEntry的的长度改变,当当前zlEntry的长度改变的时候又可能会造成下一个zlEntry的长度的改变,这就造成了级联更新.如果ziplist中元素很多造成的级联更新影响可能会很大,影响整个redis服务,所以ziplist不适合存放的元素过多.
4.相关配置
1.hash-max-ziplist-entries 512
当hash中元素的个数少于512的时候使用ziplist保存数据,超过的时候使用dict
2.hash-max-ziplist-value 64
当hash中最大元素的字节占用不超过64的时候使用ziplist保存数据,超过的时候使用dict
5.使用ziplist的数据类型
Redis 为了节约内存空间使用,zset 和 hash 容器对象在元素个数较少的时候,采用压缩列表 (ziplist) 进行存储。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号