Spring 源码解析之 XML 解析 到 BeanDefinition
前言:
为什么要学习Spring源码?我个人觉得,学习源码的应该分为3个阶段,
第一阶段,知道Spring框架设计的理念和初衷,以及其中流程的理解;
第二阶段,能够分析出来Spring框架在设计的时候,为什么会这么设计,其中运用的设计模式和设计思想;
第三阶段,可以根据开源框架的设计理念,自己在实际开发过程中,运用到开发中,并能写出一些创造性的中间件。
对于Spring的源码解析,我准备从三方面来讲述,
第一方面,解析存储Bean
第二方面,实例化Bean
第三方面,AOP是怎么实现的
这篇文章我们首先来看下Spring源码是怎么解决对Bean的解析存储的。
public static void main(String[] args) {
/**
* XML 解析用户
*/
ClassPathXmlApplicationContext applicationContext = new ClassPathXmlApplicationContext("spring.xml");
User user = (User) applicationContext.getBean("user");
System.out.println(user.getName());
}
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context.xsd"
default-lazy-init="false">
<!--自定义标签-->
<context:component-scan base-package="com.monco"/>
<!--传统标签-->
<bean class="com.monco.entity.User" id="user"/>
</beans>
package com.monco.entity;
/**
* @author monco
* @data 2020/9/15 18:33
* @description :
*/
public class User {
private String username;
private String password;
private String name = "monco";
private int age;
// 省略get set 方法
}
一段最简单的创建 applicationContext 并通过 applicationContext 得到Bean的例子,我们debug进去,就大概可以知道流程了。
1、我们这边是创建了一个 ClassPathXmlApplicationContext 的容器,这个容器的作用就是根据XML文件读取的一个上下文的容器,然后根据调用容器的 getBean(String beanName) 方法来获取Bean。
2、ClassPathXmlApplicationContext 在实例化的时候,读取 spring.xml 文件,然后调用 ClassPathXmlApplicationContext 的实例化方法,然后调用 refresh() 方法,然后这个 refresh() 方法是在 AbstractApplicationContext 中具体实现的,这里是一个
很经典的模板设计模式,在 AbstractApplicationContext 父类中可以进行 refresh() 的流程定义,其他子类继承于父类,可以根据自己的不同情况去实现父类模板方法中的方法,自定义实现的方法,我们称之为“钩子方法”。为了 spring 读取文件 refresh()
在多线程下的一个并发安全,所以在 refresh() 方法中加了synchronized 关键字,这里是一个典型的对象锁,可以参考我之前的博客,synchronized 关键字的解析。
3、refresh() 方法中,我们重点看到 ConfigurableListableBeanFactory beanFactory = obtainFreshBeanFactory(); 拿到了 ConfigurableListableBeanFactory 之后,那么这个对象是干嘛的呢?我们来看张图。
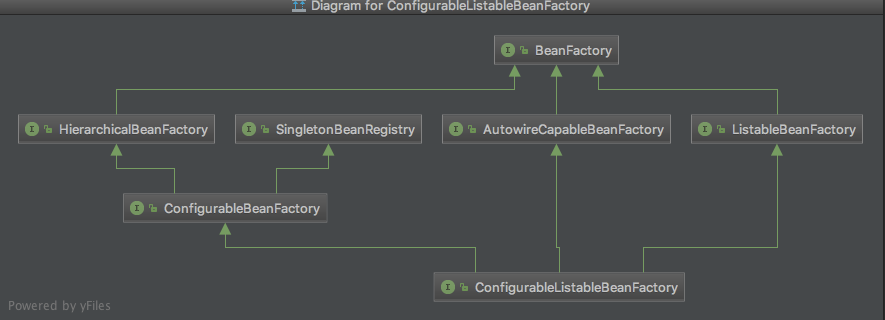
ConfigurableListableBeanFactory 同时继承了3个接口,ListableBeanFactory、AutowireCapableBeanFactory 和 ConfigurableBeanFactory,扩展之后,加上自有的这8个方法,这个工厂接口总共有83个方法,实在是巨大到不行了。这个工厂接口的自
有方法总体上只是对父类接口功能的补充,包含了BeanFactory体系目前的所有方法。因此,ConfigurableBeanFactory 应用上下文环境可以通过 bean 的 name 或者 clazz 获取指定的 bean;也就是说,我们的bean是存储到了一个工厂中,使用的时候,再
从这个工厂中去拿。之后,我们主要注意解析,这些 xml 中定义的元素 是怎样存储到这个一个工厂中的。我们发现 这个工厂可不简单,他里面有成员变量 beanDefinitionMap 存储了一些以 beanName 为key ,beanDefinition 为 value 的 Map。这也就解
释了我们解析的元素放到哪里去了。
4、我们解决了 bean 放到了哪,并且从哪里去取的,所以接下来我们需要解决的问题是怎样放进去?又是怎样取的?跟源码之后,我们发现,要想放到这样一个 map 中,首先解决的首要问题是将 xml 的元素解析为 beanDefinition ,至于读取 xml ,解析
xml,应用了一系列的 xml 解析器啊 之类的,我们可以不去了解,主要了解的方向是怎么转化的,根据不同的类型的元素又是怎样的处理方案。
5、解析标签,spring 将 xml 的标签分为两类,一类自定义标签,一类默认标签
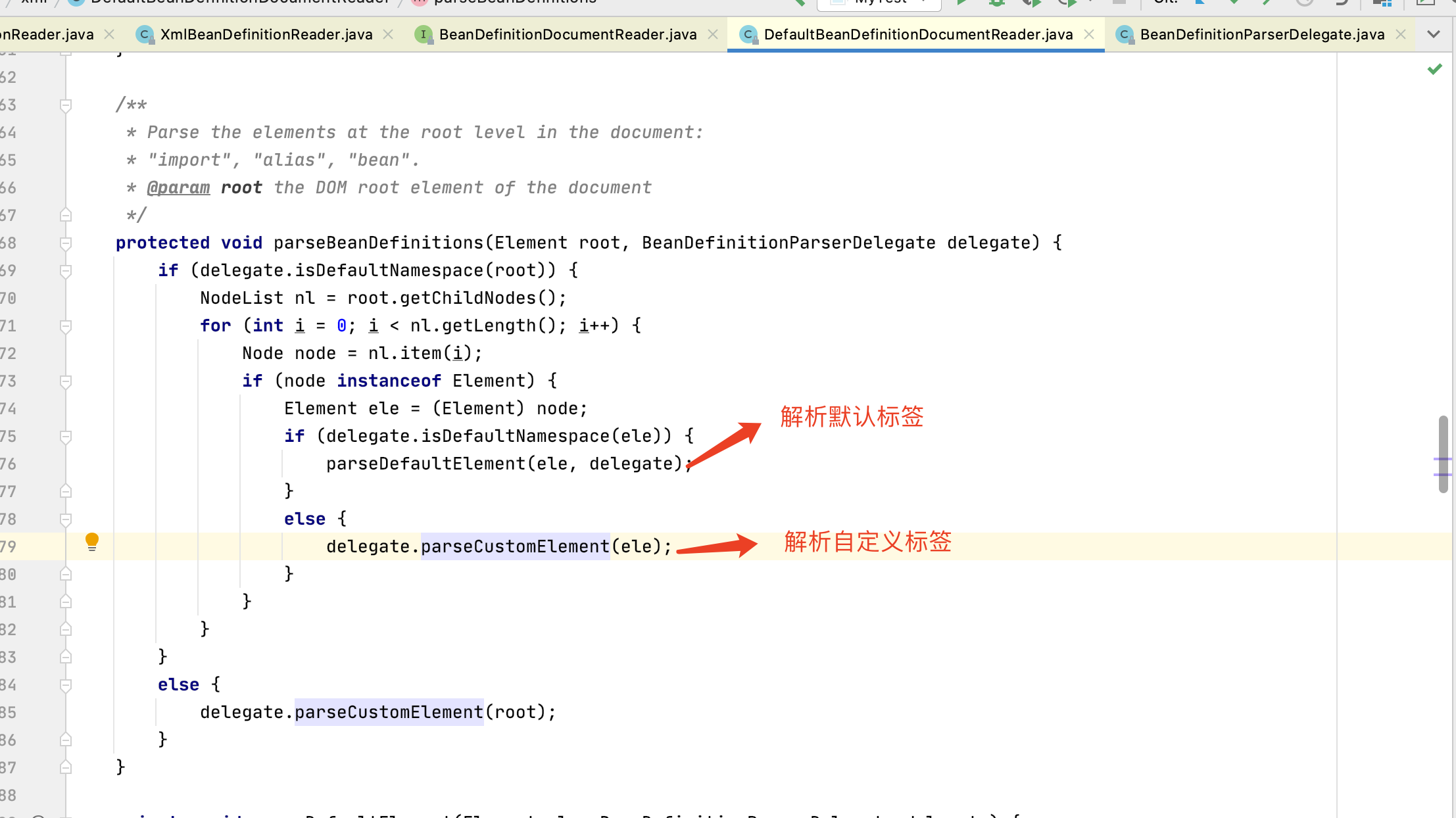
我们首先来看下 默认标签的解析 默认标签的类型主要分为以下四种:import 、 alias 、bean 、 beans
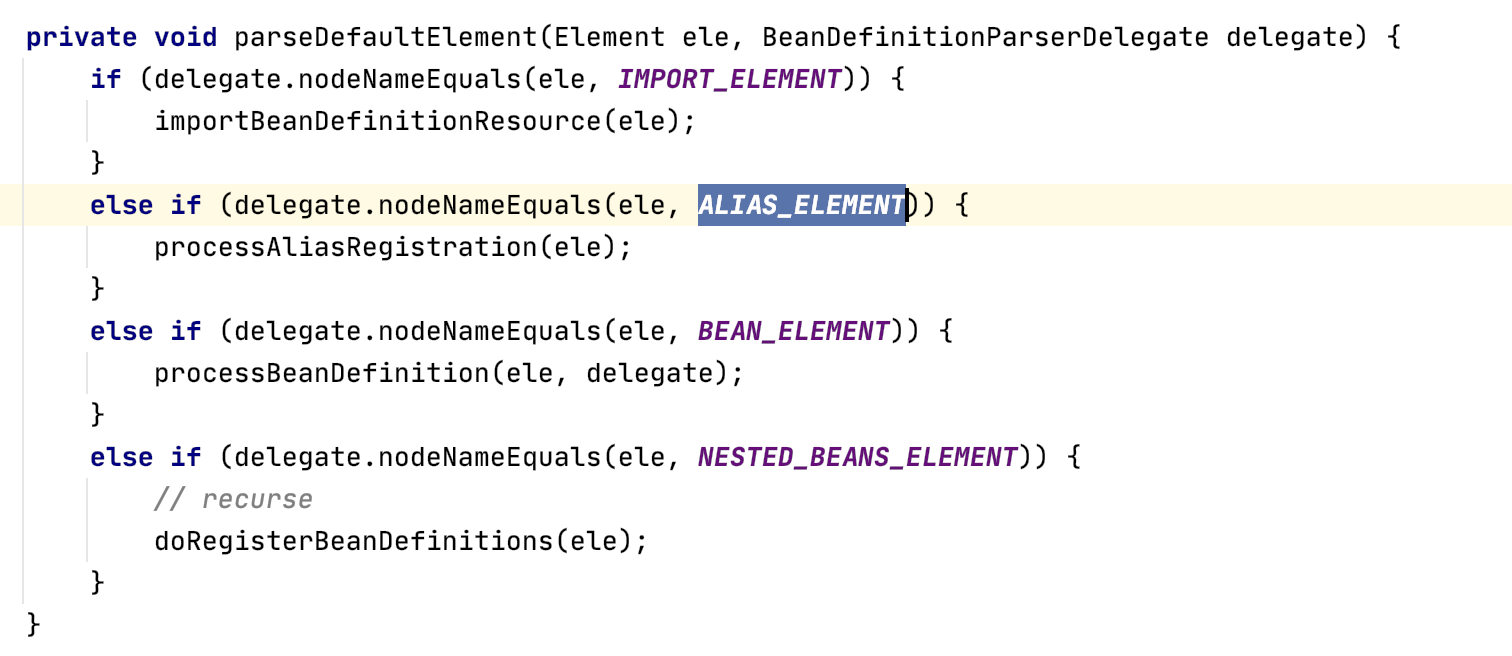
这里我们重点分析以下 bean 标签的解析,也就是 processBeanDefinition() 方法
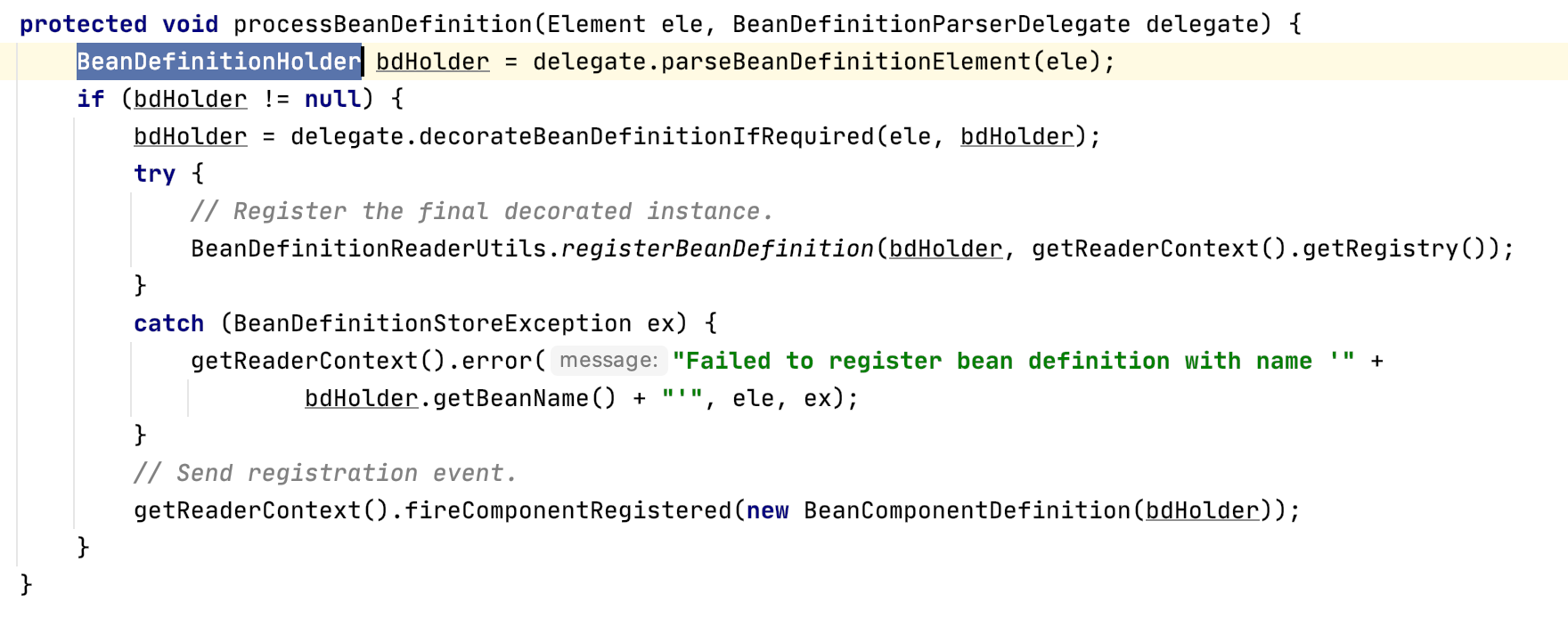
我们发现在这里我们得到了一个 BeanDefinitionHolder 对象,之后的 BeanDefinitionReaderUtils.registerBeanDefinition 的作用就是将 BeanDefinitionHolder 注册到了 工厂(DefaultListableBeanFactory)的 beanDefinitionMap 中。
下面我们来分析下这个 BeanDefinitionHolder 对象 到底有哪些属性,从 xml 中是怎么转化成这个对象的。
BeanDefinitionHolder 对象中包含三个成员变量,分别是 BeanDefinition 对象,一个是 beanName 属性,还有一个是别名属性

BeanDefinition 是一个接口,而 BeanDefinitionHolder 实际在 存储 User Bean的时候 实际上是将 AbstractBeanDefinition 对象放入了 BeanDefinition 对象中,那我们可以针对 AbstractBeanDefinition 的属性进行一波分析,返回 AbstractBeanDefinition 的内部,实际上是 new 了一个 GenericBeanDefinition ,这个类是非常重要的一个类,这个类里面的属性如下:我们可以再做进一步分析。

这些属性,我们来解释一下下。
