代码 trick 积累
两个list关联排序
# 打包
zipped = zip(sen,count)
# 排序
sort_zipped = sorted(zipped,key=lambda x:(x[1],x[0]),reverse=True)
# 还原
result = zip(*sort_zipped)
sen,count = [list(x) for x in result]
pandas 行列显示不全解决方式
#显示所有列
pd.set_option('display.max_columns', None)
#显示所有行
pd.set_option('display.max_rows', None)
#设置value的显示长度为100,默认为50
pd.set_option('max_colwidth',100)
git
# 撤回上一次的commit
git reset --soft HEAD^
# 删除远程分支
git push origin --delete branch-zlf
# 删除本地分支
git branch -d branch-zlf
# 创建分支
git branch branch-zlf
# 切换分支
git checkout branch-zlf
Tensor Flow Addons 版本问题
| -- | -- | -- |
|---|---|---|
| Tensor Flow Addons | TensorFlow | Python |
| tfa-nightly | 2.2 | 3.5,3.6,3.7,3.8 |
| twnsorflow-addons-0.10.0 | 2.2 | 3.5,3.6,3.7,3.8 |
| tensorflow-addons-0.9.1 | 2.1,2.2 | 3.5,3.6,3.7 |
| tensorflow-addons-0.8.3 | 2.1 | 3.5,3.6,3.7 |
| tensorflow-addons-0.7.1 | 2.1 | 2.7,3.5,3.6,3.7 |
| tensorflow-addons-0.6.0 | 2.0 | 2.7,3.5,3.6,3.7 |
pandas 删除Nan值
# dataframe 行至少有两个不为 Nan 保留,inplace True 原dataframe上进行操作
df_mark.dropna(how = 'all',thresh = 2,inplace=True)
# dataframe 行全为 Nan 删除
df_mark.dropna(how = 'all',inplace=True)
# dataframe 行有一个 Nan 删除
df_mark.dropna(how = 'any',inplace=True)
字符串查找首次出现的位置
import re
content = '1、中专以上学历,农业相关专业,从事农业技术应用与实践工作一年以上; 2、热爱农业,为人踏实稳重,能吃苦耐劳,工作认真细致,有责任感,团队协作意识强。'
i = '农业'
re.search(re.compile(i),content).span()
# output
(9, 11)
pandas 一行切分变多行
df_jd_content_split = df_jd_content['detail'].str.split('<br>|。|;\d、',expand=True).stack()
df_jd_content_split = df_jd_content_split.reset_index(level=1,drop=True).rename('detail')
df_jd_content_split = pd.DataFrame(df_jd_content_split)
pyhanlp 依存句法分析结果解析
In [56]: print(HanLP.parseDependency('宽带微波收发电路设计'))
1 宽带微波 宽带微波 nh nr _ 2 主谓关系 _ _
2 收发 收发 v v _ 0 核心关系 _ _
3 电路设计 电路设计 nz nz _ 2 动宾关系 _ _
In [62]: for word in HanLP.parseDependency('宽带微波收发电路设计'):
...: print(word.ID)
...: print(word.LEMMA)
...:
1
宽带微波
2
收发
3
电路设计
/**
* ID 当前词在句子中的序号,1开始.
*/
public int ID;
/**
* 当前词语(或标点)的原型或词干,在中文中,此列与FORM相同
*/
public String LEMMA;
/**
* 当前词语的词性(粗粒度)
*/
public String CPOSTAG;
/**
* 当前词语的词性(细粒度)
*/
public String POSTAG;
/**
* 当前词语的中心词
*/
public CoNLLWord HEAD;
/**
* 当前词语与中心词的依存关系
*/
public String DEPREL;
/**
* 等效字符串
*/
public String NAME;
sb.append(ID).append('\t').append(LEMMA).append('\t').append(LEMMA).append('\t').append(CPOSTAG).append('\t') .append(POSTAG).append('\t').append('_').append('\t').append(HEAD.ID).append('\t').append(DEPREL).append('\t').append('_').append('\t').append('_');
sb.append(ID).append('\t').append(LEMMA).append('\t').append(LEMMA).append('\t').append(CPOSTAG).append('\t').append(POSTAG).append('\t').append('_').append('\t').append(HEAD.ID).append('\t').append(DEPREL).append('\t').append('_').append('\t').append('_');
pandas 某列 按某个值删除
# content:列名,'':可以换成其他的,None等
df_search_space = df_search_space[~df_search_space.content.isin([''])]
python 判断字符串异常
def judge(hostip):
if hostip is None or not hostip or hostip == '' or hostip == 'null':
return False
else:
return True
sql group by 每个类随机抽取
select
*
from
(
select
*,
row_number() over(
partition by job_init_title
order by
rand()
) as rn
from
dw_chihiro_algo_d_job_feature
where
p_date == '20210419'
) a
where
a.rn <= 500
-- https://blog.csdn.net/qq_29232943/article/details/104635492
pandas 增加两列
def cut_match(x):
num = 0
words = [i for i in jieba.cut(x.job_title) if len(i) != 1]
for word in words:
if word in x.content:
num += 1
return (num,len(words))
df_match[['contain','total']] = df_match.apply(lambda x:cut_match(x),axis=1,result_type='expand')
# result_type='expand' 必须加
pandas 转 dict【行】
import pandas as pd
df = pd.DataFrame({"姓名": ["古明地觉"],
"水果": ["草莓"],
"星期一": ["70斤"],
"星期二": ["72斤"],
"星期三": ["60斤"],
})
out:
姓名 水果 星期一 星期二 星期三
0 古明地觉 草莓 70斤 72斤 60斤
pd.melt(df, value_vars=df.columns)
out:
variable value
0 姓名 古明地觉
1 水果 草莓
2 星期一 70斤
3 星期二 72斤
4 星期三 60斤
pd.melt(df, value_vars=df.columns).set_index('variable')['value'].to_dict()
out:
{'姓名': '古明地觉', '水果': '草莓', '星期一': '70斤', '星期二': '72斤', '星期三': '60斤'}
pb模型打印详细信息
saved_model_cli show --dir saved_model/1/ --all
pandas 按某列去重,并按另外一列最大值保留
df_loginip = df_loginip.groupby('actor_id', group_keys=False).apply(lambda x: x.loc[x.p_date.idxmax()]) # 按照actor_id去重,并按照p_date最大的保留
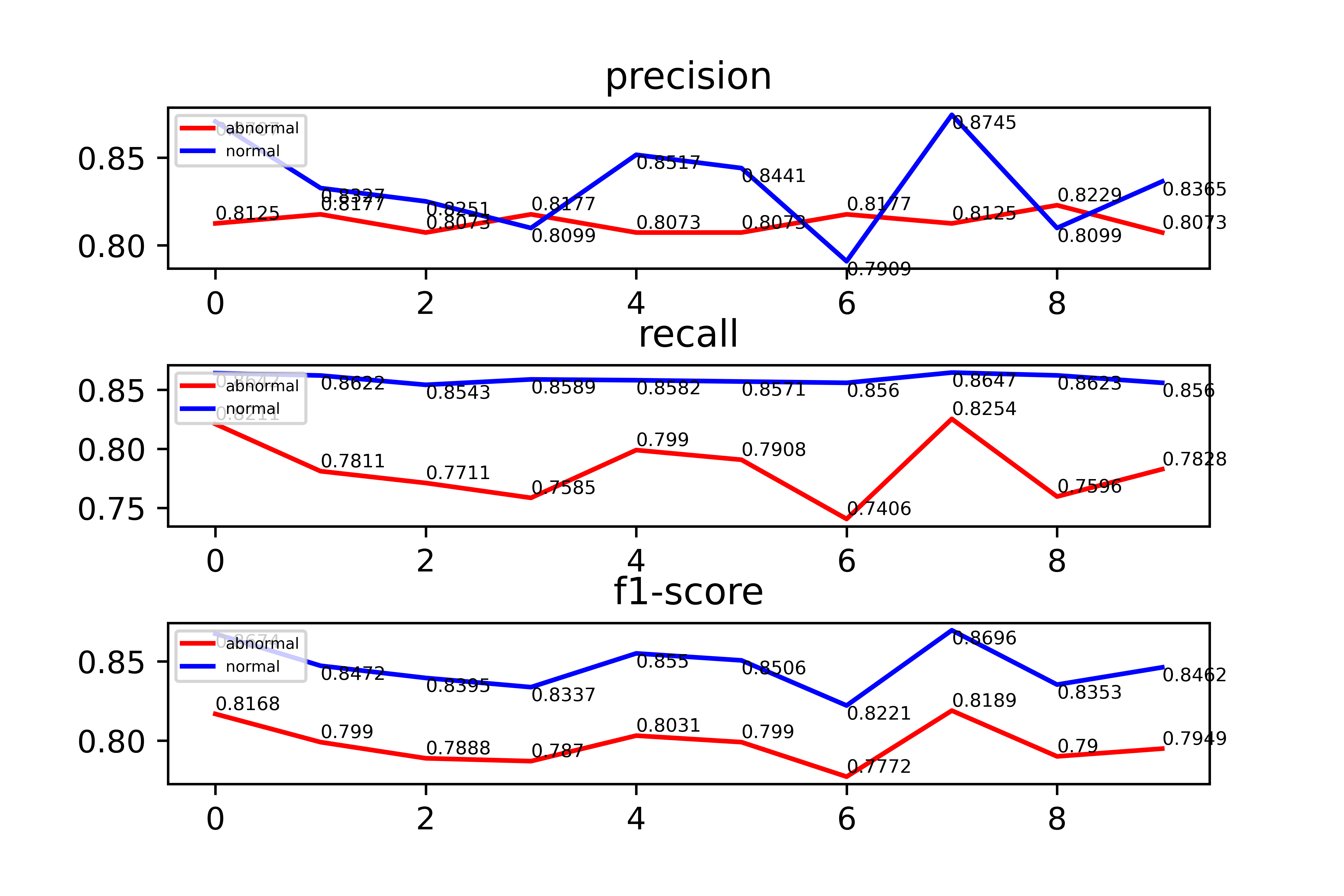
plt 画图
import matplotlib.pyplot as plt
x = [i for i in range(10)]
plt.subplot(3,1,1)
l1 = plt.plot(x,p1,'r',label = 'abnormal')
l2 = plt.plot(x,p0,'b',label = 'normal')
plt.title('precision')
for a, b, c in zip(x, p1 ,p0):
plt.text(a, round(b,2), round(b,2) , ha='left', va='bottom', fontsize=6)
plt.text(a, round(c,2), round(c,2) , ha='left', va='top', fontsize=6)
plt.legend(loc = 'upper left',fontsize=5)
plt.subplot(3,1,2)
plt.subplots_adjust(wspace = 0, hspace = 0.6)#调整子图间距
l3 = plt.plot(x,r1,'r',label = 'abnormal')
l4 = plt.plot(x,r0,'b',label = 'normal')
plt.title('recall')
for a, b, c in zip(x, r1 ,r0):
plt.text(a, round(b,2), round(b,2) , ha='left', va='bottom', fontsize=6)
plt.text(a, round(c,2), round(c,2) , ha='left', va='top', fontsize=6)
plt.legend(loc = 'upper left',fontsize=5)
plt.subplot(3,1,3)
plt.subplots_adjust(wspace = 0, hspace = 0.6)#调整子图间距
l5 = plt.plot(x,f1,'r',label = 'abnormal')
l6 = plt.plot(x,f0,'b',label = 'normal')
plt.title('f1-score')
for a, b, c in zip(x, f1 ,f0):
plt.text(a, round(b,2), round(b,2) , ha='left', va='bottom', fontsize=6)
plt.text(a, round(c,2), round(c,2) , ha='left', va='top', fontsize=6)
plt.legend(loc = 'upper left',fontsize=5)
plt.savefig('model/eval.png',dpi= 800)
plt.show()
NER实体解析代码(简约版)
# 从预测的标签列表中获取实体
def get_entity(sent, tags_list):
entity_dict = defaultdict(list)
i = 0
for char, tag in zip(sent, tags_list):
if 'B-' in tag:
entity = char
j = i+1
entity_type = tag.split('-')[-1]
while j < min(len(sent), len(tags_list)) and 'I-%s' % entity_type in tags_list[j]:
entity += sent[j]
j += 1
entity_dict[entity_type].append(entity)
i += 1
return dict(entity_dict)
# 原文链接:https://blog.csdn.net/weixin_42691585/article/details/107617304
万恶难搞又通用的json文件
import json
def save(dict, path):
if isinstance(dict, str):
dict = eval(dict)
with open(path, 'w', encoding='utf-8') as f:
str_ = json.dumps(dict, ensure_ascii=False) # TODO:dumps 使用单引号''的dict ——> 单引号''变双引号"" + dict变str
f.write(str_)
def load(path):
with open(path, 'r', encoding='utf-8') as f:
data = f.readline().strip()
print(type(data), data)
dict = json.loads(data)
return dict
http请求
class Client():
def __init__(self):
self.api = 'http://qa-dig-prophet.tongdao.cn/v1/models/jd_parse_v2_20211009/versions/3:predict'
def search(self, input_token, input_segment):
params = {
'Input-Token': input_token,
'Input-Segment': input_segment
}
params = {'instances':[params]}
params = json.dumps(params)
scores = requests.post(self.api, data=params, headers={'Content-Type': 'application/json; charset=utf-8'})
print(scores.text)
scores = eval(scores.text)['predictions']
spark 处理本地数据
from pyspark.sql import SparkSession
from pyspark.sql import Row
spark = SparkSession.builder
.enableHiveSupport()
.appName('YiSan')
.master('yarn')
.config('spark.sql.execution.arrow.enable', 'true')
.config('spark.sql.shuffle.partitions', 300)
.config('spark.driver.memory','30g')\
.config('spark.driver.maxResultSize','30g') \
.config('spark.sql.execution.arrow.enabled','true') \
.config("spark.sql.execution.arrow.pyspark.enabled", "true")\
.getOrCreate()
sc = spark.sparkContext
# 本地数据创建一个可以并行操作的分布式数据集
rdd = sc.parallelize(local_data) # local_data = []
def Jaccard_sim(a,b):
unions = len(set(a).union(set(b)))
intersections = len(set(a).intersection(set(b)))
return 1. * intersections / unions
def partition_func(partition):
for i in partition:
for j in local_other: # local_other = []
if i != j and Jaccard_sim(i,j) >= 0.9:
yield [i, j]
# papPartitions进行RDD转换
rdd1 = rdd.mapPartitions(partition_func)
local_Jaccard = rdd.collect() # 返回迭代器,循环即可读出
local_other还可以通过广播进行传播,其中的区别在于,广播的话可以缓存在每个节点Executor,这样的好处在于缓解diver的压力,当很多节点向diver要数据的时候会造成很大的压力,广播的话就可以向diver或者Executor申请这个数据。(另一个方面就是节点缓存变得更快了)
本文来自博客园,作者:爱吃帮帮糖,转载请注明原文链接:https://www.cnblogs.com/monkeyT/p/14011046.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号