算法理论基础
算法:一个计算过程,解决问题的方法。算法是独立存在的一种解决问题的方法和思想。
算法的五大特性
- 输入: 算法具有0个或多个输入
- 输出: 算法至少有1个或多个输出
- 有穷性: 算法在有限的步骤之后会自动结束而不会无限循环,并且每一个步骤可以在可接受的时间内完成
- 确定性:算法中的每一步都有确定的含义,不会出现二义性
- 可行性:算法的每一步都是可行的,也就是说每一步都能够执行有限的次数完成
时间复杂度是用来估计算法运行时间的一个式子(单位)。
时间复杂度:假设存在函数g,使得算法A处理规模为n的问题示例所用时间为T(n)=O(g(n)),则称O(g(n))为算法A的渐近时间复杂度,简称时间复杂度,记为T(n)
“大O记法”:对于单调的整数函数f,如果存在一个整数函数g和实常数c>0,使得对于充分大的n总有f(n)<=c*g(n),就说函数g是f的一个渐近函数(忽略常数),记为f(n)=O(g(n))。也就是说,在趋向无穷的极限意义下,函数f的增长速度受到函数g的约束,亦即函数f与函数g的特征相似。
时间复杂度的几条基本计算规则
- 基本操作,即只有常数项,认为其时间复杂度为O(1)
- 顺序结构,时间复杂度按加法进行计算
- 循环结构,时间复杂度按乘法进行计算
- 分支结构,时间复杂度取最大值
- 判断一个算法的效率时,往往只需要关注操作数量的最高次项,其它次要项和常数项可以忽略
- 在没有特殊说明时,我们所分析的算法的时间复杂度都是指最坏时间复杂度

排序算法(英语:Sorting algorithm)是一种能将一串数据依照特定顺序进行排列的一种算法。
- 排序low B三人组:
- 冒泡排序
- 选择排序
- 插入排序
- 快速排序
- 排序NB二人组:
- 堆排序
- 归并排序
- 没什么人用的排序:
- 基数排序
- 希尔排序
- 桶排序
冒泡排序(英语:Bubble Sort)是一种简单的排序算法。它重复地遍历要排序的数列,一次比较两个元素,如果他们的顺序错误就把他们交换过来。遍历数列的工作是重复地进行直到没有再需要交换,也就是说该数列已经排序完成。这个算法的名字由来是因为越小的元素会经由交换慢慢“浮”到数列的顶端。
冒泡排序算法的运作如下:
- 比较相邻的元素。如果第一个比第二个大(升序),就交换他们两个。
- 对每一对相邻元素作同样的工作,从开始第一对到结尾的最后一对。这步做完后,最后的元素会是最大的数。
- 针对所有的元素重复以上的步骤,除了最后一个。
- 持续每次对越来越少的元素重复上面的步骤,直到没有任何一对数字需要比较。如果冒泡排序中执行一趟而没有交换,则列表已经是有序状态,可以直接结束算法。
def bubble_sort(li): for i in range(len(li)-1): exchange = False for j in range(len(li)-1-i): if li[j]>li[j+1]: li[j],li[j+1] = li[j+1],li[j] exchange = True if not exchange: return True
时间复杂度
- 最优时间复杂度:O(n) (表示遍历一次发现没有任何可以交换的元素,排序结束。)
- 最坏时间复杂度:O(n2)
- 稳定性:稳定
选择排序
选择排序(Selection sort)是一种简单直观的排序算法。它的工作原理如下。首先在未排序序列中找到最小(大)元素,存放到排序序列的起始位置,然后,再从剩余未排序元素中继续寻找最小(大)元素,然后放到已排序序列的末尾。以此类推,直到所有元素均排序完毕。
选择排序的主要优点与数据移动有关。如果某个元素位于正确的最终位置上,则它不会被移动。选择排序每次交换一对元素,它们当中至少有一个将被移到其最终位置上,因此对n个元素的表进行排序总共进行至多n-1次交换。在所有的完全依靠交换去移动元素的排序方法中,选择排序属于非常好的一种。
def select_sort(li): for i in range(len(li)-1): for j in range(i+1,len(li)): if li[i]>li[j]: li[i],li[j] = li[j],li[i]
时间复杂度
- 最优时间复杂度:O(n2)
- 最坏时间复杂度:O(n2)
- 稳定性:不稳定(考虑升序每次选择最大的情况)
插入排序
插入排序(英语:Insertion Sort)是一种简单直观的排序算法。它的工作原理是通过构建有序序列,对于未排序数据,在已排序序列中从后向前扫描,找到相应位置并插入。插入排序在实现上,在从后向前扫描过程中,需要反复把已排序元素逐步向后挪位,为最新元素提供插入空间。
def insert_sort(li): for i in range(1,len(li)): temp = li[i] j = i - 1 while j>=0 and li[j] > temp: li[j + 1] = li[j] j -= 1 li[j+1] = temp
时间复杂度
- 最优时间复杂度:O(n) (升序排列,序列已经处于升序状态)
- 最坏时间复杂度:O(n2)
- 稳定性:稳定
快速排序
快速排序(英语:Quicksort),又称划分交换排序(partition-exchange sort),通过一趟排序将要排序的数据分割成独立的两部分,其中一部分的所有数据都比另外一部分的所有数据都要小,然后再按此方法对这两部分数据分别进行快速排序,整个排序过程可以递归进行,以此达到整个数据变成有序序列。
步骤为:
- 从数列中挑出一个元素,称为"基准"(pivot),
- 重新排序数列,所有元素比基准值小的摆放在基准前面,所有元素比基准值大的摆在基准的后面(相同的数可以到任一边)。在这个分区结束之后,该基准就处于数列的中间位置。这个称为分区(partition)操作。
- 递归地(recursive)把小于基准值元素的子数列和大于基准值元素的子数列排序。
递归的最底部情形,是数列的大小是零或一,也就是永远都已经被排序好了。虽然一直递归下去,但是这个算法总会结束,因为在每次的迭代(iteration)中,它至少会把一个元素摆到它最后的位置去。
def quick_sort(li,start,end): '''快速排序''' #递归推出的条件 if start >= end: return #设置起始元素定位寻找位置的基准元素 mid = li[start] #low为序列左边的由左向右移的游标 low = start # high为序列右边的由右向左移的游标 high = end while low < high: # 如果low与high未重合,high指向的元素不比基准元素小,则high向左移动 while low < high and li[high] >= mid: high -= 1 # 将high指向的元素放到low的位置上 li[low] = li[high] # 如果low与high未重合,low指向的元素比基准元素小,则low向右移动 while low < high and li[low] < mid: low += 1 # 将low指向的元素放到high的位置上 li[high]= li[low] # 退出循环后,low与high重合,此时所指位置为基准元素的正确位置 # 将基准元素放到该位置 li[low] = mid # 对基准元素左边的子序列进行快速排序 quick_sort(li,start,low-1) # 对基准元素右边的子序列进行快速排序 quick_sort(li,low+1,end) li = [54,26,93,17,77,31,44,55,20] quick_sort(li,0,len(li)-1) print(li)
时间复杂度
- 最优时间复杂度:O(nlogn)
- 最坏时间复杂度:O(n2)
- 稳定性:不稳定
归并排序
归并排序是采用分治法的一个非常典型的应用。归并排序的思想就是先递归分解数组,再合并数组。
将数组分解最小之后,然后合并两个有序数组,基本思路是比较两个数组的最前面的数,谁小就先取谁,取了后相应的指针就往后移一位。然后再比较,直至一个数组为空,最后把另一个数组的剩余部分复制过来即可。
def merge(left,right): l,r =0,0 result = [] while l<len(left) and r < len(right): if left[l] < right[r]: result.append(left[l]) l += 1 else: result.append(right[r]) r += 1 result += left[l:] result += right[r:] return result def merge_sort(li): if len(li)<=1: return li num = len(li)//2 print(num) left = merge_sort(li[:num]) right = merge_sort(li[num:]) return merge(left,right) print(merge_sort(li))
树的概念
树(英语:tree)是一种抽象数据类型(ADT)或是实作这种抽象数据类型的数据结构,用来模拟具有树状结构性质的数据集合。它是由n(n>=1)个有限节点组成一个具有层次关系的集合。把它叫做“树”是因为它看起来像一棵倒挂的树,也就是说它是根朝上,而叶朝下的。它具有以下的特点:
- 每个节点有零个或多个子节点;
- 没有父节点的节点称为根节点;
- 每一个非根节点有且只有一个父节点;
- 除了根节点外,每个子节点可以分为多个不相交的子树;
树的术语
- 节点的度:一个节点含有的子树的个数称为该节点的度;
- 树的度:一棵树中,最大的节点的度称为树的度;
- 叶节点或终端节点:度为零的节点;
- 父亲节点或父节点:若一个节点含有子节点,则这个节点称为其子节点的父节点;
- 孩子节点或子节点:一个节点含有的子树的根节点称为该节点的子节点;
- 兄弟节点:具有相同父节点的节点互称为兄弟节点;
- 节点的层次:从根开始定义起,根为第1层,根的子节点为第2层,以此类推;
- 树的高度或深度:树中节点的最大层次;
- 堂兄弟节点:父节点在同一层的节点互为堂兄弟;
- 节点的祖先:从根到该节点所经分支上的所有节点;
- 子孙:以某节点为根的子树中任一节点都称为该节点的子孙。
- 森林:由m(m>=0)棵互不相交的树的集合称为森林;
树的种类
- 无序树:树中任意节点的子节点之间没有顺序关系,这种树称为无序树,也称为自由树;
- 有序树:树中任意节点的子节点之间有顺序关系,这种树称为有序树;
- 二叉树:每个节点最多含有两个子树的树称为二叉树;
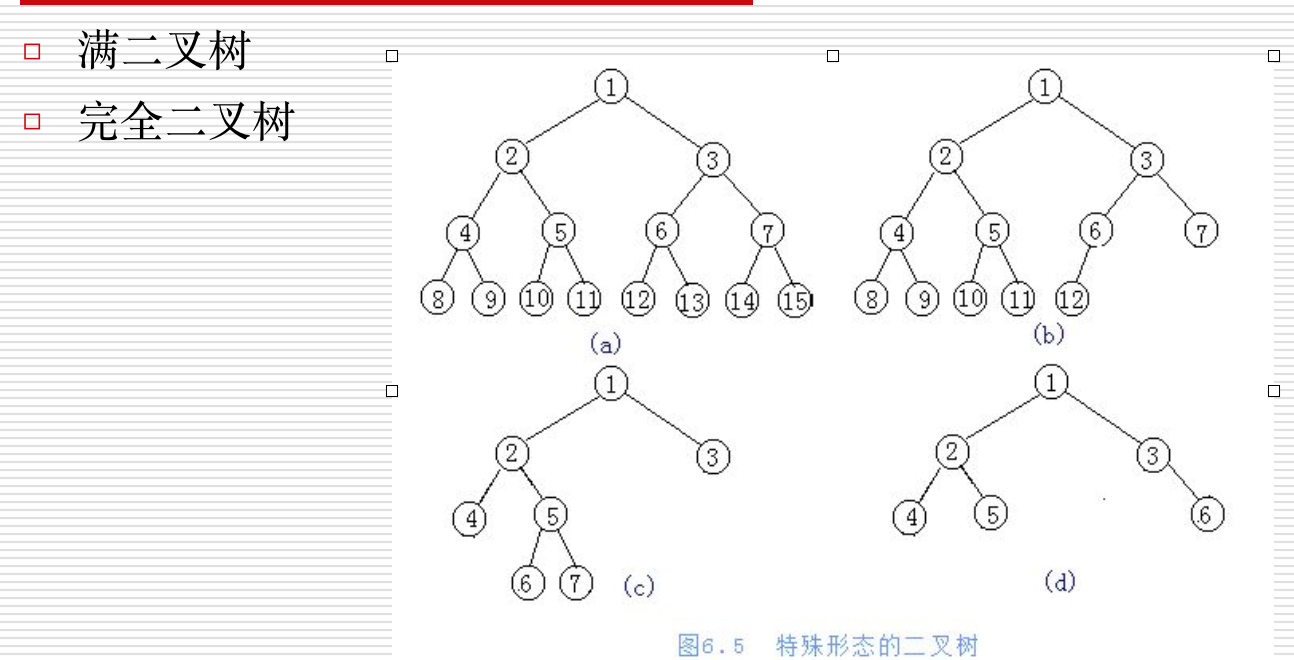
- 完全二叉树:对于一颗二叉树,假设其深度为d(d>1)。除了第d层外,其它各层的节点数目均已达最大值,且第d层所有节点从左向右连续地紧密排列,这样的二叉树被称为完全二叉树,其中满二叉树的定义是所有叶节点都在最底层的完全二叉树;
- 平衡二叉树(AVL树):当且仅当任何节点的两棵子树的高度差不大于1的二叉树;
- 排序二叉树(二叉查找树(英语:Binary Search Tree),也称二叉搜索树、有序二叉树);
- 霍夫曼树(用于信息编码):带权路径最短的二叉树称为哈夫曼树或最优二叉树;
- B树:一种对读写操作进行优化的自平衡的二叉查找树,能够保持数据有序,拥有多余两个子树。
- 二叉树:每个节点最多含有两个子树的树称为二叉树;
两种特殊二叉树:
二叉树的储存方式:
链式储存;
顺序储存;

堆排序:
堆
- 大根堆:一棵完全二叉树,满足任一节点都比其孩子节点大
- 小根堆:一棵完全二叉树,满足任一节点都比其孩子节点小
堆排序过程:
- 建立堆
- 得到堆顶元素,为最大元素
- 去掉堆顶,将堆最后一个元素放到堆顶,此时可通过一次调整重新使堆有序。
- 堆顶元素为第二大元素。
- 重复步骤3,直到堆变空。
def sift(data,low,high): i = low j = 2*i+1 temp = data[i] while j <= high: if j < high and data[j] < data[j+1]: j += 1 if temp < data[j]: data[i] = data[j] i = j j = 2*i + 1 else: break data[i] = temp def heap_sort(data): num = len(data) for i in range(num//2-1,-1,-1): sift(data,i,num-1) for i in range(n-1,-1,-1): data[0],data[i] = data[i],data[0] sift(data,0,i-1)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号