mysql group replication观点及实践
一:个人看法
Mysql Group Replication 随着5.7发布3年了。作为技术爱好者。mgr 是继 oracle database rac 之后。
又一个“真正” 的群集,怎么做到“真正” ? 怎么做到解决复制的延迟,怎么做到强数据一致性?基于全局的GTID就能解决? 围绕这些问题进行了一些mgr 的实践,
为未来的数据库高可用设计多条选择。
mysql5.7手册17章可以看到其原理,网络上也很多同志写了关于其技术原理,这里自己对比rac理解下:
作为shared nothing (mgr)架构,其数据一致性实现较 shared everything(RAC) 架构要难,
MGR通过一致性(Paxos)协议,保证数据在复制组内的存活节点里是一致的,复制组内的各成员都可以进行读写,
其实现机制是,当某个实例发起事务提交时,会向组内发出广播,由组内成员决议事务是否可以正常提交,
MGR在遇到事务冲突时(多节点同时修改同一行数据),会自动识别冲突,并根据提交时间让先提交的事务成功执行,后提交的事务回滚,其原理示意图如下:
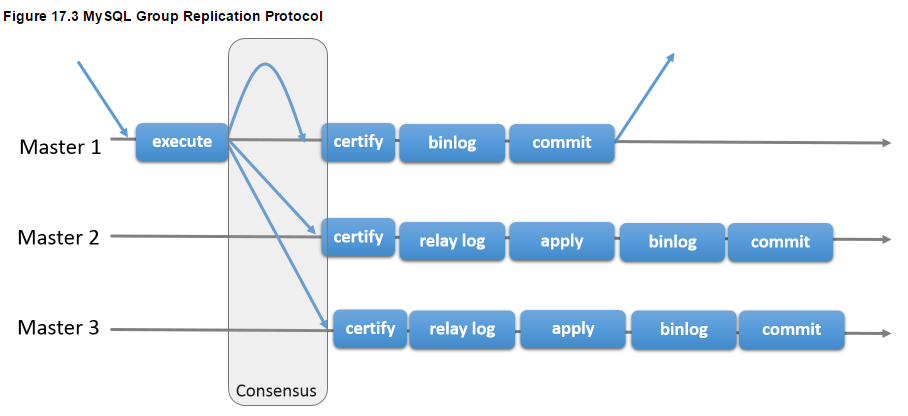
对于 sharad nothing 架构,必须要了解分布式协议PAXOS,分布式状态机 理论,而在这块我翻阅了很多资料,发现其实并不是很成熟的。从上图可以看出来MGR 的冲突检测机制
类似于 rac 的gird 群集组件 也具备通告广播的群集服务。但本质架构上有所不同。一切依赖于 复制组的软件实现。如果这里出了问题,那么整个群集一致性难以得到保证。
二:搭建过程
这个过程比较粗糙,网络上有不少写的比较细的可以参考
create user repl@'%' identified by 'repl123';
grant replication slave on *.* to repl@'%';
change master to
master_user='repl',
master_password='repl123'
for channel 'group_replication_recovery';
select * from mysql.slave_relay_log_info\G
install plugin group_replication soname 'group_replication.so';
set @@global.group_replication_bootstrap_group=on; ---->是否是Group Replication的引导节点,初次搭建集群的时候需要有一个节点设置为ON来启动Group Replication
start group_replication;
set @@global.group_replication_bootstrap_group=off;
select * from performance_schema.replication_group_members;
create database test;
use test;
create table t1(id int);
create table t2(id int)engine=myisam;
create table t3(id int primary key)engine=myisam; --->不支持
create table t4(id int primary key);
3:其它节点加入组复制
change master to
master_user='repl',
master_password='repl123'
for channel 'group_replication_recovery';
install plugin group_replication soname 'group_replication.so';
set global group_replication_allow_local_disjoint_gtids_join=1;
start group_replication;
注意:
一个节点加入组复制会有本地的事物产生,比如更改密码,加入测试数据等。上述红字可以可以规避上述事务,强制加入,也可以在本地事务开始之前进行
sql_log_bin=0; start transaction.......... sql_log_bin=1;
4:维护
任意一节点启动,停止组复制。
start group_replication;
stop group_replication;
查看所有在线的组复制节点
select * from performance_schema.replication_group_members;
查看谁是主节点,单主模式下,能查出值,多主模式下无法查出。
select b.member_host the_master,a.variable_value master_uuid from performance_schema.global_status a join performance_schema.replication_group_members b on a.variable_value = b.member_id where variable_name='group_replication_primary_member';
+------------+--------------------------------------+
| the_master | master_uuid |
+------------+--------------------------------------+
| calldb3 | cc4958ae-a1cc-11e8-9334-00155d322c00 |
+------------+--------------------------------------+
三:vip的实施
mgr 并不提供vip 的概念。在单主模式下,必须启用vip实现才能做到 HA 的作用,这里的策略网络上也很多,我们基于keepalived 进行思考
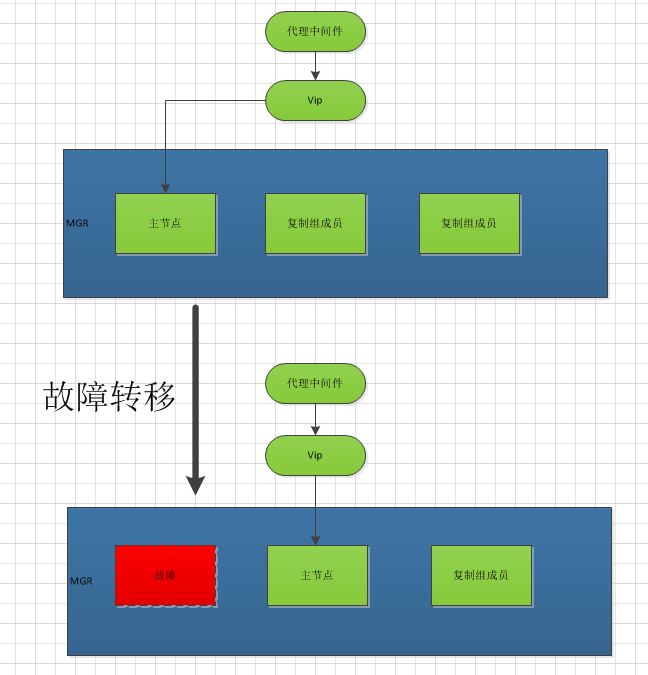
要实现上述策略,考虑故障节点的情况
1:故障节点 mysql 实例崩溃,守护进程也不能拉起改实例,需要VIP 漂移。
2:故障节点系统崩溃,段时间无法进行恢复。需要VIP 漂移。
3:判定谁是主节点,vip就漂移到主节点
基于以上3点。keepalived 除了系统故障vip漂移的功能,还需要mysql 实例崩溃的判定主节点漂移功能
具体实现:
[root@calldb1 ~]# cat /etc/keepalived/keepalived.conf vrrp_script chk_mysql_port { script "/etc/keepalived/chk_mysql.sh" ---判断实例存活 interval 2 weight -5 fall 2 rise 1 } vrrp_script chk_mysql_master { script "/etc/keepalived/chk_mysql2.sh" ---判断主节点 interval 2 weight 10 } vrrp_instance VI_1 { state MASTER interface eth0 virtual_router_id 88 priority 100 advert_int 1 authentication { auth_type PASS auth_pass 1111 } virtual_ipaddress { 192.168.0.100 } track_script { chk_mysql_port chk_mysql_master } }
判定脚本如下:
[root@calldb1 ~]# cat /etc/keepalived/chk_mysql.sh #!/bin/bash netstat -tunlp |grep mysql a=`echo $?` if [ $a -eq 1 ] ;then service keepalived stop fi
[root@calldb1 ~]# cat /etc/keepalived/chk_mysql2.sh #!/bin/bash host=`/data/mysql/bin/mysql -h127.0.0.1 -uroot -pxxx -e "SELECT * FROM performance_schema.replication_group_members WHERE MEMBER_ID = (SELECT VARIABLE_VALUE FROM performance_schema.global_status WHERE VARIABLE_NAME= 'group_replication_primary_member')" |awk 'NR==2{print}'|awk -F" " '{print $3}'` host2=`hostname` if [ $host == $host2 ] ;then exit 0 else exit 1 fi
四:采坑的地方:
1:一个节点加入组的时候,因没有种子的概念,那么它就是中心,所以要申明他是中心:
set @@global.group_replication_bootstrap_group=on;
2:如果没有在etc/hosts 文件配置ip地址到主机的解析,那么组复制一直会出现:
2019-04-30T21:58:24.604720+08:00 42 [Note] Plugin group_replication reported: 'Retrying group recovery connection with another donor. Attempt 6/10' 2019-04-30T21:59:24.605458+08:00 42 [Note] 'CHANGE MASTER TO FOR CHANNEL 'group_replication_recovery' executed'. Previous state master_host='sanborn1', master_port= 3306, master_log_file='', master_log_pos= 4, master_bind=''. New state master_host='sanborn1', master_port= 3306, master_log_file='', master_log_pos= 4, master_bind=''. 2019-04-30T21:59:24.610029+08:00 42 [Note] Plugin group_replication reported: 'Establishing connection to a group replication recovery donor 75af6fe1-6a92-11e9-8bf8-005056a1d54e at sanborn1 port: 3306.' 2019-04-30T21:59:24.611927+08:00 50 [Warning] Storing MySQL user name or password information in the master info repository is not secure and is therefore not recommended. Please consider using the USER and PASSWORD connection options for START SLAVE; see the 'START SLAVE Syntax' in the MySQL Manual for more information. 2019-04-30T21:59:24.645794+08:00 50 [ERROR] Slave I/O for channel 'group_replication_recovery': error connecting to master 'repl@sanborn1:3306' - retry-time: 60 retries: 1, Error_code: 2005 2019-04-30T21:59:24.645847+08:00 50 [Note] Slave I/O thread for channel 'group_replication_recovery' killed while connecting to master 2019-04-30T21:59:24.645861+08:00 50 [Note] Slave I/O thread exiting for channel 'group_replication_recovery', read up to log 'FIRST', position 4 2019-04-30T21:59:24.646002+08:00 42 [ERROR] Plugin group_replication reported: 'There was an error when connecting to the donor server. Please check that group_replication_recovery channel credentials and all MEMBER_HOST column values of performance_schema.replication_group_members table are correct and DNS resolvable.' 2019-04-30T21:59:24.646064+08:00 42 [ERROR] Plugin group_replication reported: 'For details please check performance_schema.replication_connection_status table and error log messages of Slave I/O for channel group_replication_recovery.' 2019-04-30T21:59:24.646271+08:00 42 [Note] Plugin group_replication reported: 'Retrying group recovery connection with another donor. Attempt 7/10'
直到脱离群集,状态一直是recovering
mysql> select * from performance_schema.replication_group_members; +---------------------------+--------------------------------------+-------------+-------------+--------------+ | CHANNEL_NAME | MEMBER_ID | MEMBER_HOST | MEMBER_PORT | MEMBER_STATE | +---------------------------+--------------------------------------+-------------+-------------+--------------+ | group_replication_applier | 75af6fe1-6a92-11e9-8bf8-005056a1d54e | sanborn1 | 3306 | ONLINE | | group_replication_applier | 8e091df0-6b4c-11e9-896b-005056a175f4 | sanborn2 | 3306 | RECOVERING | | group_replication_applier | ae657017-6b4c-11e9-8548-005056a1c149 | sanborn3 | 3306 | RECOVERING | +---------------------------+--------------------------------------+-------------+-------------+--------------+ 3 rows in set (0.01 sec)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号