Tensor Flow基础(2.0)
写在前面:此篇纯属自我记录,参考意义不大。
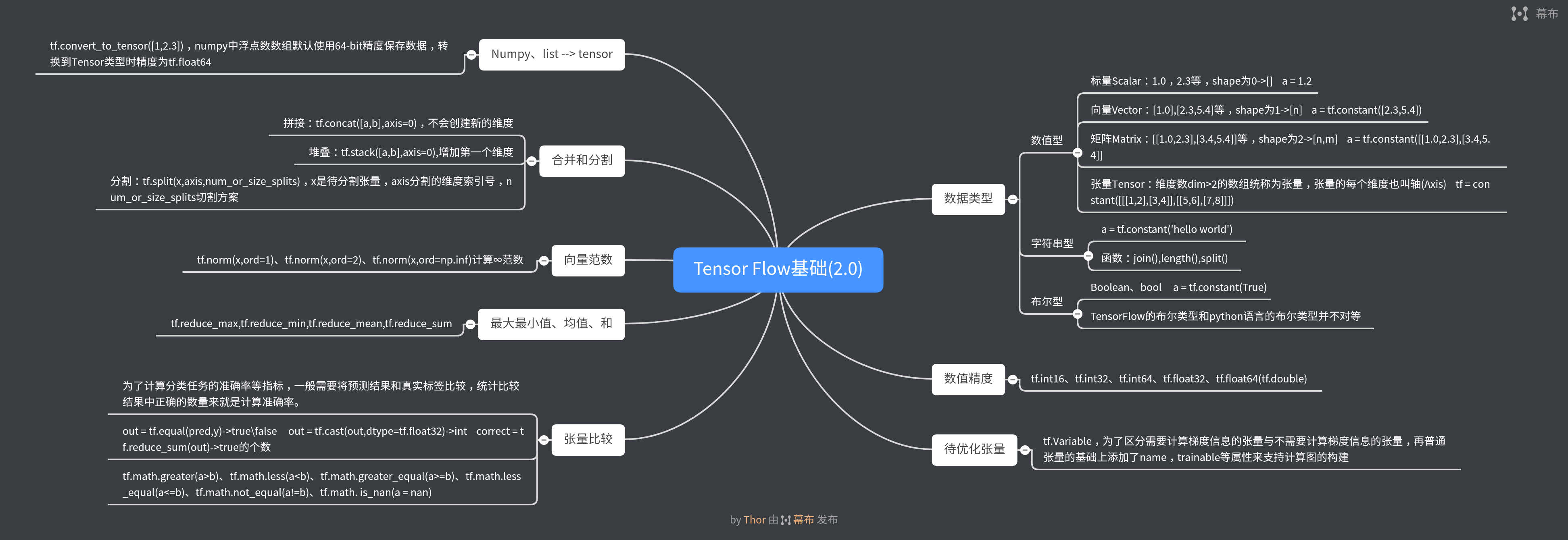
- 数据类型
- 数值型
- 标量Scalar:1.0,2.3等,shape为0->[] a = 1.2
- 向量Vector:[1.0],[2.3,5.4]等,shape为1->[n] a = tf.constant([2.3,5.4])
- 矩阵Matrix:[[1.0,2.3],[3.4,5.4]]等,shape为2->[n,m] a = tf.constant([[1.0,2.3],[3.4,5.4]]
- 张量Tensor:维度数dim>2的数组统称为张量,张量的每个维度也叫轴(Axis) tf = constant([[[1,2],[3,4]],[[5,6],[7,8]]])
- 字符串型
- a = tf.constant('hello world')
- 函数:join(),length(),split()
- 布尔型
- Boolean、bool a = tf.constant(True)
- TensorFlow的布尔类型和python语言的布尔类型并不对等
- 数值型
- 数值精度
- tf.int16、tf.int32、tf.int64、tf.float32、tf.float64(tf.double)
- 待优化张量
- tf.Variable,为了区分需要计算梯度信息的张量与不需要计算梯度信息的张量,再普通张量的基础上添加了name,trainable等属性来支持计算图的构建
- Numpy、list --> tensor
- tf.convert_to_tensor([1,2.3]),numpy中浮点数数组默认使用64-bit精度保存数据,转换到Tensor类型时精度为tf.float64
- 合并和分割
- 拼接:tf.concat([a,b],axis=0),不会创建新的维度
- 堆叠:tf.stack([a,b],axis=0),增加第一个维度
- 分割:tf.split(x,axis,num_or_size_splits),x是待分割张量,axis分割的维度索引号,num_or_size_splits切割方案
- 向量范数
- tf.norm(x,ord=1)、tf.norm(x,ord=2)、tf.norm(x,ord=np.inf)计算∞范数
- 最大最小值、均值、和
- tf.reduce_max,tf.reduce_min,tf.reduce_mean,tf.reduce_sum
- 张量比较
- 为了计算分类任务的准确率等指标,一般需要将预测结果和真实标签比较,统计比较结果中正确的数量来就是计算准确率。
- out = tf.equal(pred,y)->true\false out = tf.cast(out,dtype=tf.float32)->int correct = tf.reduce_sum(out)->true的个数
- tf.math.greater(a>b)、tf.math.less(a<b)、tf.math.greater_equal(a>=b)、tf.math.less_equal(a<=b)、tf.math.not_equal(a!=b)、tf.math. is_nan(a = nan)
本文来自博客园,作者:爱吃帮帮糖,转载请注明原文链接:https://www.cnblogs.com/monkeyT/p/12084822.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号