GPT1-GPT3
简介
GPT(Generative Pre-trained Transformer)系列是由OpenAI提出的非常强大的预训练语言模型,这一系列的模型可以在生成式任务中取得非常好的效果,对于一个新的任务,GTP只需要很少的数据便可以理解任务的需求并达到或接近state-of-the-art的方法。
GPT训练需要超大的训练语料以及堆叠的transformer,123系列具体情况如下:
| 模型 | 发布时间 | 参数量 | 预训练数据量 |
|---|---|---|---|
| GPT-1 | 2018年6月 | 1.17亿 | 约5GB |
| GPT-2 | 2019年2月 | 15亿 | 40G |
| GPT-3 | 2020年5月 | 1750亿 | 45TB |
GPT的三个模型几乎都是相同架构, 只是有非常非常少量的改动. 但一代比一代更大, 也更烧钱. 所以我对GPT系列的特点就是: 钞能力, 大就完事了. 其影响力和花费的成本是成正比的.
GPT-1(通过生成式预训练提高语言理解)
传统的NLP模型往往使用大量的数据对有监督模型进行训练,这种任务存在两个明显的缺点:
-
需要大量的标注数据,高质量的数据往往很难获得;
-
一个任务训练的模型很难泛化到其他任务中,这个模型只能叫“领域专家”而不是真正的理解NLP。
GPT-1先通过无标签数据学习一个生成式的语言模型,然后再根据特定任务进行微调。任务包括
-
自然语言推理(NLI):判断两个句子是否包含关系,矛盾关系,中立关系;
-
问答和常识推理:类似多选题,输入文章,问题以及若干候选答案,输出为每个答案的概率;
-
语义相似度:判断两个句子语义上是否相关;
-
分类:判断输入文本是指定的那个类别。
数据集
GPT-1使用的数据集BooksCorpus,包含7000本没有发布的书籍。使用原因由两点:
- 有助于未见过的数据集上训练语言模型,该数据不太可能在下游任务的测试集中找到;
- 数据集拥有长的合理的上下文依赖关系,使得模型学习更长的依赖关系。
网络结构
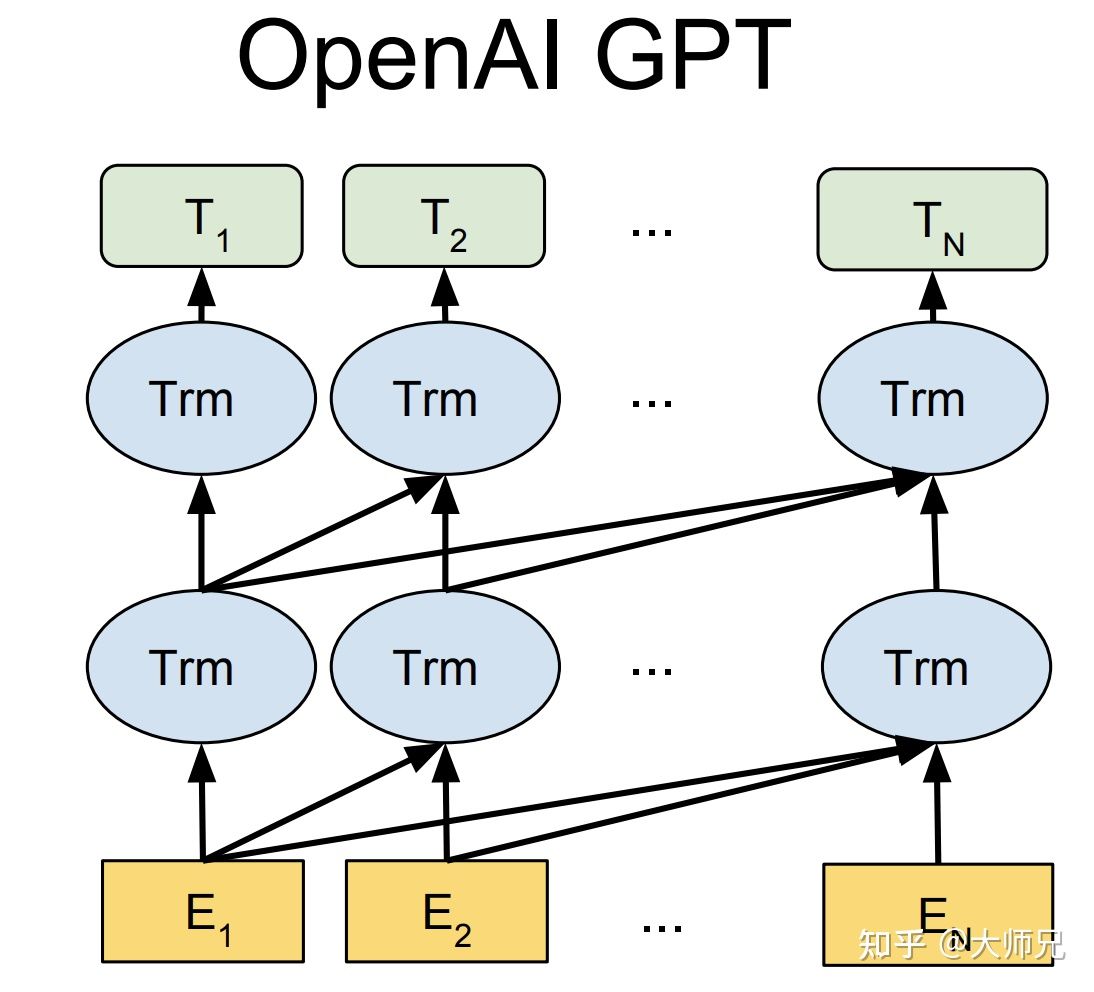
使用12层仅解码器带有掩码自注意力的transormer,掩码的使用使模型看不见未来的信息,得到模型泛化能力更强。
实现细节
- 使用字节对编码(BPE:byte pair encoding),共有4000个字节对;
- 词编码长度为768;
- 位置编码也需要学习;
- 12层transformer,每个transformer块有12个头;
- 位置编码的长度是3072;
- Attention,残差,Dropout等机制用来进行正则化,drop比例为0.1;
- 激活函数GLUE;
- 训练的batchsize为64,学习率为\(\color{blue}{2.5e^{-4}}\),序列长度为512,序列epoch为100。
训练
GPT-1的训练分为无监督训练和有监督微调,详细过程如下:
无监督预训练
GPT-1的无监督预训练是基于语言模型进行训练的,给定一个无标签的序列\(\color{blue}{U={u_1,...,u_n}}\),语言模型的优化目标是最大化似然函数:
其中\(\color{blue}{k}\)是滑动窗口的大小,\(\color{blue}{P}\)是条件概率,\(\color{blue}{\theta}\)是模型参数,这些参数使用SGD进行优化。在GPT-1中,使用12个transformer块的结构作为解码器,每个transformer块是一个多头注意力机制,然后通过全连接得到输出的概率分布。
其中 \(\color{blue}{U=(u_{-k},\dots,u_{-1})}\)是当前时间片的上下文token,\(\color{blue}{n}\)是层数,\(\color{blue}{w_e}\)是词嵌入矩阵,\(\color{blue}{W_p}\)是位置嵌入矩阵。
有监督微调
当得到无监督预训练模型之后,我们将它的值应用到有监督任务中,对于一个有标签的数据集\(\color{blue}{C}\),每个实例有\(\color{blue}{m}\)个输入token:\(\color{blue}{x^1,...,x^m}\),它对应的标签\(\color{blue}{y}\)组成。首先将这些token输入到训练好的预训练模型中,得到最终的特征向量\(\color{blue}{h_l^m}\)。然后再通过一个全连接层得到预测结果\(\color{blue}{y}\):
其中\(\color{blue}{W_y}\)为全连接层的参数。有监督的目标则是最大化公式(5)的值:
作者并没有直接使用\(\color{blue}{L_2}\),而是向其中加入了\(\color{blue}{L_1}\),并通过\(\color{blue}{\lambda}\)调节权重,一般采用0.5,公式(7)如下:
相关任务输入变化
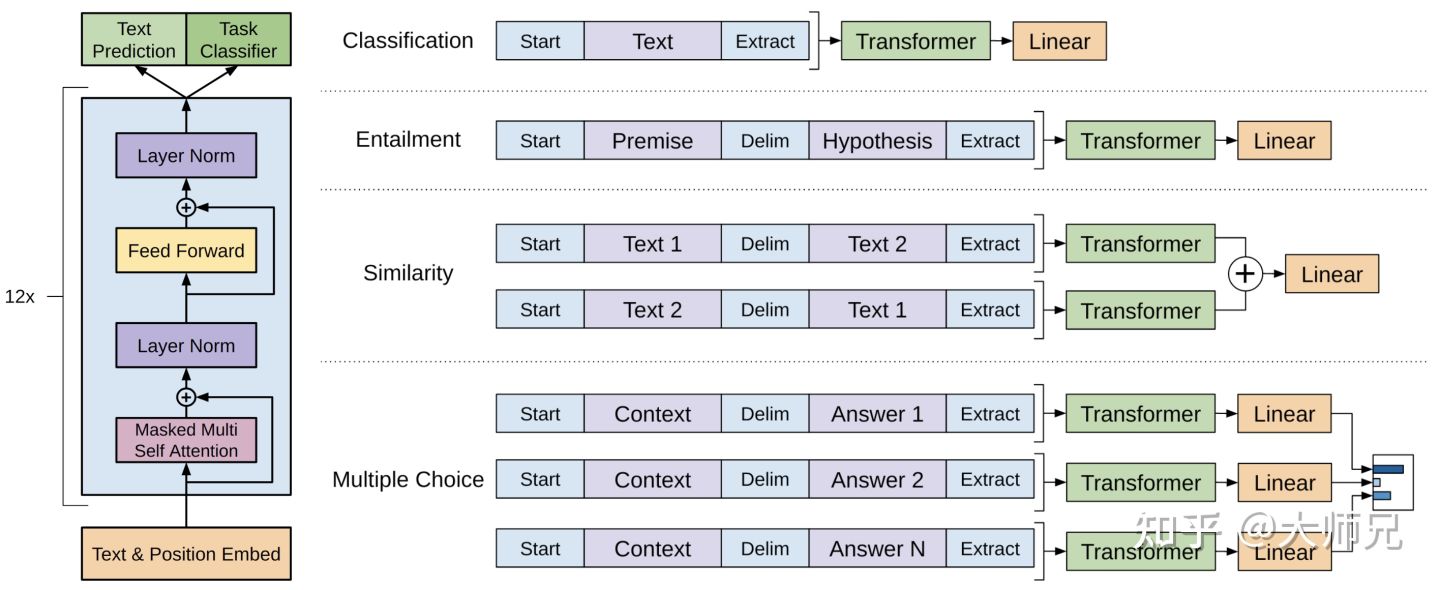
GPT-1对不同的任务形式有不同的输入形式,具体如下:
- 分类任务:将起始和终止的token加入到原始序列两端,输入transformer中得到特征向量,最后经过一个全连接层得到预测的概率分布;
- NLI任务:将前提和假设同通过分割符隔开,两端加上起始和终止token,再一次通过transformer和全连接得到预测结果;
- 语义相似度任务:输入两个句子,正向和反向各拼接一次,然后分别输入给transformer,得到特征向量拼接后再送给全连接得到预测结果;
- 问答和常识推断:将\(\color{blue}{n}\)个选项的问题抽象化为\(\color{blue}{n}\)二分类问题,即每个选项分别和内容进行拼接,然后各送入transformer和全连接中,最后选择置信度最高的作为预测结果。
对比bert
GPT在预训练时并没有引入[CLS]和[SEP], Bert全程引入;Bert是真正能够捕捉所有层上下文信息的,受益于自注意力机制,将所有token距离直接缩短到1,GPT-1是单向捕捉信息;- input:
GPT采用BPE,Bert用了Word Piece.GPT有位置编码,Bert有位置编码和段编码.
\(\color{red}{Bert 详见我另一篇blog}\)
GPT-2(语言模型式无监督的多任务学习)
GPT-2的目标是为了训练一个泛化能力更强的词向量模型,它并没有对GPT-1的网络机构进行过多的结构创新和设计,只是使用了更大的数据集和更大的网络参数。
数据集
GPT-2的文章取自于Reddit上高赞的文章,命名为WebText。数据集共有约800万篇文章,累计体积约40G。为了避免和测试集的冲突,WebText移除了涉及Wikipedia的文章。
网络结构
-
同样使用了字节对编码构建字典,字典大小为50257;
-
有48层,词嵌入大小1600维;
-
滑动窗口大小为1024;
-
batchsize 512;
-
Layer Normalization移动到了每一块的输入部分,在每个self-attention知后额外添加了一个Layer Normalization;
-
将残差层的初始化值用\(\color{blue}{1/\sqrt{N}}\),其中
N是残差层的个数。 GPT-2训练了4组不同的层数和词向量的长度的模型,具体值见表2。通过这4个模型的实验结果我们可以看出随着模型的增大,模型的效果是不断提升的。
参数量 层数 词向量长度 117M(GPT-1) 12 769 345M 24 1024 762M 36 1280 1542M 48 1600
GPT-2小结
GPT-2的最大贡献是验证了通过海量数据和大量参数训练出来的词向量模型有迁移到其它类别任务中而不需要额外的训练。但是很多实验也表明,GPT-2的无监督学习的能力还有很大的提升空间,甚至在有些任务上的表现不比随机的好。尽管在有些zero-shot的任务上的表现不错,但是我们仍不清楚GPT-2的这种策略究竟能做成什么样子。GPT-2表明随着模型容量和数据量的增大,其潜能还有进一步开发的空间,基于这个思想,诞生了我们下面要介绍的GPT-3。
GPT-3(语言模型少量学习)
数据集
GPT-3共训练了5个不同的语料,分别是低质量的Common Crawl,高质量的WebText2,Books1,Books2和Wikipedia,GPT-3根据数据集的不同的质量赋予了不同的权值,权值越高的在训练的时候越容易抽样到。
网络结构
GPT-3沿用了GPT-2的结构,但是在网络容量上做了很大的提升,具体如下:
- GPT-3采用了96层的多头transformer,头的个数为96;
- 词向量的长度是12888 ;
- 上下文划窗的窗口大小提升至2048个token;
- 使用了alternating dense和locally banded sparse attention。
GPT-3 总结
本文讨论了 GPT-3 模型的几个弱点以及有待改进的领域。让我们在这里总结一下。
- 尽管
GPT-3能够生成高质量的文本,但有时它会在编写长句子并一遍又一遍地重复文本序列时开始失去连贯性。此外,GPT-3在自然语言推理(确定一个句子是否暗示另一个句子)、填空、一些阅读理解任务等任务上表现不佳。该论文引用GPT模型的单向性作为可能的原因这些限制并建议以这种规模训练双向模型来克服这些问题; - 该论文指出的另一个限制是
GPT-3的通用语言建模目标,它平等地权衡每个token,并且缺乏任务或面向目标的token预测的概念。为了解决这个问题,本文提出了诸如增强学习目标、使用强化学习来微调模型、添加其他模式等方法; GPT-3的其他限制包括复杂且昂贵的模型推理,因为其结构繁重,语言的可解释性和模型生成的结果较低,以及围绕什么有助于模型实现其少量学习行为的不确定性;- 除了这些限制之外,
GPT-3还存在滥用其类人文本生成能力进行网络钓鱼、垃圾邮件、传播错误信息或执行其他欺诈活动的潜在风险。此外,GPT-3生成的文本具有其训练所用语言的偏见。GPT-3生成的文章可能存在性别、种族、种族或宗教偏见。
巨人的肩膀
本文来自博客园,作者:爱吃帮帮糖,转载请注明原文链接:https://www.cnblogs.com/monkeyT/p/16107018.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号