NLP系列4:NER模型介绍
NER
标准
LSTM+CRF
问题
标准成本昂贵
泛化迁移能力不足
可解释性不强
计算资源
- JD和CV描述形式不一样
- 严谨性,简历内容要识别出能力词以及深层挖掘能力词(看起来并不是能力词,但是代表实际的某项能力),所以的深度挖掘词意
- 不依赖NER,根据词典或者特定语句形式(规则)提出实体词,最后进行标准化(💡现在做的实体标准化是不是应该也是这个作用?)
- 模型应该又轻又快,抛弃万能的bert系列
建议
- 不要对Bert模型进行蒸馏压缩
- NER是一个重底层任务(待补充)
- NER任务尽量不要引入嵌套实体,例如:
Python开发,模型识别出Python开发标记为一个技能词,这时候就倾向于所有出现的Python开发都标记为技能词。但是如果模型能够在识别Python开发的同时能将Python标记为一种语言或者编程语言,那么所有出现的[语言]开发都能够识别为技能词,这样模型就学到一种模式,并非单独一个词。
**快速提升NER性能 **
——————————————————————————————————————————————————
垂直领域的词典+规则,词典不断积累,迭代,快速应急处理badcase, 通⽤领域,可以多种分词工具和多种句法短语⼯具进行融合来提取候选实体,并结合词典进行NER
embedding层,引入丰富的char、bigram、词典、词性以及业务相关特征,垂直领域可以预训练一个领域相关字向量模型、词向量模型以及bigram模型和语言模型💡?,底层特征越丰富,差异化越大越好,不同视角的特征
如何构建引入词汇信息(词向量)的NER? 我们知道中文NER通常是基于字符进行标注的,这是由于基于词汇标注存在分词误差问题。但词汇边界对于实体边界是很有用的,我们该怎么把蕴藏词汇信息的词向量“恰当”地引入到模型中呢?一种行之有效的方法就是信息无损的、引入词汇信息的NER方法,我称之为词汇增强,可参考《中文NER的正确打开方式:词汇增强方法总结》。ACL2020的Simple-Lexicon和FLAT两篇论文,不仅词汇增强模型十分轻量、而且可以比肩BERT的效果
粗暴的方法将词向量引入到模型中,就是将词向量对齐到相应的字符,然后将字词向量进行混合,但这需要对原始文本进行分词(存在误差),性能提升通常是有限的。
——————————————————————————————————————————————————
词汇增强方式
主要分为两个方向
- Dynamic Architecture:设计一个动态框架,能够兼容词汇输入--> 结构融入词汇信息
- Adaptive Embedding:基于词汇信息,构建自适应Embedding-->

[1] Lattice LSTM:Chinese NER Using Lattice LSTM(ACL2018)
中文词汇信息开山之作,通过词典匹配句子,得到一个Lattice的结构
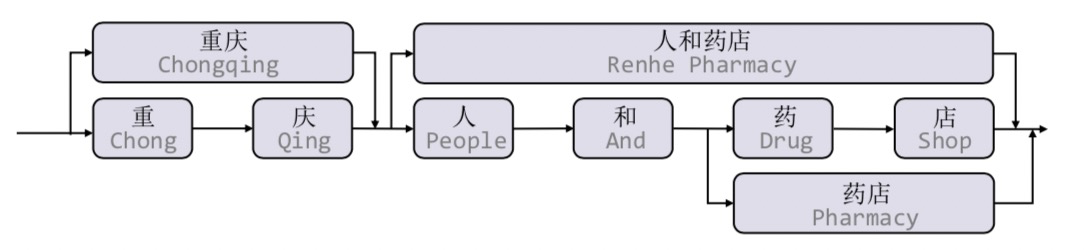
Lattice是一个有向无环图,词汇的开始和结束字符决定了其位置,Lattice LSTM融合了词汇信息到原生的LSTM中
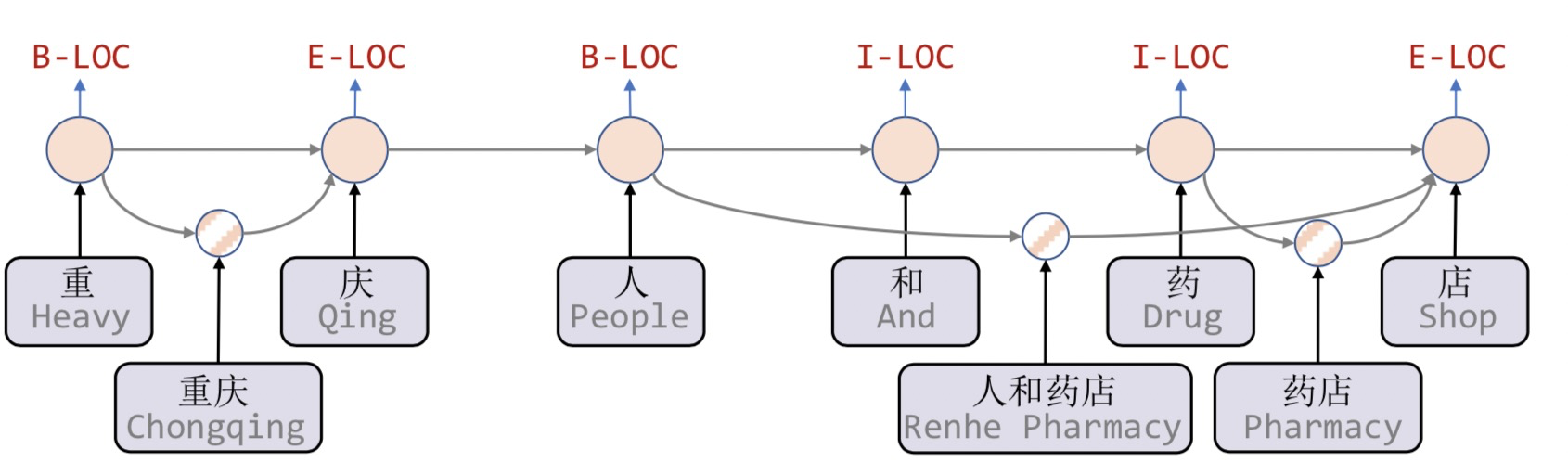
Lattice LSTM引入了一个word cell结构,对当前字符融合以该字符为结束的所有word信息,例如店融合了人和药店,药店的信息。对于每个字符,Lattice LSTM采用注意力机制去融合个数可变的word cell单元,表达式为:
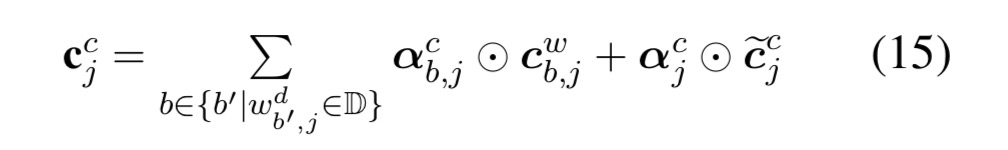
主要区别在于
当前字符有词汇信息可以融入,则利用公式15,采用公式15,不利用上一时刻记忆状态
其中
集合D类似对桥来说,有大桥、长江大桥。
缺点
计算性能低下,不能batch并行,因为每个词增加的word cell数目不一样
信息损失,字符只能获取以他结尾的词汇信息,无之前状态,另一个就是BiLSTM时前后向词汇信息不能共享
可迁移性差
[2] LR-CNN:CNN-Based Chinese NER with Lexicon Rethinking(IJCAI2019)
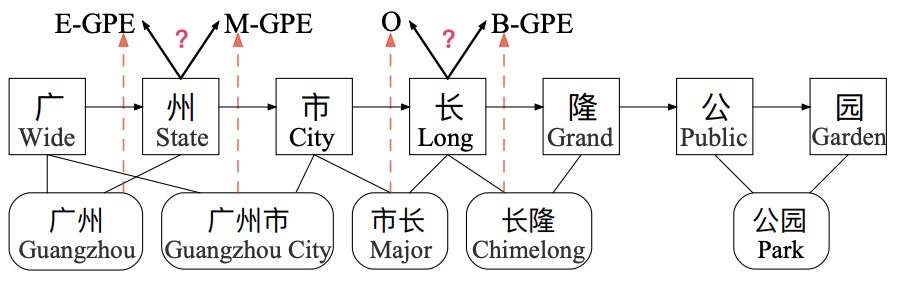
Lattice LSTM没有办法并行化,并且无法处理词汇信息冲突问题,上图中,长可以匹配市长,长隆,得到不同的实体标签,对于LSTM结构,仅依靠前一步的信息输入、而不是利用全局信息,没法解决冲突问题。
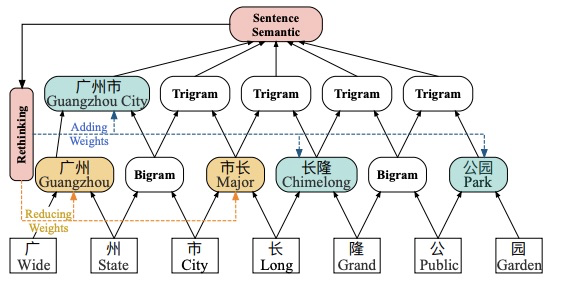
论文提出两种方法
- Lexicon-Based CNNs:采用CNN对字符特征进行编码,感受野为2提取Bi-gram特征,多层堆叠得到Multi-gram信息,同时采用注意力机制融入词汇信息
- Refining Networks with Lexicon Rethinking( 用Lexicon重新思考完善网络 ):由于上述提到的词汇信息冲突问题,LR-CNN采取rethinking机制增加feedback layer(反馈层)来调整词汇信息的权值: 具体地,将高层特征作为输入通过注意力模块调节每一层词汇特征分布。如上图,高层特征得到的 [广州市] 和 [长隆]会降低 [市长] 在输出特征中的权重分布。最终对每一个字符位置提取对应的调整词汇信息分布后的multi-gram特征,喂入CRF中解码。
最终提速3.21倍,但是仍然计算复杂不具备迁移性
CGN:利用词汇知识通过协作图网络进行中文命名实体识别(EMNLP2019)
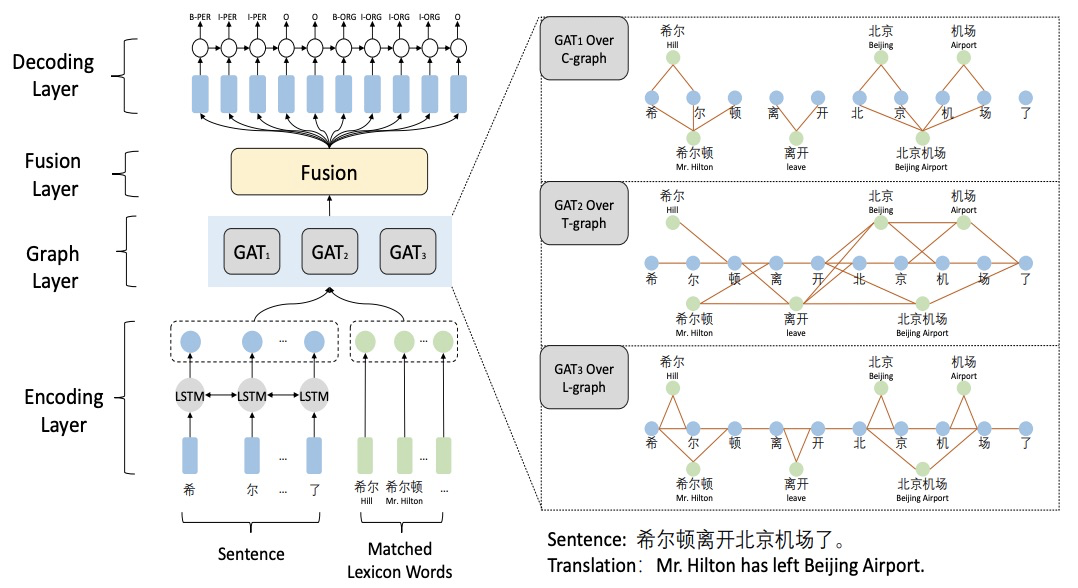
Lattice LSTM存在信息损失,特别是无法获得‘inside’的词汇信息,论文提出了基于协作的图网络,由编码层、图网络层、融合层、解码层组成,图网络层由三种不同的构建方式
- Word-Character Containing graph(C-graph):字与字之间无连接,词与其inside的字之间有连接
- Word-Character Transition graph(T-graph):相邻字符相连接,词与其前后字符连接
- Word-Character Lattice graph(L-graph):相邻字符相连接,词与其开始字符相连
图网络层通过Graph Attention Network(GAN)进行特征提取,提取三种图网络的钱n个字符节点的特征:
特征融合则基于字符的上下文表征H与图网络表征加权融合:
[4] LGN: A Lexicon-Based Graph Neural Network for Chinese NER(EMNLP2019)
LGN:面向中文NER的基于词典的图神经网络(EMNLP2019)
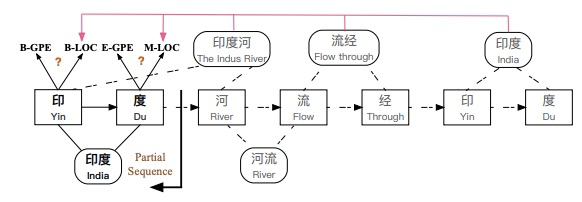
论文与LR-CNN出发点类似,Lattice LSTM这种RNN结构仅仅依靠前一步的信息输入,而不是利用全局信息,如上图所示:字符 [流]可以匹配到词汇 [河流] 和 [流经]两个词汇信息,但Lattice LSTM却只能利用 [河流] ;字符 [度]只能看到前序信息,不能充分利用 [印度河] 信息,从而造成标注冲突问题 。
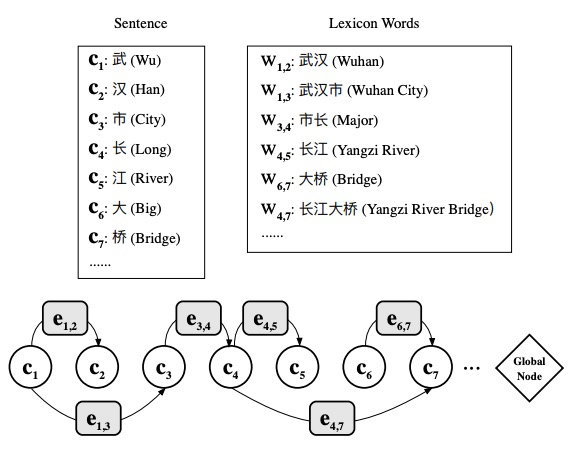
论文通过采取 lexicon-based graph neural network (LGN)来解决上述问题。如上图所示,将每一个字符作为节点,匹配到的词汇信息构成边。通过图结构实现局部信息的聚合,并增加全局节点进行全局信息融入。聚合方式采取Multi-Head Attention
[5] FLAT: Chinese NER Using Flat-Lattice Transformer(ACL2020)
Lattice-LSTM和LR-CNN采取的RNN和CNN结构无法捕捉长距离依赖,而动态的Lattice结构不能充分进行GPU并行
CGN和LGN采取的图网络虽然可以捕捉对于NER任务至关重要的顺序结构,但这两者之间的gap是不可忽略的。其次,这类图网络通常需要RNN作为底层编码器来捕捉顺序性,通常需要复杂的模型结构。
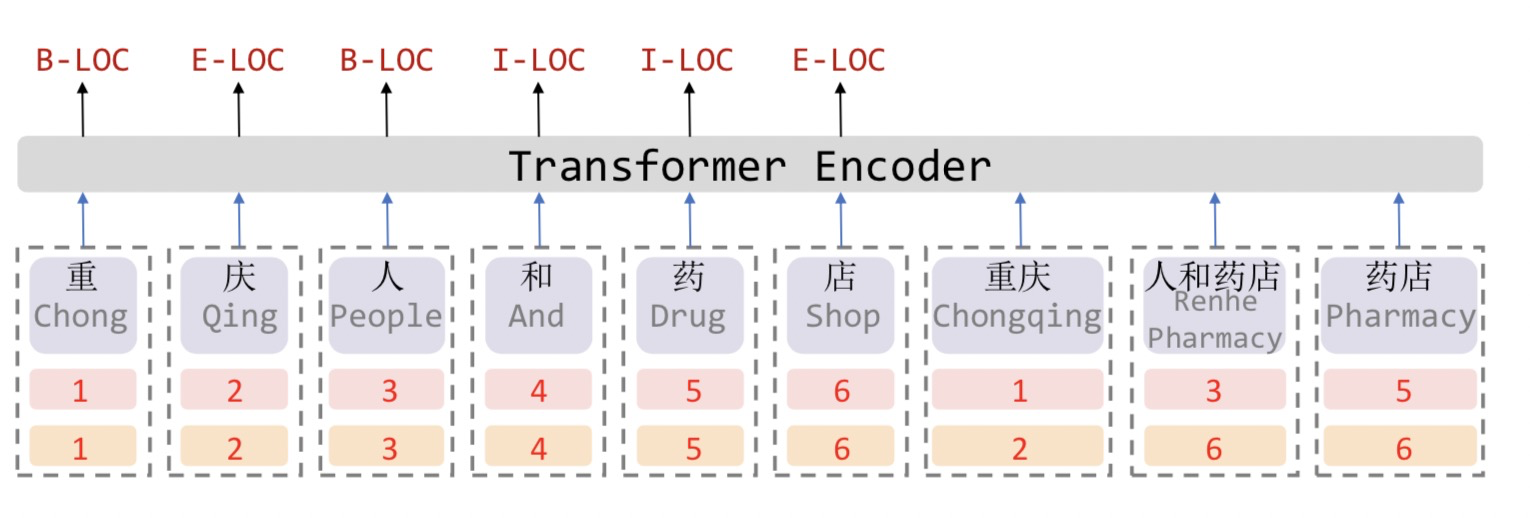
众所周知,Transformer采取全连接的自注意力机制可以很好捕捉长距离依赖,由于自注意力机制对位置是无偏的,因此Transformer引入位置向量来保持位置信息。受到位置向量表征的启发,这篇论文提出的FLAT设计了一种巧妙position encoding来融合Lattice 结构,具体地,如上图所示,对于每一个字符和词汇都构建两个head position encoding 和 tail position encoding,可以证明,这种方式可以重构原有的Lattice结构。也正是由于此,FLAT可以直接建模字符与所有匹配的词汇信息间的交互,例如,字符[药]可以匹配词汇[人和药店]和[药店]。
因此,我们可以将Lattice结构展平,将其从一个有向无环图展平为一个平面的Flat-Lattice Transformer结构,由多个span构成:每个字符的head和tail是相同的,每个词汇的head和tail是skipped的。
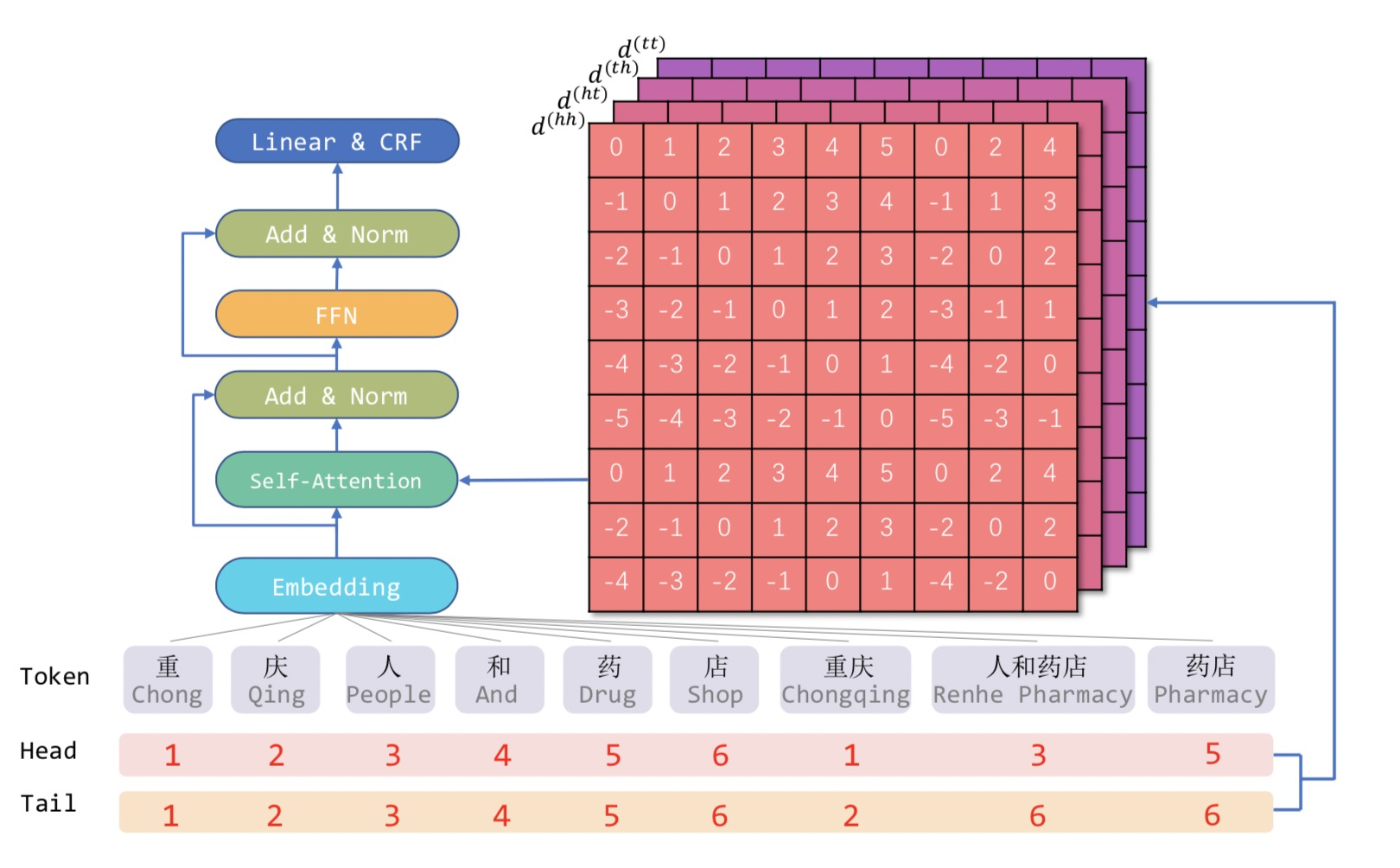
在知乎专栏文章《如何解决Transformer在NER任务中效果不佳的问题?》,我们介绍了对于Tranformer结构,绝对位置编码并不适用于NER任务。因此,FLAT这篇论文采取XLNet论文中提出相对位置编码计算attention score:
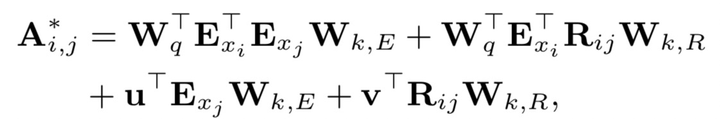
论文提出四种相对距离表示和
之间的关系,同时也考虑字符和词汇之间的关系:
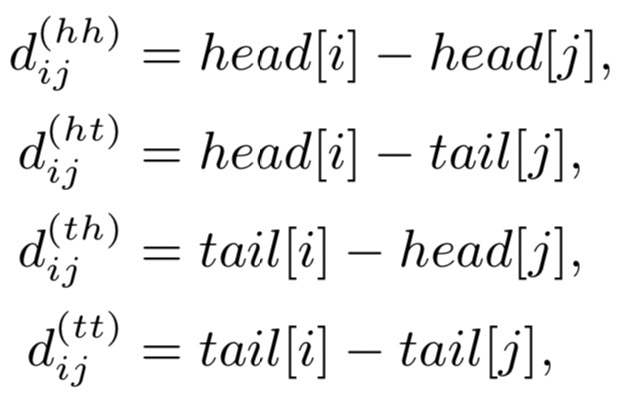
表示
的head到
的tain距离,其余类似。相对位置encoding为:
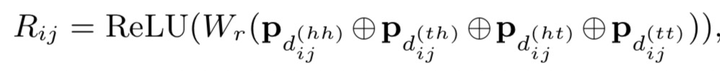
(圆圈加号)表示级联,四种距离编码通过简单的非线性变换得到。其中的计算方式与vanilla Transformer相同,
综上,FLAT采取这种全连接自注意力结构,可以直接字符与其所匹配词汇间的交互,同时捕捉长距离依赖。如果将字符与词汇间的attention进行masked,性能下降明显,可见引入词汇信息对于中文NER 的重要性。此外,相关实验表明,FLAT有效的原因是:新的相对位置encoding有利于定位实体span,而引入词汇的word embedding有利于实体type的分类。
解决NER实体span过长
——————————————————————————————————————————————————
如果NER任务中某一类实体span比较长,比如咱们提出的能力词,有很多很长
软件开发技术方案编写,直接采取CRF解码可能会导致很多连续的实体span断裂。除了加入规则进行修正外,这时候也可尝试引入指针网络+CRF构建多任务学习(指针网络会更容易捕捉较长的span,不过指针网络的收敛是较慢的,可以试着调节学习率)。
——————————————————————————————————————————————————
如何缓解NER标注数据的噪声问题
——————————————————————————————————————————————————
实际中,我们常常会遇到NER数据可能存在标注质量问题,也许是标注规范就不合理,正常的情况下只是存在一些小规模的噪声。一种简单地有效的方式就是对训练集进行交叉验证,然后人工去清洗这些“脏数据”。当然也可以将noisy label learning应用于NER任务,惩罚那些噪音大的样本loss权重
——————————————————————————————————————————————————
嵌套命名实体识别
序列标准NER问题简单两步
- 选择有效的标注Schema
- BIO
- BIOS
- 模型选择
- CNN/Bi-LSTM/BERT等
解决方法
| Python开发 中的 Python 同时属于B-语言,也属于B-技能
-
将NER的分类任务从单标签编程多标签
Schema不变,模型也不变,将输出从单标签转变为多标签
1、Schema不变,训练集label从one-hot编码形式变成指定类型的均匀分布💡?,训练时将损失函数改为BCE或KL-divergence;推理时给定一个hard threshold,超过这个阈值的都被预测出来,当作这个token的类。
- 阈值难以设定,难以泛化
2、修改Schema,将共同出现的类别两两组合,构造新的标签,B-语言|技能,最后仍然是一个单分类。
- 标签增加,分布稀疏难以学习,预测结果不具有唯一性
参考
本文来自博客园,作者:爱吃帮帮糖,转载请注明原文链接:https://www.cnblogs.com/monkeyT/p/14011066.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号