操作系统(上)
三部:操作系统(上):硬件结构;操作系统概述 操作系统(中):内存管理;进程管理 操作系统(下):文件系统;IO管理;调度算法
硬件结构
1.CPU是如何执行程序的?
前提知识:
- 冯诺依曼模型:CPU,内存,输入设备,输出设备,总线。(也可分为:控制器,计算器,存储器,IO)
- CPU
- 寄存器:通用寄存器(运算中间结果),程序计数器(下一条指令的地址),指令寄存器(存放指令)
- 控制器
- 运算器
- 总线
- 地址总线:用于指定CPU将要操作的内存地址
- 数据总线:用于读写内存中的数据
- 控制总线:发送和接收信号:比如中断,设备复位等
- 位宽
- 线路位宽:其实总线传输的是电压,比如高压代表1,低压代表0 。一次只传输一个比特,效率太低,就需要把好多线"捆"在一起,一起传输,增加效率。
- CPU位宽:一次读取数据的大小。这个数据就是比特,就是读取总线传过来的数据
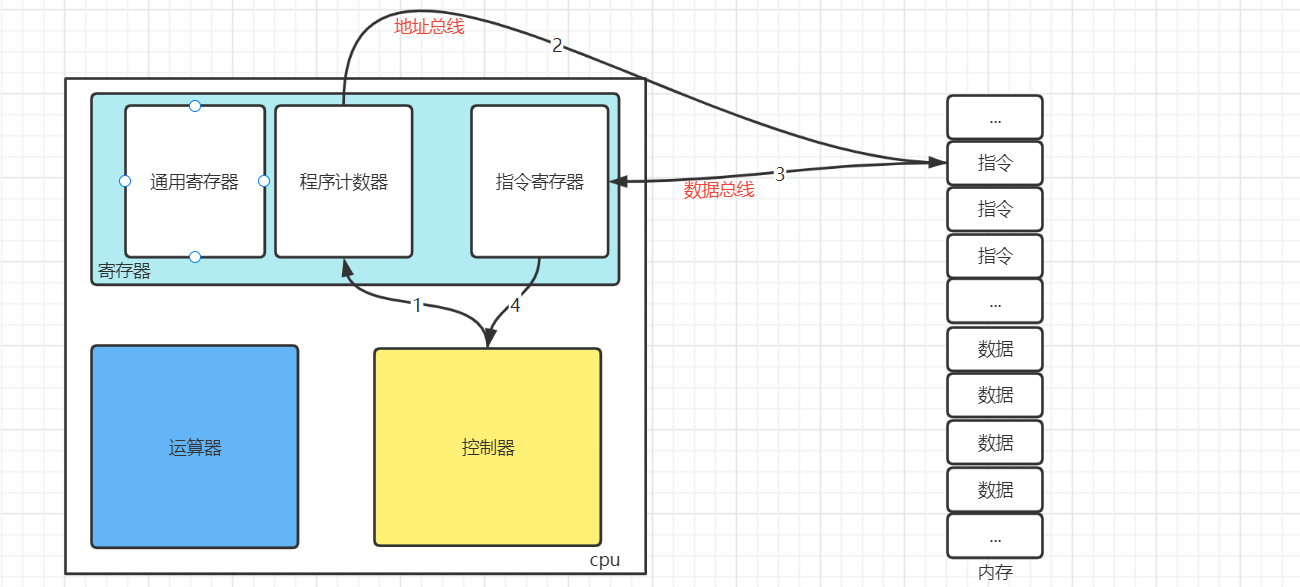
- 我们写的程序经过编译器编译成机器指令,生成一个可执行文件(.exe)。当用户点击可执行文件的时候,将指令和数据加载到内存中。
- 控制器通过程序计数器读取到下一条指令的地址,控制器就通过地址总线找到需要访问的内存空间,将内存空间的指令通过数据总线放入指令寄存器中。
- 控制器再分析指令寄存器的指令。如果是计算类型的指令,就交给运算器;如果只存储类型的指令,就交给控制器。
- 控制器执行完指令之后,程序计数器进行自增,指向下一条指令。这个自增的大小,取决于CPU的位数,比如CPU是32位,就自增4。 以上这个步骤不断循环,叫做CPU 的指令周期。
2. 64 位相⽐ 32 位 CPU 的优势在哪吗?64 位 CPU 的计算性能⼀定⽐ 32 位 CPU ⾼很多吗?
你知道软件的 32 位和 64 位之间的区别吗?再来 32 位的操作系统可以运⾏在 64 位的电脑上吗?
64 位的操 作系统可以运⾏在 32 位的电脑上吗?如果不⾏,原因是什么?
- 所有的数据都转换为2进制,CPU的位是指一次读取数据的大小。比如一个非常大的数的二进制大于32位,32位的cpu就不能一次读取完毕,就得进行多次的读取。但是我们开发中很少用到那么大的数据,所以只有运算大数字 的时候,64 位 CPU 的优势才能体现出来,否则和 32 位 CPU 的计算性能相差不大。
- 硬件的位数指"CPU的位宽",软件的位数指“指令的位宽”。如果 32 位指令在 64 位机器上执行,需要⼀套兼容机制,就可以做到兼容运行了。但是如果 64 位指令在 32 位机器上执行,就比较困难了,因为 32 位的寄存器存不下 64 位的指令。操作系统也是一种软件,所以不可以运行在32位的机器上。
3.你知道存储器的层次关系吗?(机械硬盘、固态硬盘、内存这三个存储器,到底和 CPU L1 Cache 相比速度差多少倍呢?)
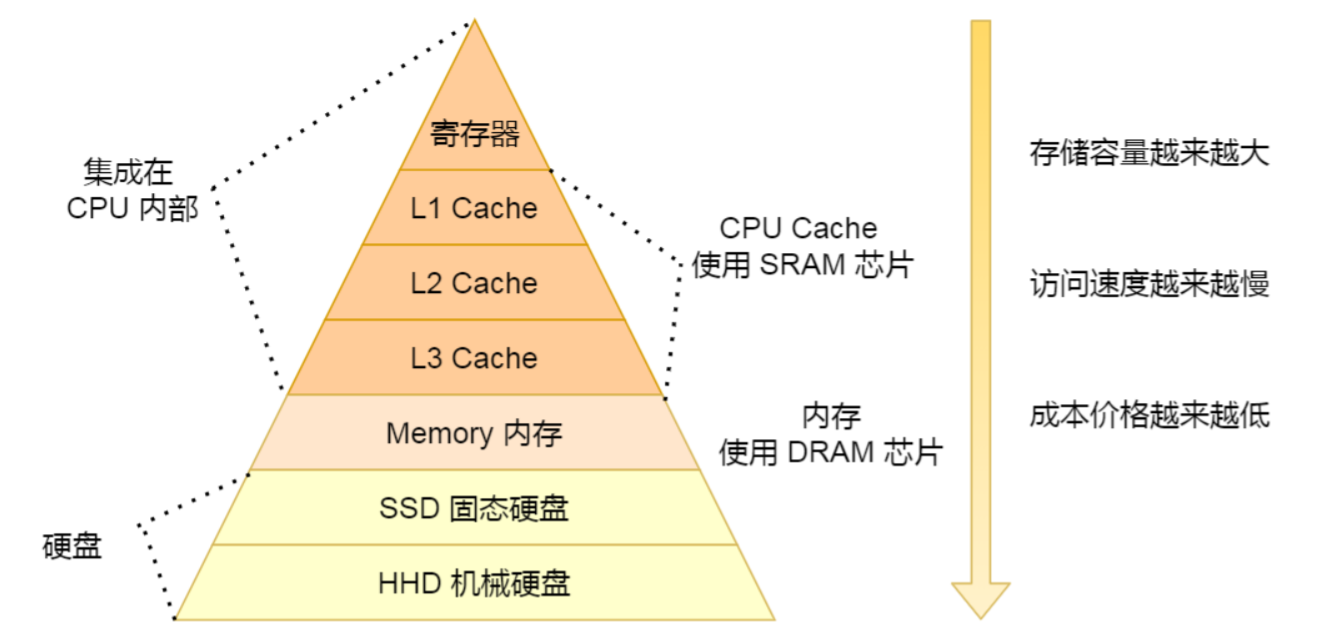
- CPU L1 Cache的速度:1纳秒
- 内存的速度: 100 纳秒
- SSD固态硬盘的速度:150 微妙
- HHD机械硬盘:10毫秒
4.如何写出让 CPU 跑得更快的代码?
- 随着科技的发展,CPU与内存的速度相差越来越大。这时候就加入CPU Cache进行缓存。如果cpu每次都可以命中缓存,那么它就会更快。
- CPU L1 Cache 分为数据缓存和指令缓存,因⽽需要分别提⾼它们的缓存命中率。
- 对于数据缓存,我们在遍历数据的时候,应该按照内存布局的顺序操作,这是因为 CPU Cache 是根据 CPU Cache Line 批量操作数据的,所以顺序地操作连续内存数据时,性能能得到有效的提升;
- 对于指令缓存,有规律的条件分支语句能够让 CPU 的分支预测器发挥作用,进⼀步提高执行的效率;
- 解释一下上面的CPU Cache Line 批量操作数据:
- 内存地址映射到 CPU Cache 地址里的策略有很多种,其中比较简单是直接映射 Cache,它巧妙的把内存地址拆分成「索引 + 组标记 + 偏移量」的⽅式,使得我们可以将很⼤的内存地址,映射到很小的 CPU Cache 地址里。
- 简单的说,就是每次Cache读取内存数据是按照一行一行读。
5.CPU缓存一致性?
cpu缓存就相当于我们使用的redis,现在如何保证数据更新,缓存也更新?而且cpu Cache还存在多核访问的情况,还得保证多核一致性(并发问题)?
通过以下方式保证写时一致:
- 写直达:将数据写入CPU Cache中和内存中。这种方式简单直观,但是多次和内存交互就会使得性能下降。
- 写回:先判断缓存是否命中,没有命中直接写入内存。命中的数据只需要更新Cache中的数据就行,不需要写入内存中。会在更新Cache数据后,将这个数据标记为脏数据,只有脏数据被替换时,才需要写入内存中。尽可能减少写入内存的操作。
如下图展示了CPU多核的模型
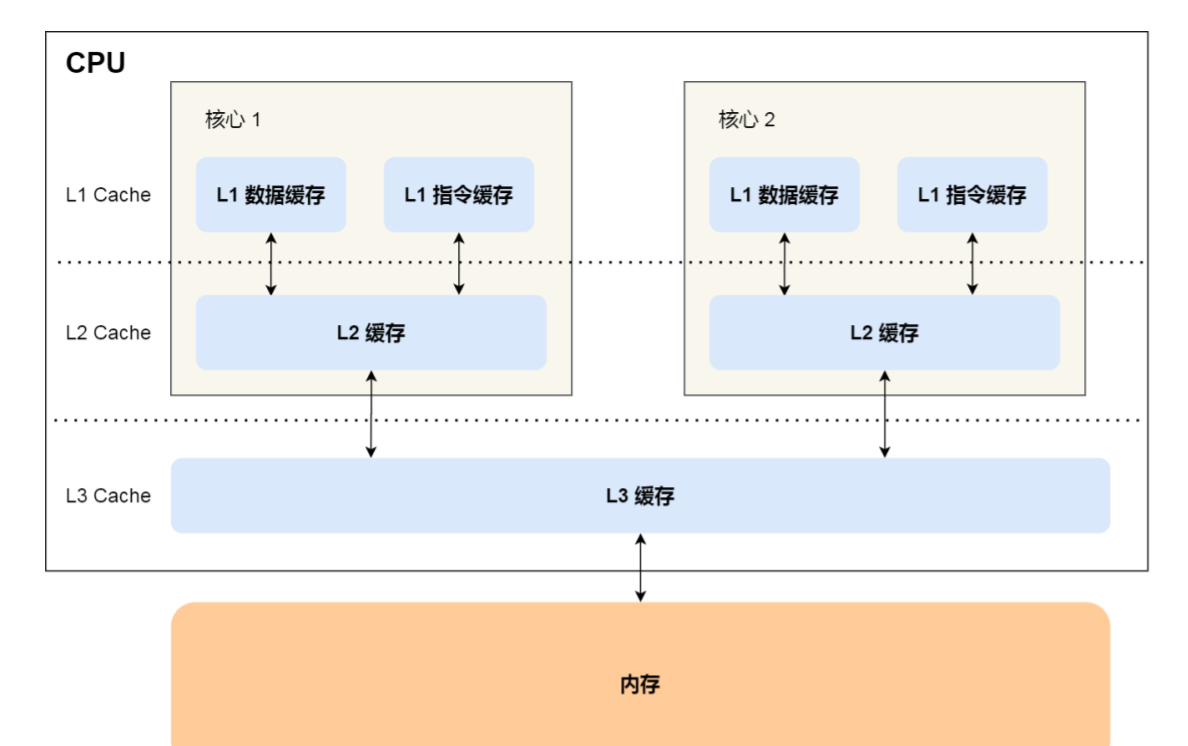
问题:核心1更新L3 Cache后,就需要通过一定的技术告诉核心2。
- 写传播:也就是当某个 CPU 核心发生写入操作时,需要把该事件广播通知给其他核心;通过总线嗅探技术。
- 事务串行化:保证了事务串行化才能保证数据的一致性;通过MESI协议(基于总线嗅探机制的 MESI 协议)。
- Modified:已修改
- Exclusive:独占
- Shared:共享
- Invalidated:已失效
- MESI规定了以上的四种状态,整个 MSI 状态的变更,则是根据来自本地 CPU 核心的请求,或者来自其他 CPU 核心通过总线传输过来的请求,从而构成⼀个流动的状态机。比如:A核心写入自己Cache一个数据,数据开始状态为【独占】,把数据放入L3 Cache后,数据状态变为【共享】。此时B核心就能读取这个数据,当A核心需要修改该数据时,就发出一个广播,让B核心内的数据变为【无效】。当修改完之后,数据变为【已修改】,就会通过总线嗅探把该数据重新发送给B核心。
6.伪共享问题?
伪共享:不需要共享的数据也被共享了。
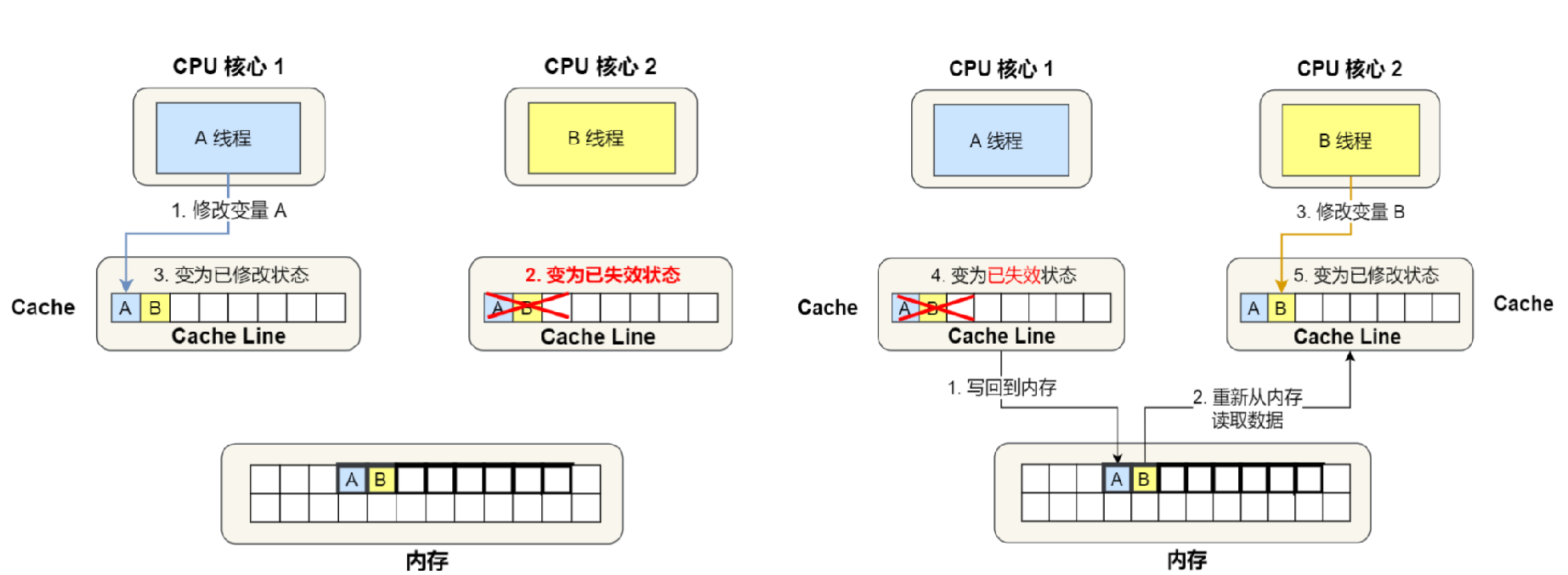
如图:
- A核心操作数字A,B核心操作数字B。但是由于AB数据在同一行,我们知道Cache读取内存数据是一行一行来的。
- 所以修改A 的时候本应该B不用标记为失效。同理,修改B的时候A也不用标记为失效。而这样反反复复失效的情况就成为伪数据。
如何避免伪数据?就是让AB数据不要在同一行
- Cache Line 大小字节对齐
- 字节填充法
7.什么是软中断?
操作系统收到了中断请求,会打断其他进程的运行,所以中断请求的响应程序,也就是中断处理程序,要尽可能快的执行完,这样可以减少对正常进程运行调度地影响。
因为执行中断程序过长,万一有新的中断,就来不及处理。所以为了尽可能快的处理中断,把一次中断分为两个阶段。
- 上半部,对应硬中断,由硬件触发中断,用来快速处理中断;
- 下半部,对应软中断,由内核触发中断,用来异步处理上半部未完成的工作;Linux 中的软中断包括网络收发、定时、调度、RCU 锁等各种类型。
操作系统概述
1.解释一下什么是操作系统?
控制和管理整个计算机系统的"硬件资源"和"软件资源"。
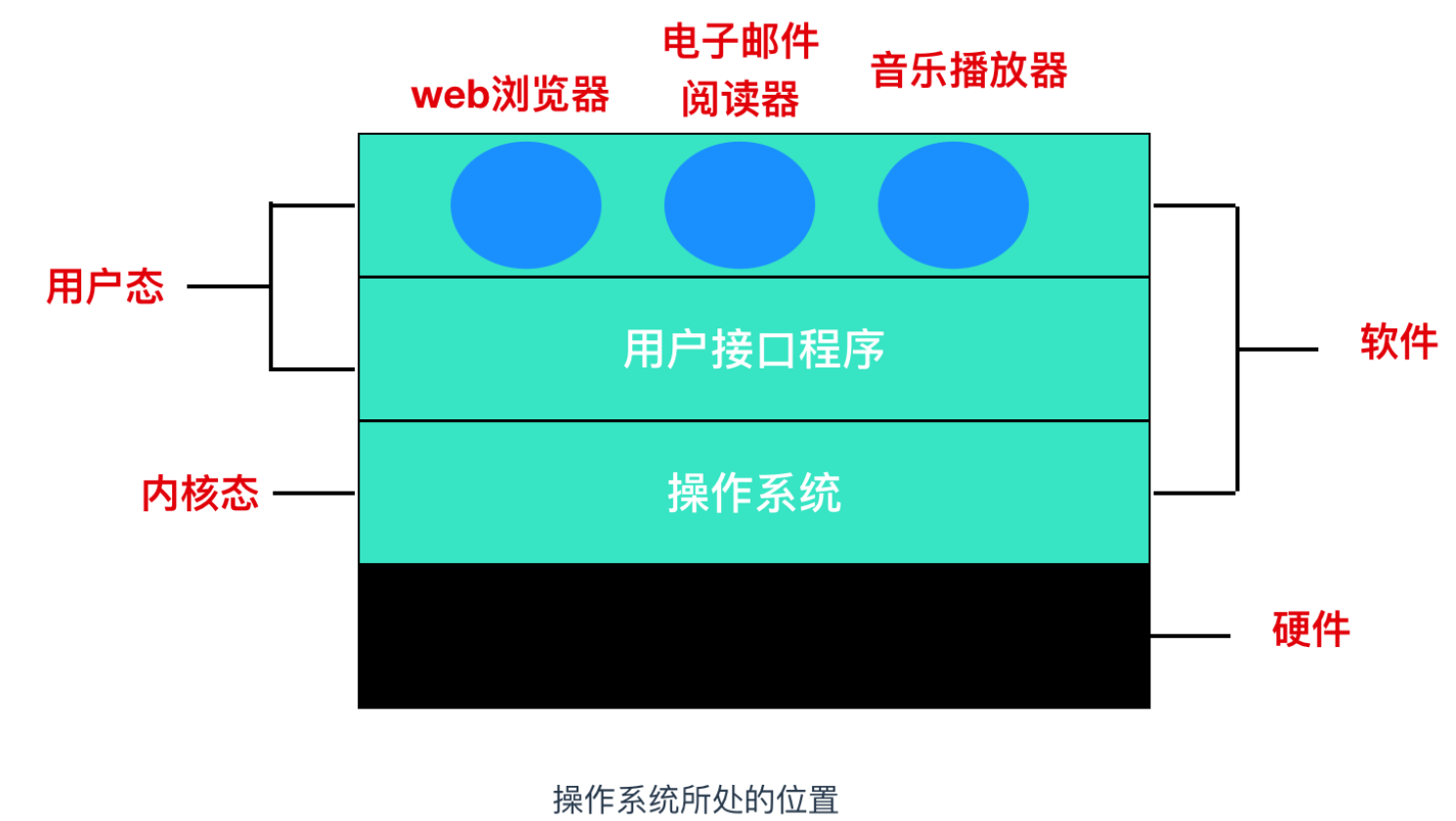
2.操作系统的主要功能
- 内存管理,进程管理,文件系统管理,IO管理(设备管理)
3.为什么 Linux 系统下的应用程序不能直接在 Windows 下运行
- Linux 系统和 Windows 系统的格式不同,格式就是协议。
- Linux 下的可执行程序文件格式是 elf
。 - Windows下的可执行程序是 PE 格式,它是一种可移植的可执行文件。
- Linux 下的可执行程序文件格式是 elf
- Linux 系统和 Windows 系统的
API不同。- Linux 中的 API 被称成系统调用,是通过
int 0x80这个软中断实现的。 - Windows 中的 API 是放在动态链接库文件(DLL)中的,里面包含代码和数据。
- Linux 中的 API 被称成系统调用,是通过
4.操作系统结构
更新中~
5.什么是内核?什么是用户态和内核态
- 内核:内核是一个计算机程序,它是操作系统的核心,可以控制操作系统中所有的内容。内核通常是在 boot loader 装载程序之前加载的第一个程序。
- boot loader 又被称为引导加载程序,它是一个程序,能够将计算机的操作系统放入内存中。
- 在电源通电或者计算机重启时,BIOS(基本输入输出设备)会执行一些初始测试,然后将控制权转移到引导加载程序所在的主引导记录(MBR)。
- 内核空间:这个内存空间只有内核程序可以访问;具有最高权限,可以直接访问所有资源;程序使用内核空间时,称为内核态。
- 用户空间:这个内存空间专门给应用程序使用;只能访问受限资源,不能直接访问内存等硬件设备,必须通过系统调用陷入到内核中,才能访问这些特权资源。程序使用用户空间时,称为用户态。
- 那么为什么要有用户态和内核态呢?
- 这个主要是访问能力的限制的考量,计算机中有一些比较危险的操作,比如设置时钟、内存清理,这些都需要在内核态下完成。
- 如果随意进行这些操作,那你的系统得崩溃多少次。
6.内核的架构
- 宏内核:整个内核像⼀个完整的程序,包含进程管理,内存管理,文件系统管理,设备驱动等。(linux)
- 微内核:有⼀个最⼩版本的内核,⼀些模块和服务则由用户态管理。比如文件管理,设备驱动就在 用户态。这就有一个问题,用户态就需要频繁的切换到内核态操作底层,消耗资源。(鸿蒙系统)
- 混合内核:有一个最小版本的内核,但是整个内核中也有整个模块,相当于宏内核和微内核结合。(windows)
7.用户态和内核态是如何切换的?
有一些操作,必须在内核态才能完成,比如读取硬盘数据,读取键盘的数据。但是用户态的程序有时候需要这些操作,所以必须进行转化:用户态->内核态->用户态
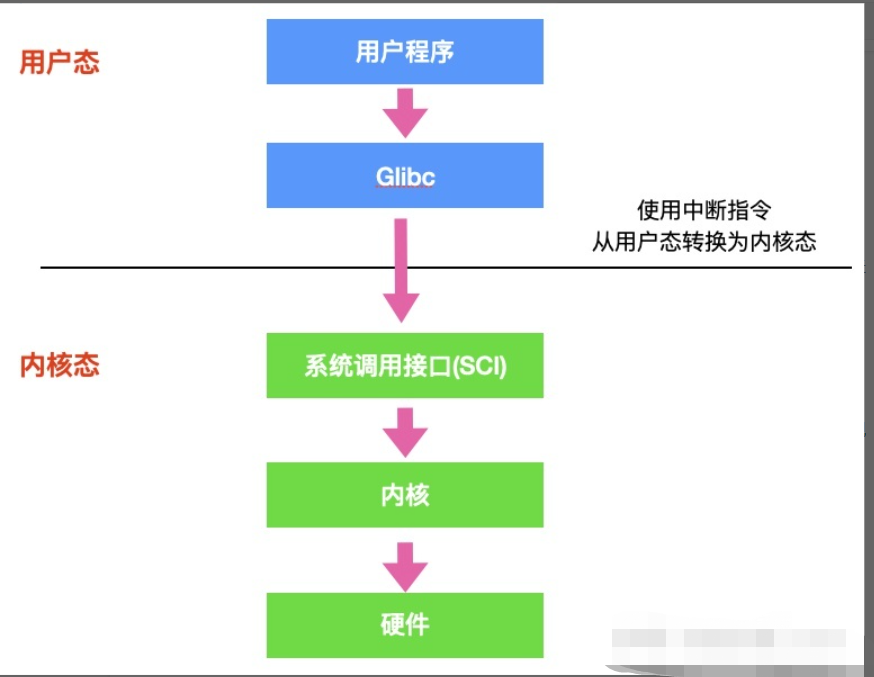
- 首先用户程序会调用
glibc库,glibc 是一个标准库,同时也是一套核心库,库中定义了很多关键 API。 - glibc 库知道针对不同体系结构调用
系统调用的正确方法,它会根据体系结构应用程序的二进制接口设置用户进程传递的参数,来准备系统调用。 - 然后,glibc 库调用
软件中断指令(SWI),这个指令通过更新CPSR寄存器将模式改为超级用户模式,然后跳转到地址0x08处。 - 到目前为止,整个过程仍处于用户态下,在执行 SWI 指令后,允许进程执行内核代码,MMU 现在允许内核虚拟内存访问
- 从地址 0x08 开始,进程执行加载并跳转到中断处理程序,这个程序就是 ARM 中的
vector_swi()。 - 在 vector_swi() 处,从 SWI 指令中提取系统调用号 SCNO,然后使用 SCNO 作为系统调用表
sys_call_table的索引,调转到系统调用函数。 - 执行系统调用完成后,将还原用户模式寄存器,然后再以用户模式执行。
8.什么是实时系统?
实时操作系统对时间做出了严格的要求,实时操作系统分为两种:硬实时和软实时
- 硬实时:规定某个动作必须在规定的时刻内完成或发生,否则会产生永久性伤害。
- 软实时:虽然不希望偶尔违反最终的时限要求,但是仍然可以接受。并且不会引起任何永久性伤害。
9.Linux 操作系统的启动过程
更新中~

