

性能最佳实践:MongoDB索引

欢迎阅读MongoDB性能最佳实践系列博客的第三篇。
在本系列中,我们将讨论在大规模数据下实现高性能,需要在许多重要维度上进行考虑的关键因素,其中包括:
数据建模和内存大小调整(工作集)
查询模式和分析
索引
分片
事务和读/写关注
硬件和操作系统配置
基准测试
根据我们在过去的15年里为多个不同数据库供应商工作的经验,可以肯定地说,如何定义合适的索引是技术支持团队必须解决的首要性能问题。
所以接下来会介绍一些有帮助的最佳实践。
MongoDB中的索引
在所有数据库中,索引都有效地支持查询的执行。如果没有它们,数据库就必须扫描集合或表中的每个文档,然后在其中选择与查询语句相匹配的那些。如果存在合适的索引,数据库就可以使用该索引来限制它必须检查的文档数量。
MongoDB提供了非常多的索引类型和特性,包括特定于不同语言的排序功能,以支持对数据复杂的访问模式。MongoDB索引可以按需创建和删除以适应不断变化的应用程序需求和查询模式,并且它们可以在文档中的任何字段上声明,包括嵌套在数组中的字段。
下面我们来讨论一下如何在MongoDB中充分地使用索引。
使用复合索引
复合索引是由几个不同字段组成的索引。例如,在对姓名进行查询时,相比于在“姓氏”上建立一个索引,再在“名字”上建立另一个索引,创建同时包含“姓”和“名”的索引通常是最有效的。而且复合索引仍然可以用于筛选仅指定姓氏的查询。
遵循ESR规则
对于复合索引,这个经验法则对于确定索引中字段的顺序是非常有帮助的:
首先,添加针对等值(Equality)查询的字段。
接下来要索引的字段应该反映出查询的排序(Sort)顺序。
最后要添加的字段表示要访问的数据的范围(Range)。
尽可能使用覆盖查询
覆盖查询可以直接从索引返回结果,而不需要访问源文档,因此非常高效。
想要查询被覆盖,需要过滤、排序和/或返回给客户端的所有字段都必须出现在索引中。要确定一个查询是否是覆盖查询,可以使用explain()方法。如果explain()输出中totalDocsExamined字段显示为0,则表明此查询被索引覆盖。更多信息请参阅文档中explain结果的部分。
在试图实现覆盖查询时,一个常见的问题是_id字段总是默认返回。需要显式地将其从查询结果中排除,或将其添加到索引中。
在分片集群中,MongoDB在内部需要访问片键字段。这意味着仅当片键是索引的一部分时才可能进行覆盖查询。无论如何,这通常都是一个很好的方式。
在低基数字段上要小心进行索引
对于具有少量唯一值(基数低)的字段进行查询会返回较大的结果集。在复合索引中可以包含基数较低的字段,但是组合字段的值应该具有较高的基数。
消除不必要的索引
索引是资源密集型的:即使在MongoDB的WiredTiger存储引擎中使用压缩,它们也会消耗RAM和磁盘。在更新字段时,必须维护关联的索引,这会带来额外的CPU和磁盘I/O开销。
MongoDB提供了工具来帮助理解索引的使用,我们将在文章后面进行介绍。
不要用通配符索引来替代基于工作负载的索引规划
对于具有许多特殊查询模式或处理高度多态文档结构的工作负载,通配符索引提供了很多额外的灵活性。可以定义一个过滤器来自动索引集合中所有匹配的字段、子文档和数组。
与其他索引一样,通配符索引也需要存储和维护,因此它们会给数据库增加开销。如果预先知道应用程序的查询模式,那么应该对查询所访问的特定字段使用更有选择性的索引。
使用文本搜索来匹配字段内的单词
常规索引对于匹配整个字段值很有用。但如果只想匹配包含大量文本字段中的特定单词,那么可以使用文本索引。
如果你在Atlas服务中运行MongoDB,可以考虑使用Atlas全文搜索,它提供了一个与MongoDB数据库集成的完全托管的Lucene索引。FTS提供了更高的性能和更大的灵活性来对数据进行过滤、排名及排序,为用户快速找出最相关的结果。
使用部分索引
通过只包含那些会通过索引访问的文档来减少索引的大小和性能开销。例如,在orderID字段上创建一个部分索引,该索引只包含orderStatus为"In progress"的订单文档,或者仅为存在emailAddress字段的文档创建索引。
利用多键索引查询数组
如果你的查询模式需要访问单个数组元素,请使用多键索引。MongoDB会为数组中的每个元素创建一个索引键,并且可以同时在包含标量值和内嵌文档的数组上构造。
避免使用非左锚定或无根的正则表达式
索引是按值排序的。前导通配符效率较低,可能会导致全索引扫描。如果表达式中有足够的区分大小写的前导字符,那么后面跟随通配符通常效率可以比较高。
避免使用大小写不敏感的正则表达式
如果使用正则表达式的唯一原因是大小写不敏感,请使用大小写不敏感索引,因为这样更快。
使用WiredTiger存储引擎中可用的索引优化
如果你使用的是自管理的MongoDB,可以选择在它们自己单独的卷上放置索引,从而允许更快的磁盘分页和更少的争用。更多信息请参见wiredTiger选项。
使用查询计划
在上一篇查询模式和分析中,我们介绍了MongoDB的查询计划的使用,这是检查单个查询索引覆盖情况的最佳工具。
根据查询计划,MongoDB提供了可视化工具来进一步帮助提高对索引的理解,并提供了关于要添加哪些索引的智能建议。
使用MongoDB Compass和Atlas数据浏览器进行索引覆盖情况的可视化
作为MongoDB的免费GUI,Compass提供了许多特性来帮助优化查询性能,包括数据模式浏览和查询计划可视化——本系列之前的文章介绍过这两方面内容。
Compass中的索引选项卡为你的工具库添加了另一个工具。它列出了一个集合的现有索引,显示出索引的名称和键,以及它的类型、大小和任何特殊属性。在索引选项卡中还可以根据需要添加和删除索引。
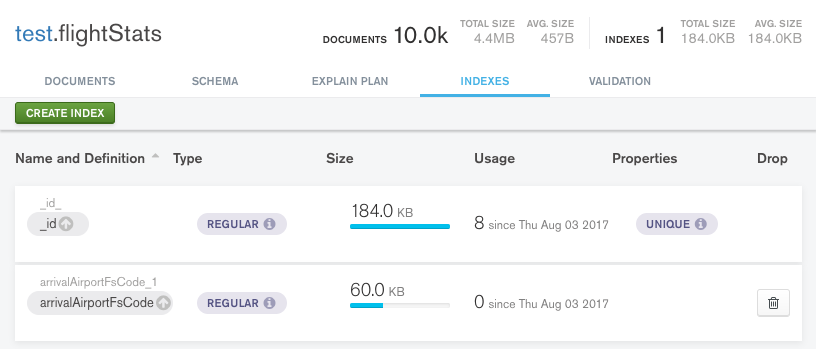
图1:使用MongoDB Compass管理索引
查看索引的使用情况是非常有用的特性,它可以显示索引的使用频率。索引过多对性能的损害几乎和索引过少是一样的,这使得此特性在帮助识别和删除未使用的索引方面非常有价值。这有助于释放工作集空间,并消除由于维护索引而带来的数据库开销。
如果你在完全托管的Atlas服务中运行MongoDB,那么数据浏览器中的索引视图可以提供与Compass相同的功能,而无需通过单独的工具连接到数据库。
还可以使用$indexStats聚合管道来获取索引的统计信息。
自动化的索引建议
即使可以使用MongoDB工具提供的所有这些遥测技术,你仍然要负责提取和分析所需的数据,以决定应该添加哪些索引。
MongoDB Atlas和Ops Manager通过Performance Advisor减少了这方面的工作,它监控执行时间超过100ms的查询,并自动对新的索引提出建议来提高性能。
被推荐的索引会与根据查询形状分组的示例查询(即具有类似谓词结构、排序和投影的查询)一起提供,这些查询针对会从建议索引中获益的集合运行。Performance Advisor不会对Atlas集群的性能产生负面影响。
如果你觉得这个建议不错,那么可以自动实行新的索引,而不会导致任何的应用程序停机时间。
接下来的内容
这就是本期的性能最佳实践系列。MongoDB University提供免费的、基于web的MongoDB性能培训课程。这是了解更多关于索引功能的非常好的途径。
下一篇将介绍分片。
本文译自:
Performance Best Practices: Indexing
译者:牟天垒 MongoDB中文社区翻译委员
MongoDB性能最佳实践系列:
性能最佳实践:MongoDB数据建模和内存大小调整
性能最佳实践:MongoDB查询模式和分析
MongoDB模式构建系列:
利用模式进行构建第一讲——多态模式
利用模式进行构建第二讲——属性模式
利用模式进行构建第三讲——桶模式
利用模式进行构建第四讲——异常值模式
利用模式进行构建第五讲——计算模式
利用模式进行构建第六讲——子集模式
利用模式进行构建第七讲——扩展引用模式
利用模式进行构建第八讲——近似值模式
利用模式进行构建第九讲——树形模式
利用模式进行构建第十讲——预分配模式
利用模式进行构建第十一讲——文档版本控制模式
利用模式进行构建第十二讲——使用模式构建系列总结

 浙公网安备 33010602011771号
浙公网安备 33010602011771号