摘要:
写在前面 该系列主要事对指针网络在NER以及关系抽取系列取得的成果进行展示,并根据大佬们的笔记总结其中的优劣以及理论分析。 GlobalPointer 在之前的工作中,我们NER采用传统的LSTM+CRF,在各个字段指标也取得不错的效果,简单字段类似学历这种f1值均在95以上,复杂一点的比如 阅读全文
posted @ 2022-04-08 16:11
爱吃帮帮糖
阅读(3080)
评论(0)
推荐(1)
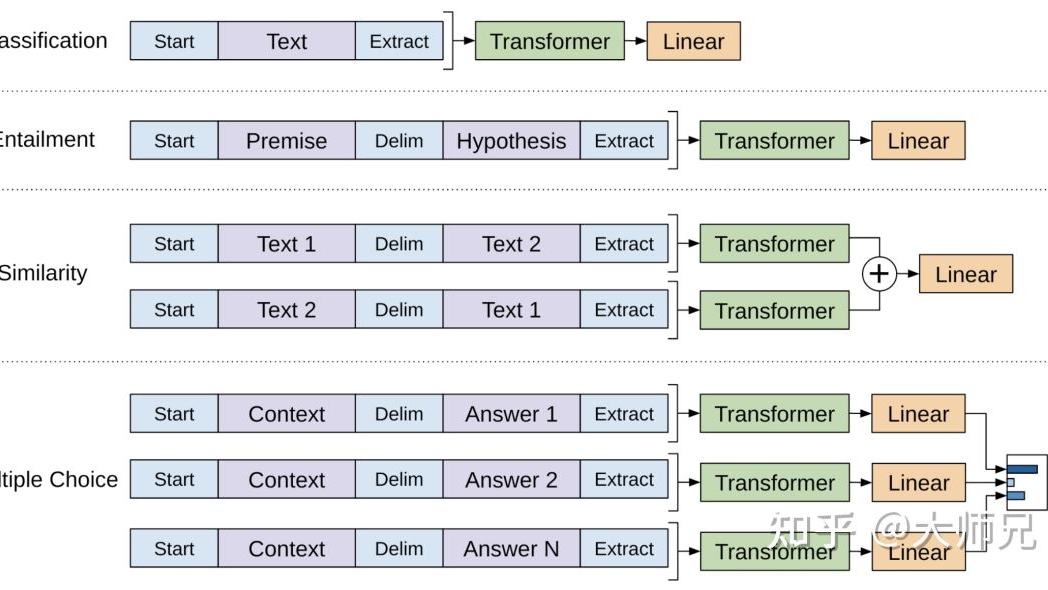 简介 GPT(Generative Pre-trained Transformer)系列是由OpenAI提出的非常强大的预训练语言模型,这一系列的模型可以在生成式任务中取得非常好的效果,对于一个新的任务,GTP只需要很少的数据便可以理解任务的需求并达到或接近state-of-the-art的方法 阅读全文
简介 GPT(Generative Pre-trained Transformer)系列是由OpenAI提出的非常强大的预训练语言模型,这一系列的模型可以在生成式任务中取得非常好的效果,对于一个新的任务,GTP只需要很少的数据便可以理解任务的需求并达到或接近state-of-the-art的方法 阅读全文
 浙公网安备 33010602011771号
浙公网安备 33010602011771号