
算法模板
数据结构
并查集
-
查询两点是否在同一集合内
struct DSU { std::vector<int> f, siz; DSU(){} DSU(int n) { init(n); } void init(int n) { f.resize(n); iota(f.begin(), f.end(), 0); siz.assign(n, 1); } int find(int x) { while (x != f[x]) { x = f[x] = f[f[x]]; } return x; } bool same(int x, int y) { return find(x) == find(y); } bool merge(int x, int y) { x = find(x); y = find(y); if (x == y) return false; siz[x] += siz[y]; f[y] = x; return true; } int size(int x) { return siz[find(x)]; } }; -
并查集判断环的个数
inline void solve() { int n, m; cin >> n >> m; DSU dsu(n + 1); int ans = 0; for (int i = 0; i < m; i++) { int a, b; cin >> a >> b; if (!dsu.merge(a, b)) ans++; // 如果是有向图则判断find(u) == v, 不成环就merge(v, u) } cout << ans << endl; }
笛卡尔树
定义:给你一个数组a[i],每次以最值为根构建二叉树,左右子树分别是左右最值。
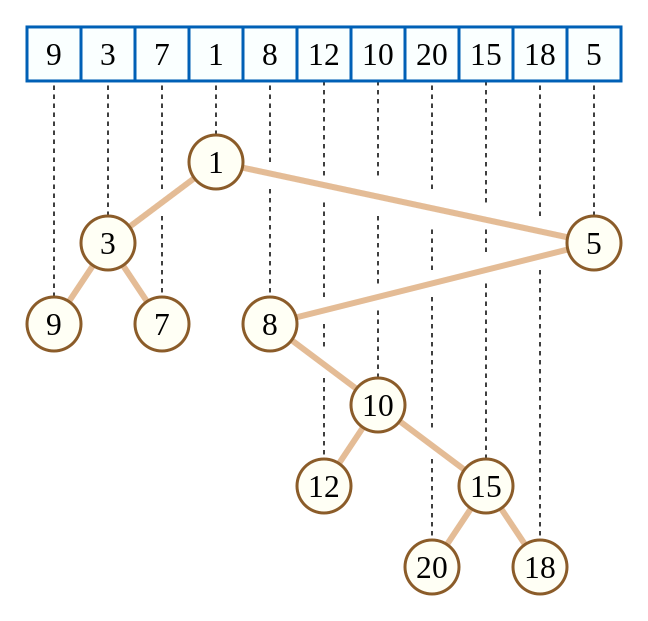
上图就是利用最小值构建的笛卡尔树。
性质
- 区间最值(RMQ)是端点的LCA
- 对于节点
x他的父亲是左边或者右边第一个小于他的(可以简单推一下)
构建笛卡尔树
通过手动模拟建树的过程,我们可以发现每往树里面添加一个元素x,如果大于之前的元素那么就直接接在右边整棵树不需要发现改变,但是如果小于的话,就需要向上找到合适的位置插入,并将之前的子树作为x的左子树
template<class T>
struct CartesianTree{
std::vector<int> l, r;
int n, root;
CartesianTree(){}
CartesianTree(int size)
{
root = 0;
n = size;
l.resize(size + 1);
r.resize(size + 1);
}
void build()
{
stack<int> st;
for (int i = 1; i <= n; i++)
{
int last = 0;
while (!st.empty() && a[i] < a[st.top()])
{
last = st.top();
st.pop();
}
if (!st.empty()) r[st.top()] = i;
else root = i;
l[i] = last;
st.push(i);
}
}
};
根号分治
根号分治其实是:把问题分为两个部分,取一个值 x,当操作的次数
Eg: 例题
如果暴力枚举的话,复杂度和模数p成反比,但是如果全都预处理出来数组又开不了那么大,所以选择根号以下的预处理,根号以上的暴力.
这样总的复杂度为O(n *
const int M = 500;
LL ans[M + 5][M + 5]; // 第i个数mod p 余数为j的所有数之和
inline void solve()
{
int n, q; cin >> n >> q;
std::vector<LL> a(n + 1);
for (int i = 1; i <= n; i++)
cin >> a[i];
for (int i = 1; i <= n; i++) // 先预处理出来根号级别的答案,只能O(1)出根号以内的
for (int p = 1; p <= M; p++)
ans[p][i % p] += a[i];
while (q--)
{
char op;
int x, y;
cin >> op >> x >> y;
if (op == 'A')
{
if (x <= M) cout << ans[x][y] << endl;
else
{
LL ans = 0;
for (int i = y; i <= n; i += x)
ans += a[i];
cout << ans << endl;
}
}
else
{
for (int i = 1; i <= M; i++) // 不能单纯修改
ans[i][x % i] = ans[i][x % i] - a[x] + y;
a[x] = y;
}
}
}
Eg:
给你一张无向图,每个节点的颜色刚开始都是白色,你需要处理q次操作
1. 将节点x的颜色反转,白变黑,黑变白
1. 查询节点x周围有多少个黑点
这题如果暴力预处理的话可以做到
如果一个点的度数大于T我们就直接查询,小于就暴力查询,这样可以优化到
inline void solve()
{
int n, m, q; cin >> n >> m >> q;
std::vector<std::vector<int>> adj(n + 1), bige(n + 1);
std::vector<int> col(n + 1), big(n + 1);
std::vector<int> ans(n + 1);
for (int i = 0; i < m; i++)
{
int u, v; cin >> u >> v;
adj[u].pb(v);
adj[v].pb(u);
}
int M = int(sqrt(m));
for (int i = 1; i <= n; i++) // 判断哪些点是大点
big[i] = adj[i].size() >= M;
for (int i = 1; i <= n; i++) // 周围哪些点是大点
for (auto v : adj[i])
if (big[v]) bige[i].pb(v);
while (q--)
{
int op, x; cin >> op >> x;
if (op == 1)
{
col[x] ^= 1;
for (auto v : bige[x])
{
if (col[x]) ans[v]++;
else ans[v]--;
}
}
else
{
if (big[x]) cout << ans[x] << endl;
else
{
LL cnt = 0;
for (auto v : adj[x])
cnt += col[v];
cout << cnt << endl;
}
}
}
}
当步长很大的时候其实需要计算的项数并不多直接暴力就行,但是步长小的时候项数太多暴力超时,所以我们需要预处理一部分的答案。我们先根据题意定义一个数组f,f[i][j]就表示步长为i,当前下标为j时的答案。sum[i][j]为不带系数的前缀和。
inline void solve()
{
int n, q; cin >> n >> q;
std::vector<LL> a(n + 1);
for (int i = 1; i <= n; i++) cin >> a[i];
int M = sqrt(n);
vector<vector<LL>> f(M + 1, vector<LL>(n + 1)), sum(M + 1, vector<LL>(n + 1));
for (int i = 1; i <= M; i++)
for (int j = 1; j <= n; j++)
{
f[i][j] = (j - i >= 1 ? f[i][j - i] : 0) + a[j] * (j / i);
sum[i][j] = (j - i >= 1 ? sum[i][j - i] : 0) + a[j];
}
while (q--)
{
LL s, d, k; cin >> s >> d >> k;
LL ans = 0;
if (d > M)
{
for (int i = s, t = 1; i <= n && t <= k; i += d, t++)
ans += a[i] * t;
}
else
{
ans = f[d][s + (k - 1) * d] - (s - d >= 1 ? f[d][s - d] : 0);
ans -= (s / d - 1) * (sum[d][s + (k - 1) * d] - (s - d >= 1 ? sum[d][s - d] : 0));
}
cout << ans << " \n"[q == 0];
}
}
莫队
如果区间[l, r] 可以
Eg:例题
首先这个问题是符合上述条件的,因为扩展到相邻区间只需要cnt[c]++就可以了。如果我们已知区间[l, r]的中颜色c的贡献为sum
那么加一个c,贡献就会更新为sum = cnt[c] + sum, 减一个c,贡献就会更新为sum = sum - (cnt[c] - 1)。
inline void solve()
{
int N, M; cin >> N >> M;
int B = 500;
std::vector<LL> a(N + 1), ans(M), ans2(M);
vector<array<int, 3>> ask(M);
for (int i = 1; i <= N; i++)
cin >> a[i];
for (int i = 0; i < M; i++)
{
int l, r; cin >> l >> r;
ask[i] = {l, r, i};
ans2[i] = 1LL * (r - l) * (r - l + 1) / 2;
}
sort(ask.begin(), ask.end(), [&](array<int, 3> a, array<int, 3> b)
{
if (a[0] / B != b[0] / B) return a[0] / B < b[0] / B;
else return a[1] < b[1];
});
vector<int> cnt(N + 1);
auto add = [&](int x)
{
res += cnt[a[x]];
cnt[a[x]]++;
};
auto del = [&](int x)
{
cnt[a[x]]--;
res -= cnt[a[x]];
};
int l = 1, r = 0; // 因为是闭区间,如果都初始化为1会出现矛盾,主要还是和add()和del()有关
LL res = 0; // 最开始没有询问,答案为0
for (int i = 0; i < M; i++)
{
while (r < ask[i][1]) r++, add(r);
while (l > ask[i][0]) l--, add(l);
while (l < ask[i][0]) del(l), l++;
while (r > ask[i][1]) del(r), r--;
ans[ask[i][2]] = res;
}
for (int i = 0; i < M; i++)
{
LL d = __gcd(ans[i], ans2[i]);
if (d == 0) printf("0/1\n");
else printf("%lld/%lld\n", ans[i] / d, ans2[i] / d);
}
}
Eg:蓝桥杯真题
其实和上面那题差不多,只需要额外维护一个res数组就行了
inline void solve()
{
int n; cin >> n;
int B = 500;
std::vector<int> a(n + 1);
for (int i = 1; i <= n; i++)
cin >> a[i];
int q; cin >> q;
std::vector<array<int, 4>> ask(q);
vector<int> ans(q);
for (int i = 0; i < q; i++)
{
int l, r, k; cin >> l >> r >> k;
ask[i] = {l, r, k, i};
}
sort(ask.begin(), ask.end(), [&](array<int, 4> a, array<int, 4> b)
{
if (a[0] / B != b[0] / B) return a[0] / B < b[0] / B;
else if (a[0] / B & 1) return a[1] < b[1];
else return a[1] > b[1];
});
vector<int> res(n + 1), cnt(n + 1); // res:出现次数为i的数有多少个,cnt:每个数出现多少次
auto add = [&](int x)
{
res[cnt[a[x]]]--;
cnt[a[x]]++;
res[cnt[a[x]]]++;
};
auto del = [&](int x)
{
res[cnt[a[x]]]--;
cnt[a[x]]--;
res[cnt[a[x]]]++;
};
int l = 1, r = 0;
for (int i = 0; i < q; i++)
{
while (r < ask[i][1]) r++, add(r);
while (l > ask[i][0]) l--, add(l);
while (r > ask[i][1]) del(r), r--;
while (l < ask[i][0]) del(l), l++;
ans[ask[i][3]] = res[ask[i][2]];
}
for (int i = 0; i < q; i++)
cout << ans[i] << endl;
}
扫描线
定义比较抽象,大概就是有一根线,从下到上(反过来也行)扫,边扫边做。这种解题思维就叫扫描线
Eg:园丁的烦恼
给你平面上n个点,一共q个查询,每次查询给一个矩阵的对角点,问这个矩阵能框住几个点?
咋一看感觉就二维前缀和秒了,但是数据给的太大了数组开不了。所以我们假设有根线从y = 0 到 y = inf,一直往上扫
碰见一棵树就cnt[x]++,碰见需要查询的点就查一下前面有多少个点小于他直接上树状数组(Binary Index Tree)
inline void solve()
{
int n, m; cin >> n >> m;
vector<array<int, 4>> event; // y坐标,类型,x坐标
vector<int> vx;
for (int i = 0; i < n; i++)
{
int x, y; cin >> x >> y;
vx.pb(x);
event.pb({y, 0, x}); // 0 表示是一棵树
}
for (int i = 1; i <= m; i++)
{
int a, b, c, d;
cin >> a >> b >> c >> d;
// (c, d) - (a - 1, d) - (c, b - 1) + (a - 1, b - 1)
event.pb({d, 1, c, i}); // 1 表示在 i 这个询问中 需要加这段和
event.pb({d, 2, a - 1, i}); // 2 表示在 i 这个询问中 需要减这段和
event.pb({b - 1, 2, c, i});
event.pb({b - 1, 1, a - 1, i});
}
sort(event.begin(), event.end()); // 按y轴排序
sort(vx.begin(), vx.end());
vx.erase(unique(vx.begin(), vx.end()), vx.end()); // 离散化
BIT<int> bit(vx.size());
vector<int> ans(m + 1);
for (auto evt : event)
{
if (evt[1] == 0)
{
int x = lower_bound(vx.begin(), vx.end(), evt[2]) - vx.begin() + 1; // 找到第一个大于等于x的数的坐标
bit.modify(x, 1);
}
else
{
int x = upper_bound(vx.begin(), vx.end(), evt[2]) - vx.begin() + 1; // 找到第一个大于x的数的坐标
int tmp = bit.query(x - 1); // 求和是闭区间,所以要减一
if (evt[1] == 1) ans[evt[3]] += tmp;
else ans[evt[3]] -= tmp;
}
}
for (int i = 1; i <= m; i++)
cout << ans[i] << endl;
}
Eg:矩形面积并
其实就是从下往上扫,每到一条横边就计算一下面积 Area += (now - last) * Len,关键就在于怎么计算横边的长度,利用线段树的想法,每次碰见一条横边就让这个区间加一,那么整个区间的非零个数就是被覆盖的长度,但是这样会重复计算,所以定义一个矩形下边为加一,上边为减一。这就就不会重复计算了。但是我们不能直接把x[i]当成端点存下去,比如对于区间[1, 3]来说在线段树里存是{[1, 2],[3, 3]},但实际上应该是{[1, 2],[2, 3]},所以我们要把端点映射成线段
std::vector<int> vx;
vector<array<int, 4>> event;
template<class T>
struct SegmentTree{
struct info{
int minn, minncnt;
int tag;
};
vector<info> seg;
int n;
SegmentTree(){}
SegmentTree(int size)
{
seg.resize(4 * size);
n = size;
}
void update(int id)
{
seg[id].minn = min(seg[id * 2].minn, seg[id * 2 + 1].minn);
if (seg[id * 2].minn == seg[id * 2 + 1].minn) seg[id].minncnt = seg[id * 2].minncnt + seg[id * 2 + 1].minncnt;
else if (seg[id * 2].minn < seg[id * 2 + 1].minn) seg[id].minncnt = seg[id * 2].minncnt;
else seg[id].minncnt = seg[id * 2 + 1].minncnt;
}
void settag(int id, int t)
{
seg[id].minn = seg[id].minn + t;
seg[id].tag = seg[id].tag + t;
}
void pushdown(int id)
{
if (seg[id].tag != 0)
{
settag(id * 2, seg[id].tag);
settag(id * 2 + 1, seg[id].tag);
seg[id].tag = 0;
}
}
void build(int id, int l, int r) // 建树
{
if (l == r)
{
seg[id].minn = 0;
seg[id].minncnt = vx[r] - vx[r - 1]; // 重新映射
seg[id].tag = 0;
}
else
{
int mid = (l + r) / 2;
build(id * 2, l, mid);
build(id * 2 + 1, mid + 1, r);
update(id);
}
}
void modify(int id, int l, int r, int ql, int qr, int deta)
{
if (l == ql && r == qr)
{
settag(id, deta);
return;
}
int mid = (l + r) / 2;
pushdown(id); // 下放标记
if (qr <= mid) modify(id * 2, l, mid, ql, qr, deta);
else if (ql > mid) modify(id * 2 + 1, mid + 1, r, ql, qr, deta);
else
{
modify(id * 2, l, mid, ql, mid, deta);
modify(id * 2 + 1, mid + 1, r, mid + 1, qr, deta);
}
update(id);
}
};
inline void solve()
{
int n; cin >> n;
for (int i = 1; i <= n; i++)
{
int x1, y1, x2, y2;
cin >> x1 >> y1 >> x2 >> y2;
vx.pb(x1);
vx.pb(x2);
event.pb({y1, 1, x1, x2}); // 需要插入的线段
event.pb({y2, -1, x1, x2}); // 需要删除的线段
}
sort(event.begin(), event.end());
sort(vx.begin(), vx.end());
vx.erase(unique(vx.begin(), vx.end()), vx.end());
SegmentTree<int> SegTree(vx.size());
int m = vx.size() - 1; // m个点构成m-1个线段
SegTree.build(1, 1, m);
int last = 0; // 上一个线段
LL ans = 0;
int totlen = SegTree.seg[1].minncnt;
for (auto evt : event)
{
int cov = totlen;
if (SegTree.seg[1].minn == 0) cov = totlen - SegTree.seg[1].minncnt;
ans += (LL)(evt[0] - last) * cov;
last = evt[0];
int ql = lower_bound(vx.begin(), vx.end(), evt[2]) - vx.begin() + 1;
int qr = lower_bound(vx.begin(), vx.end(), evt[3]) - vx.begin();
SegTree.modify(1, 1, m, ql, qr, evt[1]);
}
cout << ans << endl;
}
Eg:区间不同数的个数
定义一下:pre[i]表示a[i]上一次出现的位置,那么区间[l, r]的贡献就是满足
就转化成了二维数点问题,
可以发现对于一个查询只需要求阴影部分的面积
inline void solve()
{
int n; cin >> n;
vector<int> a(n + 1);
vector<array<int, 4>> event;
vector<int> pre(n + 1);
map<int, int> last;
for (int i = 1; i <= n; i++)
{
cin >> a[i];
pre[i] = last[a[i]];
last[a[i]] = i;
event.pb({pre[i], 0, i, 1}); // 求个数权值就是1,求和就是a[i]
}
int q; cin >> q;
for (int i = 1; i <= q; i++)
{
int l, r; cin >> l >> r;
event.pb({l - 1, 1, l - 1, i});
event.pb({l - 1, 2, r, i});
}
sort(event.begin(), event.end());
BIT<int> bit(n);
vector<int> ans(q + 1);
for (auto evt : event)
{
if (evt[1] == 0) bit.modify(evt[2], evt[3]);
else
{
if (evt[1] == 1) ans[evt[3]] -= bit.query(evt[2]);
else ans[evt[3]] += bit.query(evt[2]);
}
}
for (int i = 1; i <= q; i++)
cout << ans[i] << endl;
}
树的直径
dfs两次,第一次随便找一个点跑一边,第二次以第一次找到的点再跑一次。
auto dfs = [&](auto self, int u, int fa) -> pair<LL, int> // 返回距离u点最远点的距离和标号
{
pair<LL, int> res = {0, u};
for (auto v : adj[u])
{
if (v[0] == fa) continue;
auto t = self(self, v[0], u);
t.first += v[1];
if (t.first > res.first)
{
res = t;
}
}
return res;
};
dp做法:dp[i]以i根节点的子树直径
LL dist = 0;
auto dfs = [&](auto self, int u, int fa) -> void
{
for (auto v : adj[u])
{
if (v[0] == fa) continue;
self(self, v[0], u);
dist = max(dist, dp[u] + dp[v] + v[1]);
dp[u] = max(dp[u], dp[v] + v[1]);
}
}
树状数组
-
lowbit(x) = x & -x; // 求二进制最后一位一,101100 => 100
-
维护一个原数组a,可以在O(log n)实现单点加以及查询前缀和
-
template<class T>
struct BIT
{
std::vector<T> c;
int n;
BIT(int siz)
{
c.resize(siz + 1);
n = siz;
};
T query(int x)
{
T s = 0;
while (x)
{
s += c[x];
x -= x & (-x);
}
return s;
}
void modify(int x, T s)
{
while (x <= n)
{
c[x] += s;
x += x & (-x);
}
}
};
-
求逆序对,权值树状数组
给定一个n排列求逆序对个数,我们维护一个集合D,能与a[i]构成逆序对的个数,其实就是[1, i - 1]中有多少个比你大的数,将D看成一个桶排序用权值作为下标,静态问题改成动态问题 for (int i = 1; i <= n; i++) { ans += D(a[i])的后缀和; // 此时a[i]之后的数并没有加入D D(a[i]) += 1; } 所以D需要有两个功能: 1. 查询后缀和,如果将a[i]反过来就变成求前缀和,a[i] = n + 1 - a[i] 2. 单点加 bool cmp(int a, int b) { return old[a] == old[b] ? a > b : old[a] > old[b]; } inline void solve() { LL n; cin >> n; BIT<LL> bit(n); for (int i = 1; i <= n; i++) { cin >> old[i]; a[i] = i; } sort(a+ 1, a + n + 1, cmp); // 离散化,保持大小关系,从大到小排,这样就不用反过来 LL ans = 0; for (int i = 1; i <= n; i++) { bit.modify(a[i], 1); ans += bit.query(a[i] - 1); } cout << ans << endl; } 逆序对常见结论: 如果只交换相邻两个数,无序数列变成有序数列的最少交换次数为逆序对个数 冒泡排序的趟数等于每个位置对应的逆序对个数的最大值 -
与差分结合
我们维护原数组的差分数组d: 1. 区间加 => d[l] += 1, d[r + 1] += -1; 2. 前缀和查询 => sum[x] = d[1] + (d[1] + d[2]) +... = x * d[1] + (x - 1) * d[2]... = sum{(x + 1 - i) * d[i]} = (x + 1)*sum{d[i]} - sum{i * d[i]} 所以开两个树状数组维护一下,d[i] 和 i * d[i] 的前缀和 -
与二分结合
1. 单点修改 2. 找到一个最大的T, 使得s[T] <= target c代表的是 ???001 到 ???100 的区间和 int query(int target) { int pos = 0; for (int j = 18; j >= 0; j--) { // 从高位到低位,一次变1 if (pos + (1 << j) <= n && c[pos + (1 << j)] <= target) { pos += 1 << j; target -= c[pos]; } } return pos; } -
求第K大
T query(int x) { T pos = 0; for (int j = 15; j >= 0; j--) { if (pos + (1 << j) < size && c[pos + (1 << j)] < x) { pos += 1 << j; x -= c[pos]; } } return pos + 1; // c 是数字出现的次数 } -
区间查询最值
第一步<建树> 可以把原来的modify中的相加改成对应的max,min 第二步<求区间最值> 这步不可以直接求和,因为最值并没有这个性质,所以先分成两种情况 if(r - lowbit(r) > l) : 这是把区间分成[l, r - lowbit(r)] 和 [r - lowbit(r) + 1, r] 又因为[r - lowbit(r) + 1, r]本身就是c[r], 所以问题变成了c[r] 和 [l, r - lowbit(r)] 求最值。 else :我们直接把a[r]剥离出来,问题就变成了a[r] 和 [l, r - 1]; template<class T> struct BIT { std::vector<T> c_min, c_max; int size; BIT(int n) { c_min.resize(n + 1, inf); c_max.resize(n + 1); size = n; } void modify(int x, int s) { while (x <= size) { c_min[x] = min(c_min[x], s); c_max[x] = max(c_max[x], s); x += x & (-x); } } T query_min(int l, int r) { if (r > l) { if (r - (r & (-r)) > l) return min(c_min[r], query_min(l, r - (r & (-r)))); else return min(a[r], query_min(l, r - 1)); } else { return a[l]; } } T query_max(int l, int r) { if (r > l) { if (r - (r & (-r)) > l) return max(c_max[r], query_max(l, r - (r & (-r)))); else return max(a[r], query_max(l, r - 1)); } else { return a[l]; } } };
斯坦纳树
在图中求给定点的最小生成树,例题
inline void solve()
{
int n, m, k; cin >> n >> m >> k;
std::vector<vector<pair<int, int>>> adj(n + 1);
for (int i = 0; i < m; i++)
{
int x, y, z; cin >> x >> y >> z;
adj[x].pb({y, z});
adj[y].pb({x, z});
}
vector dp(1 << (k - 1), vector<LL>(n + 1, INF)); // 以i为根节点,关键点的状态为s的最小生成树代价
for (int i = 1; i < k; i++) dp[1 << (i - 1)][i] = 0;
for (int s = 0; s < 1 << (k - 1); s++)
{
for (int t = s; t != 0; t = (t - 1) & s)
{
for (int i = 1; i <= n; i++)
{
dp[s][i] = min(dp[s][i], dp[t][i] + dp[s ^ t][i]);
}
}
priority_queue<pair<LL, int>, vector<pair<LL, int>>, greater<>> q;
for (int i = 1; i <= n; i++)
{
if (dp[s][i] != INF) q.push({dp[s][i], i});
}
while (!q.empty())
{
auto [d, x] = q.top();
q.pop();
if (d != dp[s][x]) continue;
for (auto [v, w] : adj[x])
{
if (dp[s][v] > dp[s][x] + w)
{
dp[s][v] = dp[s][x] + w;
q.push({dp[s][v], v});
}
}
}
}
for (int i = k; i <= n; i++) cout << dp[(1 << (k - 1)) - 1][i] << endl;
}
线段树
1.思想
将序列划分成若干段,每一段都维护一个相同的信息,以维护最小值为例
如上如图所示,将区间划分若干段,每一段维护一个最小值,支持单点修改和区间查询,修改的话也是不断递归到叶子节点然后直接修改复杂度是O(logn),查询也是递归查询复杂度也是O(logn)
struct node{
int val;
} seg[N * 4]; // 一般空间要开四倍
int a[N];
void update(int id)
{
seg[id].val = min(seg[id * 2 ].val, seg[id * 2 + 1].val);
}
void build(int id, int l, int r)
{
if (l == r)
{
seg[id].val = a[l];
}
else
{
int mid = (l + r) / 2;
build(id * 2, l, mid);
build(id * 2 + 1, mid + 1, r);
update(id);
}
}
// 把a[pos]改成x
void change(int id, int l, int r, int pos, int x)
{
if (l == r)
{
seg[id].val = x;
}
else
{
int mid = (l + r) / 2;
if (pos <= mid) change(id * 2, l, mid, pos, x);
else change(id * 2 + 1, mid + 1, r, pos, x);
update(id);
}
}
int query(int id, int l, int r, int ql, int qr)
{
if (l == ql && r == qr) return seg[id].val;
int mid = (l + r) / 2;
if (qr <= mid) return query(id * 2, l, mid, ql, qr);
else if (ql > mid) return query(id * 2 + 1, mid + 1, r, ql, qr);
else
{
return min(query(id * 2, l, mid, ql, mid),
query(id * 2 + 1, mid + 1, r, mid + 1, qr));
}
}
2. 最大字段和
分成三种情况讨论,假设答案区间在左子树,右子树,横跨左右子树,第三种情况要结合前后缀分析
struct info{
// 最大字段和,最大前缀和,最大后缀和,总和
LL mss, mpre, msuf, s;
};
info operator + (const info &l, const info &r) // 重载运算符
{
info a;
a.mss = max({l.mss, r.mss, l.msuf + r.mpre});
a.mpre = max(l.mpre, l.s + r.mpre);
a.msuf = max(r.msuf, r.s + l.msuf);
a.s = l.s + r.s;
return a;
}
struct node{
info val;
} seg[N * 4];
int a[N];
void update(int id)
{
seg[id].val = seg[id * 2 ].val + seg[id * 2 + 1].val;
}
void build(int id, int l, int r)
{
if (l == r)
{
seg[id].val = {a[l], a[l], a[l], a[l]};
}
else
{
int mid = (l + r) / 2;
build(id * 2, l, mid);
build(id * 2 + 1, mid + 1, r);
update(id);
}
}
// 把a[pos]改成x
void change(int id, int l, int r, int pos, int x)
{
if (l == r)
{
seg[id].val = {x, x, x, x};
}
else
{
int mid = (l + r) / 2;
if (pos <= mid) change(id * 2, l, mid, pos, x);
else change(id * 2 + 1, mid + 1, r, pos, x);
update(id);
}
}
info query(int id, int l, int r, int ql, int qr)
{
if (l == ql && r == qr) return seg[id].val;
int mid = (l + r) / 2;
if (qr <= mid) return query(id * 2, l, mid, ql, qr);
else if (ql > mid) return query(id * 2 + 1, mid + 1, r, ql, qr);
else
{
return query(id * 2, l, mid, ql, mid) + query(id * 2 + 1, mid + 1, r, mid + 1, qr);
}
}
inline void solve()
{
int n, q; cin >> n >> q;
for (int i = 1; i <= n; i++)
cin >> a[i];
build(1, 1, n);
while (q--)
{
int op; cin >> op;
if (op == 1)
{
int x, d; cin >> x >> d;
change(1, 1, n, x , d);
}
else
{
int l, r; cin >> l >> r;
cout << query(1, 1, n, l, r).mss << endl;
}
}
}
3. 区间修改,区间查询
把所有包含在区间,[l, r]中的节点都遍历一次、修改一次,时间复杂度无法承受。我们这里要引入一个叫做 「懒惰标记」 的东西。懒惰标记,简单来说,就是通过延迟对节点信息的更改,从而减少可能不必要的操作次数。每次执行修改时,我们通过打标记的方法表明该节点对应的区间在某一次操作中被更改,但不更新该节点的子节点的信息。实质性的修改则在下一次访问带有标记的节点时才进行。
例题: 区间加,区间查询最大值
struct info{
// 最大字段和,最大前缀和,最大后缀和,总和
LL maxx;
};
struct tag{
LL add;
};
struct node{
tag t;
info val;
} seg[N * 4];
int a[N];
info operator + (const info &l, const info &r){ return {max(l.maxx, r.maxx)}; }
info operator + (const info &v, const tag &t){ return {v.maxx + t.add}; }
tag operator + (const tag &t1, const tag &t2){ return {t1.add + t2.add}; }
void settag(int id, tag t)
{
seg[id].val = seg[id].val + t;
seg[id].t = seg[id].t + t;
}
void update(int id)
{
seg[id].val = seg[id * 2 ].val + seg[id * 2 + 1].val;
}
void pushdown(int id)
{
if (seg[id].t.add != 0)
{
settag(id * 2, seg[id].t);
settag(id * 2 + 1, seg[id].t);
seg[id].t.add = 0;
}
}
void build(int id, int l, int r)
{
if (l == r)
{
seg[id].val = {a[l]};
}
else
{
int mid = (l + r) / 2;
build(id * 2, l, mid);
build(id * 2 + 1, mid + 1, r);
update(id);
}
}
// 把a[pos]改成x
void change(int id, int l, int r, int ql, int qr, tag t)
{
if (l == ql && r == qr)
{
settag(id, t);
return;
}
pushdown(id);
int mid = (l + r) / 2;
if (qr <= mid) change(id * 2, l, mid, ql, qr, t);
else if (ql > mid) change(id * 2 + 1, mid + 1, r, ql, qr, t);
else
{
change(id * 2, l, mid, ql, mid, t);
change(id * 2 + 1, mid + 1, r, mid + 1, qr, t);
}
update(id);
}
info query(int id, int l, int r, int ql, int qr)
{
if (l == ql && r == qr) return seg[id].val;
pushdown(id);
int mid = (l + r) / 2;
if (qr <= mid) return query(id * 2, l, mid, ql, qr);
else if (ql > mid) return query(id * 2 + 1, mid + 1, r, ql, qr);
else
{
return query(id * 2, l, mid, ql, mid) + query(id * 2 + 1, mid + 1, r, mid + 1, qr);
}
}
inline void solve()
{
int n, q; cin >> n >> q;
for (int i = 1; i <= n; i++)
cin >> a[i];
build(1, 1, n);
while (q--)
{
int op; cin >> op;
if (op == 1)
{
int l, r, d; cin >> l >> r >> d;
change(1, 1, n, l, r, (tag){d});
}
else
{
int l, r; cin >> l >> r;
cout << query(1, 1, n, l, r).maxx << endl;
}
}
}
// 区间修改,查询区间和
struct info
{
LL sum, tag;
info()
{
sum = 0;
tag = 0;
}
};
struct LazySegmentTree
{
std::vector<info> seg;
LazySegmentTree(int n, vector<LL>& init)
{
seg.resize(4 * n + 1);
function<void(int, int, int)> build = [&](int id, int l, int r)
{
if (l == r)
{
seg[id].sum = init[l];
return;
}
int mid = (l + r) / 2;
build(2 * id, l, mid);
build(2 * id + 1, mid + 1, r);
update(id);
};
build(1, 1, n);
}
void settag(int id, LL tag, int l, int r) // 打标记,打完需要去更新当前区间的info,并且要叠加tag
{
seg[id].sum += tag * (r - l + 1);
seg[id].tag += tag;
}
void update(int id)
{
seg[id].sum = seg[2 * id].sum + seg[2 * id + 1].sum;
}
void pushdown(int id, int l, int r) // 下放标记
{
if (seg[id].tag != 0)
{
int mid = (l + r) / 2;
settag(2 * id, seg[id].tag, l, mid);
settag(2 * id + 1, seg[id].tag, mid + 1, r);
seg[id].tag = 0;
}
}
void modifly(int id, int l, int r, int ql, int qr, LL add)
{
if (l == ql && r == qr)
{
settag(id, add, l, r);
return;
}
pushdown(id, l, r); // 每次都要把之前的tag下放
int mid = (l + r) / 2;
if (qr <= mid) modifly(2 * id, l, mid, ql, qr, add);
else if (ql > mid) modifly(2 * id + 1, mid + 1, r, ql, qr, add);
else
{
modifly(2 * id, l, mid, ql, mid, add);
modifly(2 * id + 1, mid + 1, r, mid + 1, qr, add);
}
update(id); // 修改完之后要更新信息
}
LL query(int id, int l, int r, int ql, int qr)
{
if (l == ql && r == qr)
{
return seg[id].sum;
}
pushdown(id, l, r);
int mid = (l + r) / 2;
if (qr <= mid) return query(2 * id, l, mid, ql, qr);
else if (ql > mid) return query(2 * id + 1, mid + 1, r, ql, qr);
else
{
return query(2 * id, l, mid, ql, mid) + query(2 * id + 1, mid + 1, r, mid + 1, qr);
}
}
};
// 区间加,区间乘
struct info
{
LL sum, mul, add, sz;
};
struct LazySegmentTree
{
std::vector<info> seg;
LazySegmentTree(int n, vector<LL>& init)
{
seg.resize(4 * n + 1);
function<void(int, int, int)> build = [&](int id, int l, int r)
{
seg[id].sz = r - l + 1;
seg[id].mul = 1;
seg[id].add = 0;
if (l == r)
{
seg[id].sum = init[l];
return;
}
int mid = (l + r) / 2;
build(2 * id, l, mid);
build(2 * id + 1, mid + 1, r);
update(id);
};
build(1, 1, n);
}
void settag(int id, LL mul, LL add) // 打标记,打完需要去更新当前区间的info,并且要叠加tag
{
seg[id].mul = (seg[id].mul * mul) % MOD;
seg[id].add = (seg[id].add * mul + add) % MOD;
seg[id].sum = (seg[id].sum * mul + seg[id].sz * add) % MOD;
}
void update(int id)
{
seg[id].sum = (seg[2 * id].sum + seg[2 * id + 1].sum) % MOD;
}
void pushdown(int id) // 下放标记
{
if (seg[id].mul != 1 || seg[id].add != 0)
{
settag(2 * id, seg[id].mul, seg[id].add);
settag(2 * id + 1, seg[id].mul, seg[id].add);
seg[id].mul = 1;
seg[id].add = 0;
}
}
void modifly(int id, int l, int r, int ql, int qr, LL mul, LL add)
{
if (l == ql && r == qr)
{
settag(id, mul, add);
return;
}
pushdown(id); // 每次都要把之前的tag下放
int mid = (l + r) / 2;
if (qr <= mid) modifly(2 * id, l, mid, ql, qr, mul, add);
else if (ql > mid) modifly(2 * id + 1, mid + 1, r, ql, qr, mul, add);
else
{
modifly(2 * id, l, mid, ql, mid, mul, add);
modifly(2 * id + 1, mid + 1, r, mid + 1, qr, mul, add);
}
update(id); // 修改完之后要更新信息
}
LL query(int id, int l, int r, int ql, int qr)
{
if (l == ql && r == qr)
{
return seg[id].sum;
}
pushdown(id);
int mid = (l + r) / 2;
if (qr <= mid) return query(2 * id, l, mid, ql, qr);
else if (ql > mid) return query(2 * id + 1, mid + 1, r, ql, qr);
else
{
return (query(2 * id, l, mid, ql, mid) + query(2 * id + 1, mid + 1, r, mid + 1, qr)) % MOD;
}
}
};
字典树

就是将字符串用树的方式存储.
Eg:给一组数和 q 个询问,每次询问查询x与所有数异或之后的第k小?
先把这组数的字典树建出来,然后对于每个x我们从高位开始考虑,最优解肯定是选和当前位一样的,但是如果最优解没有k个数那肯定不行,那就只能走反方向
但是我们可以把最优解的y个数全部放前面这样就只需要在反方向求 k - y 小,因为字典树从高位开始建的
struct Trie{
struct node{
int s[2];
int sz;
};
std::vector<node> t;
int tot = 1;
Trie(){}
Trie(int size)
{
t.resize(size * 32);
}
void insert(int x)
{
int p = 1;
for (int i = 30; i >= 0; i--)
{
int w = (x >> i) & 1;
t[p].sz += 1;
if (t[p].s[w] == 0) t[p].s[w] = ++tot;
p = t[p].s[w];
}
t[p].sz += 1;
}
int query(int x, int k) // 查询x与所有数异或之后的第k小
{
int p = 1;
int ans = 0;
for (int i = 30; i >= 0; i--)
{
int w = (x >> i) & 1;
if (t[t[p].s[w]].sz >= k) p = t[p].s[w]; // 优先看一下和我一样的能不能直接去
else
{
k -= t[t[p].s[w]].sz; // 因为走最优解的话个数不够k个,所以让最优解全部放在前面,那么就变成了求 k - sz 小
ans ^= 1 << i;
p = t[p].s[1 ^ w];
}
}
return ans;
}
};
inline void solve()
{
int n, q; cin >> n >> q;
vector<int> a(n);
Trie trie(n);
for (int i = 0; i < n; i++)
{
int x; cin >> x;
trie.insert(x);
}
while (q--)
{
int x, k; cin >> x >> k;
cout << trie.query(x, k) << endl;
}
}
struct Trie{
struct node{
int ne[26];
};
std::vector<node> t;
vector<int> end, cnt; // 结束标记,节点出现次数
int tot = 1;
Trie(){}
Trie(int size)
{
t.resize(size);
end.resize(size);
cnt.resize(size);
}
void init(int p) // 多组测试要清空
{
end[p] = 0;
cnt[p] = 0;
for (int i = 0; i < 26; i++) t[p].ne[i] = 0;
}
void insert(string s)
{
int p = 1;
for (auto c : s)
{
if (!t[p].ne[c - 'a'])
{
tot++;
init(tot); // 先清空之前的数据
t[p].ne[c - 'a'] = tot;
}
p = t[p].ne[c - 'a'];
cnt[p]++;
}
end[p]++;
}
}trie(N);
字符串Hash
struct Hash
{
LL hs1[N], hs2[N], pow1[N], pow2[N];
inline void init(string s, const LL mod1 = 998244353, const LL mod2 = 19660813)
{
const int P = 131;
hs1[0] = hs2[0] = 0;
pow1[0] = pow2[0] = 1;
for (int i = 1; i < s.size(); i++)
{
hs1[i] = (hs1[i - 1] * P % mod1 + s[i] - 'a' + 1) % mod1;
hs2[i] = (hs2[i - 1] * P % mod2 + s[i] - 'a' + 1) % mod2;
pow1[i] = pow1[i - 1] * P % mod1;
pow2[i] = pow2[i - 1] * P % mod2;
}
}
inline pair<LL, LL> query(LL l, LL r, const LL mod1 = 998244353, const LL mod2 = 19660813)
{
LL res1 = (hs1[r] - hs1[l - 1] * pow1[r - l + 1] % mod1 + mod1) % mod1;
LL res2 = (hs2[r] - hs2[l - 1] * pow2[r - l + 1] % mod2 + mod2) % mod2;
return make_pair(res1, res2);
}
}
最近公共祖先
在一棵有根树里面,如果节点z既是节点x的祖先,也是节点y的祖先,则称z为(x, y)的公共祖先,在(x, y)的所有公共祖先中深度最大的叫做最近公共祖先。
-
求解方法
向上标记法
从
x向根节点走,把沿途的节点都打上标记,再从y向根节点走碰到的第一个被标记的点就是最近公共祖先,但是一次查询的复杂度是O(n)的树上倍增法
和上面的基本一样,但是我们一次走
f[x, k]表示x节点向上走还需要预处理一个
depp[x]表示x的深度,每次先让(x, y)走到同一深度,再一起向上走****注意在使用之前要先把深度处理出来***** template<class T> struct LCA { std::vector<int> deep; vector<vector<int>> adj, fa; LCA(){} LCA(int size) { deep.resize(size + 1, 0); adj.resize(size + 1); fa.resize(size + 1, vector<int>(25, 0)); } void dfs(int x, int f) { deep[x] = deep[f] + 1; fa[x][0] = f; for (int i = 1; (1 << i) <= deep[x]; i++) fa[x][i] = fa[fa[x][i - 1]][i - 1]; for (auto y : adj[x]) { if (y == f) continue; dfs(y, x); } } int get(int x, int y) { if (deep[x] < deep[y]) swap(x, y); for (int i = 20; i >= 0; i--) { if (deep[fa[x][i]] >= deep[y]) x = fa[x][i]; } if (x == y) return y; for (int i = 20; i >= 0; i--) { if (fa[x][i] != fa[y][i]) { x = fa[x][i]; y = fa[y][i]; } } return fa[x][0]; } };
KMP算法
kmp可以用来解决字符串匹配问题,对于给定的两个字符串s,p。我们需要在s中查找p。如果是返回第一次出现的位置。
一般暴力枚举的复杂度在O(nm),这是我们不能接受的。我们需要定义一个next数组来简化暴力,next数组的含义:在p中以i为结尾的后缀和前缀相等的最大长度
void kmp(string s, string p) // 在s中找p
{
int n = s.size() - 1, m = p.size() - 1; // 下标要从1开始,所以就在字符串前面加了个空字符
std::vector<int> ne(m + 1, 0);
for (int i = 2, j = 0; i <= m; i++)
{
while (j && p[i] != p[j + 1]) j = ne[j];
if (p[i] == p[j + 1]) j++;
ne[i] = j;
}
for (int i = 1, j = 0; i <= n; i++)
{
while (j && s[i] != p[j + 1]) j = ne[j];
if (s[i] == p[j + 1]) j++;
if (j == m)
{
printf("%d ", i - m) // 输出正确匹配的起始位置
}
}
}
ST表
定义:基于倍增的思想,可以做到O( nlog(n) )的预处理,O(1) 的回答每个问题,但是不支持修改操作,先处理出来f[i][j]表示从i开始往后走[l, r]我们最多拆成两个长度为2次幂的区间就可以求出答案。
可以求区间或,区间与,区间最值等等,在查询方面比线段树要优
template<class T>
struct SparseTable
{
std::vector<vector<T>> f;
int n;
SparseTable(){}
SparseTable(int size)
{
n = size;
f.assign(size + 1, vector<T>(22, 0));
init();
}
void init()
{
for (int i = 1; i <= n; i++) f[i][0] = a[i];
for (int j = 1; j <= 20; j++)
for (int i = 1; i + (1 << j) - 1 <= n; i++)
f[i][j] = max(f[i][j - 1], f[i + (1 << (j - 1))][j - 1]);
}
T query(int l, int r) // 查找区间最大值
{
int len = __lg(r - l + 1);
T ans = 0;
ans ^= max(f[l][len], f[r - (1 << len) + 1][len]);
return ans;
}
};
数论
将n个有区别的小球,放进m个无差别的盒子的方案数
template<class T> T qmi(T a, LL b)
{
T res = 1;
while (b)
{
if (b & 1) res = res * a % MOD;
a = a * a % MOD;
b >>= 1;
}
return res;
}
struct Comb
{
std::vector<LL> fac;
std::vector<LL> invfac;
int n, m;
Comb(){}
Comb(int n, int m) : n(n), m(m)
{
fac.resize(n + 1, 1);
invfac.resize(n + 1, 1);
for (int i = 1; i <= n; i++)
{
fac[i] = fac[i - 1] * i % MOD;
invfac[i] = qmi<LL>(fac[i], MOD - 2);
}
}
LL GetStirling()
{
if (n < m) return 0;
LL res = 0;
for (int i = 0; i <= m; i++)
{
LL p = qmi<LL>(i, n) * invfac[i] % MOD * invfac[m - i] % MOD;
if ((m - i) % 2)
{
res += MOD - p;
}
else
{
res += p;
}
}
res = res % MOD;
return res;
}
};
快速幂
template<class T>
T qmi(T a, LL b) {
T res = 1;
while (b)
{
if (b & 1) res = res * a % MOD;
a = a * a % MOD;
b >>= 1;
}
return res;
}
显示实例调用
qmi<LL>(a, b)
隐式实例调用
qmi(a, b)
在模MOD的情况下,乘法逆元为 a / b = a * qmi(b, MOD - 2)
欧几里得
欧几里得求最小公因数,a或者b是大整数则可以利用gcd(a, b) = gcd(b, a % b)。先对大数取模再gcd。大数取模就是在qjs中每一步都取模
int gcd(int a, int b)
{
if (b == 0) return a;
else return gcd(b, a % b);
}
扩展欧几里得求 ax + by = gcd(a, b)的整数解,其他情况只要再乘上一个(c / gcd(a, b))
int exgcd(int a, int b, int &x, int &y)
{
if (b == 0)
{
x = 1;
y = 0;
return a;
}
int xx, yy;
int d = exgcd(b, a % b, xx, yy);
x = yy;
y = xx - (a / b) * yy;
return d;
}
欧拉筛
我们从小到大考虑每个数,然后同时把当前这个数的所有(比自己大的)倍数记为合数,那么运行结束的时候没有被标记的数就是素数了。简单做法就是直接嵌套一层循环然后去标记,但是会导致部分合数被多次标记使得复杂度较高O(n* loglog(n))这叫埃氏筛,优化一下标记过程使得每个合数只被标记一次这叫欧拉筛。
std::vector<int> minp, primes; // i的最小质因子,素数集合
void sieve(int n)
{
minp.assign(n + 1, 0);
primes.clear();
for (int i = 2; i <= n; i++)
{
if (minp[i] == 0)
{
minp[i] = i;
primes.push_back(i);
}
for (auto p : primes)
{
if (i * p > n)
{
break;
}
minp[i * p] = p;
if (p == minp[i]) // 在之前已经被筛了
{
break;
}
}
}
}
取模类
namespace Modulus
{
int norm(int x)
{
if (x < 0) x += MOD;
if (x >= MOD) x -= MOD;
return x;
}
template<class T>
T qmi(T a, LL b) { // 是不带取模的,单独使用要强转为Z类型
T res = 1;
while (b)
{
if (b & 1) res = res * a;
a = a * a;
b >>= 1;
}
return res;
}
struct Z
{
int x;
Z(int x = 0) : x(norm(x)) {}
Z(LL x) : x(norm(x % MOD)) {}
int val() const{ return x; }
Z operator- () const{ return Z(norm(MOD - x)); }
Z inv() const
{
assert(x != 0);
return qmi(*this, MOD - 2);
}
Z &operator*=(const Z &rhs)
{
x = LL(x) * rhs.x % MOD;
return *this;
}
Z &operator+=(const Z &rhs)
{
x = norm(x + rhs.x);
return *this;
}
Z &operator-=(const Z &rhs)
{
x = norm(x - rhs.x);
return *this;
}
Z &operator/=(const Z &rhs)
{
return *this *= rhs.inv();
}
friend Z operator*(const Z &lhs, const Z &rhs)
{
Z res = lhs;
res *= rhs;
return res;
}
friend Z operator+(const Z &lhs, const Z &rhs)
{
Z res = lhs;
res += rhs;
return res;
}
friend Z operator-(const Z &lhs, const Z &rhs)
{
Z res = lhs;
res -= rhs;
return res;
}
friend Z operator/(const Z &lhs, const Z &rhs)
{
Z res = lhs;
res /= rhs;
return res;
}
friend std::istream &operator>>(std::istream &is, Z &a)
{
LL v;
is >> v;
a = Z(v);
return is;
}
friend std::ostream &operator<<(std::ostream &os, const Z &a)
{
return os << a.val();
}
};
}
对顶堆维护中位数
class Medium_Solver
{
private:
multiset<int> lo, hi;
i64 sum_lo, sum_hi;
public:
Medium_Solver()
{
Init();
}
void Init()
{
lo.clear();
hi.clear();
sum_lo = 0;
sum_hi = 0;
}
void Insert(int x)
{
if (hi.empty())
{
hi.insert(x);
sum_hi += x;
return;
}
int mid = *hi.begin();
if (x >= mid)
{
hi.insert(x); sum_hi += x;
int siz_lo = lo.size(), siz_hi = hi.size();
if (siz_hi - siz_lo > 1)
{
auto it = hi.begin();
sum_hi -= *it;
sum_lo += *it;
lo.insert(*it);
hi.erase(it);
}
}
else
{
lo.insert(x); sum_lo += x;
int siz_lo = lo.size(), siz_hi = hi.size();
if (siz_lo > siz_hi)
{
auto it = (--lo.end());
sum_hi += *it;
sum_lo -= *it;
hi.insert(*it);
lo.erase(it);
}
}
}
void Remove(int x)
{
int mid = *hi.begin();
if (x >= mid)
{
hi.erase(hi.find(x));
sum_hi -= x;
int siz_lo = lo.size(), siz_hi = hi.size();
if (siz_lo > siz_hi)
{
auto it = (--lo.end());
sum_hi += *it;
sum_lo -= *it;
hi.insert(*it);
lo.erase(it);
}
}
else
{
lo.erase(lo.find(x));
sum_lo -= x;
int siz_lo = lo.size(), siz_hi = hi.size();
if (siz_hi - siz_lo > 1)
{
auto it = hi.begin();
sum_hi -= *it;
sum_lo += *it;
lo.insert(*it);
hi.erase(it);
}
}
}
int query() // 查询中位数
{
int mid = *hi.begin();
return mid;
}
};
图论
二分图
含义:对于一个无向图,顶点可以划分为两个没有交集的集合,并且集合内部没有边 ,如果U的每个点到V的每个点都有一条连边,这样的二分图叫完全二分图
性质:1. 如果两个集合中的点分别染成黑色和白色,可以发现二分图中的每一条边都一定是连接一个黑色点和一个白色点。
2. 二分图不存在长度为奇数的环
判定:点染色法,每次从一个未染色的点开始染色,比如把u点染成黑色,然后把所有与u相连的点染成相反颜色,如果在染色过程中发生冲突就说明此图不是二分图
struct BG
{
std::vector<std::vector<int>> adj;
vector<int> c;
int n;
BG(){}
BG(int size)
{
adj.resize(size + 1);
c.resize(size + 1, 0);
n = size;
}
bool dfs(int u)
{
for (auto v : adj[u])
{
if (c[v] == 0)
{
c[v] = 3 - c[u];
if (!dfs(v)) return false;
}
else
{
if (c[u] == c[v]) return false;
}
}
return true;
}
bool check()
{
for (int i = 1; i <= n; i++)
{
if (c[i] == 0)
{
c[i] = 1;
if (!dfs(i)) return false;
}
}
return true;
}
};
inline void solve()
{
int n, m; cin >> n >> m;
BG bg(n);
for (int i = 0; i < m; i++)
{
int x, y; cin >> x >> y;
bg.adj[x].pb(y);
bg.adj[y].pb(x);
}
if (bg.check()) cout << "Yes" << endl;
else cout << "No" << endl;
}
Dijkstar
不断从未确定的点集中,取出离起点最近的点作为桥梁更新其它点
vector<LL> dist(n + 1, INF);
dist[1] = 0;
priority_queue<pair<LL, LL>,vector<pair<LL, LL>>,greater<>> q;
q.push({0, 1});
while (!q.empty())
{
auto t = q.top();
q.pop();
if (st[t.second]) continue;
st[t.second] = true;
for (auto [v, d] : adj[t.second])
{
if (dist[v] > dist[t.second] + d)
{
dist[v] = dist[t.second] + d;
q.push({dist[v], v});
}
}
}
SCC
主要是在DFS树上做操作,如果u点不能通过非树边到达之前遍历的点,则以u为根节点的子树为强连通分量
struct SCC // 有向图
{
vector<int> dfn, low, id;
vector<vector<int>> adj;
int n;
SCC(){}
SCC(int sz) : n(sz), dfn(n + 1, -1), low(n + 1, -1), id(n + 1, -1){}
void AddEdge(int u, int v)
{
adj[u].pb(v);
adj[v].pb(u);
}
void Tarjian()
{
stack<int> stk;
int cnt = 0, now = 0;
function<void(int)> dfs = [&](int u)
{
dfn[u] = low[u] = now++;
stk.push(u);
for (auto v : adj[u])
{
if (dfn[v] == -1)
{
dfs(v);
low[u] = min(low[u], low[v]);
}
else if (id[v] == -1) // 说明儿子还在栈里面
{
low[u] = min(low[u], dfn[v]);
}
}
if (dfn[u] == low[u])
{
int v;
do
{
v = stk.top();
stk.pop();
id[v] = cnt;
}while (v != u);
cnt++;
}
};
for (int i = 1; i <= n; i++) if (dfn[i] == -1) dfs(i);
}
};
2-Sat
有n个布尔变量,m个布尔方程且每个方程只包含2个布尔变量,问是否存在一组解使得m个方程全部成立,使用强连通分量。对于每个变量 true 和取 false。所以,图的节点个数是两倍的变量个数。一般题目中都会暗含若a...则b...这样的条件,我们根据这样的条件来建立有向图,所以若dfn[i] < dfn[i + n] ==> x[i] = 1,即先出现的为真。
void Tarjian(std::vector<vector<int>> &adj, int n) // 求SCC
{
vector<int> dfn(2 * n + 1, -1), id(2 * n + 1, -1), low(2 * n + 1, -1); // 2-sat要开两倍空间
stack<int> stk;
int cnt = 0, now = 0;
function<void(int)> dfs = [&](int u)
{
dfn[u] = low[u] = now++;
stk.push(u);
for (auto v : adj[u])
{
if (dfn[v] == -1)
{
dfs(v);
low[u] = min(low[u], low[v]);
}
else if (id[v] == -1) // 说明儿子还在栈里面
{
low[u] = min(low[u], dfn[v]);
}
}
if (dfn[u] == low[u])
{
int v;
do
{
v = stk.top();
stk.pop();
id[v] = cnt;
}while (v != u);
cnt++;
}
};
for (int i = 1; i <= 2 * n; i++) if (dfn[i] == -1) dfs(i);
for (int i = 1; i <= n; i++)
{
if (id[i] == id[i + n])
{
cout << "No" << endl;
return;
}
}
cout << "Yes" << endl;
}
割点和割边
割点:删掉一个点后连通图变成不连通
割边:删掉一条边后连通图变成不连通
点双连通:没有割点的连通图 => 无法只删掉一个点让图变不连通 => 任意两点(u, v)之间都存在至少两条不相交的简单路径(无公共点
边双连通:没有割边的连通图 => 无法只删掉一条边让图变不连通 => 任意两点(u, v)之间都存在至少两条不相交的简单路径(无公共边
// 求割边
struct SCC
{
vector<int> dfn, low, bridge; // 求割边
vector<vector<array<int, 2>>> adj;
int n;
SCC(int sz) : n(sz), dfn(n + 1, -1), low(n + 1, -1), id(n + 1, -1){}
void AddEdge(int u, int v, int id)
{
adj[u].pb(v);
adj[v].pb(u);
}
void Tarjian()
{
int cnt = 0, now = 0;
function<void(int, int)> dfs = [&](int u, int id)
{
dfn[u] = low[u] = now++;
for (auto x : adj[u])
{
int v = x[0], id2 = x[1];
if (dfn[v] == -1)
{
dfs(v, id2);
low[u] = min(low[u], low[v]);
}
if (id != id2 && id != -1) // 说明儿子还在栈里面
{
low[u] = min(low[u], dfn[v]);
}
}
if (dfn[u] == low[u] && id != -1)
{
bridge.pb(id + 1); // 边的id从0开始
}
};
dfs(1, -1);
}
};
本文作者:自动机
本文链接:https://www.cnblogs.com/monituihuo/p/18740901
版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 2.5 中国大陆许可协议进行许可。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步