CentOS7.1.x+Druid 0.12 集群配置
原文转载自:https://blog.csdn.net/bigtree_3721/article/details/79583008
先决条件:安装版本列表
本次安装满足下面的条件:
- CentOS v7.3.x
- Druid v0.12.x
- Hadoop v2.9.0 (HDFS)
- MySql v5.6
其中,Mysql 和 Hadoop在别的文章中有讲述,本次安装不在涉及。
一、默认端口
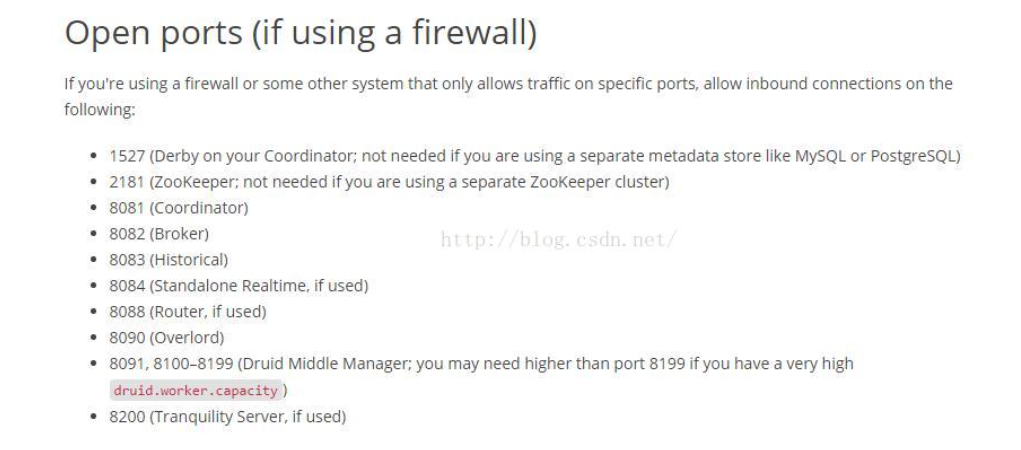
建议用如下的命令停掉CentOS上面的 firewall.
# systemctl stop firewalld.service
二、集群机器IP 安装服务配置
本集群有三个节点
1. master节点: 10.70.27.8
部署druid服务: coordinator node, overlord node(indexing service)
2. slave1节点: 10.70.27.10
部署druid服务: historical node, middleManager node
3. slave2节点: 10.70.27.12
部署druid服务:broker node
另外,在本次设置中,druid的 deep storage(用于保存冷数据)为 Hadoop 的HDFS。
druid 官方软件下载地址:
http://static.druid.io/artifacts/releases/druid-0.12.0-bin.tar.gz
下载后,把上面这个druid软件解压到上面三台主机上的 /opt/druid-0.12.0下面。
官方cluster 集群配置文档如下:
http://druid.io/docs/latest/tutorials/cluster.html
http://druid.io/docs/0.12.0/tutorials/cluster.html
三、配置步骤如下
3.1 配置所有节点(master, slave1,slave2)的 common.runtime.properties文件
3.1.1 修改common.runtime.properties文件
# vi /opt/druid-0.12.0/conf/druid/_common/common.runtime.properties
注意以下的文件内容,别的内容就保持原样。
-
druid.extensions.loadList=["mysql-metadata-storage","druid-hdfs-storage"]
-
druid.startup.logging.logProperties=true
-
druid.zk.service.host=10.70.27.8:2181,10.70.27.10:2181,10.70.27.12:2181
-
druid.zk.paths.base=/druid
-
druid.metadata.storage.type=mysql
-
druid.metadata.storage.connector.connectURI=jdbc:mysql://10.70.27.12:3306/druid
-
druid.metadata.storage.connector.user=druid
-
druid.metadata.storage.connector.password=yourpassword
-
druid.storage.type=hdfs
-
druid.storage.storageDirectory=hdfs://1.2.3.4:9000/data/druid/segments
-
druid.indexer.logs.type=hdfs
-
druid.indexer.logs.directory=hdfs://1.2.3.4:9000/data/druid/indexing-logs
如果你先选择用mysql存metadata的话,则还需要按照下面的步骤做额外的配置。
1: 官方包里面没有把mysql打进去,自己得去下mysql storage。
官方下载这个storage的连接如下:
http://static.druid.io/artifacts/releases/mysql-metadata-storage-0.12.0.tar.gz
官方解释的连接: http://druid.io/downloads.html
本文是用mysql存放的(如上设置的那样),需要下载这个tar.gz,
然后 copy mysql-metadata-storage-0.12.0.tar.gz 到 三台机器上的/opt/druid-0.12.0/extensions。
然后执行下面的操作:
# cd /opt/druid-0.12.0/extensions
# tar zxvf mysql-metadata-storage-0.12.0.tar.gz
2. 登陆到所要连接的mysql服务器上,执行下面的操作:
# /usr/bin/mysql -uroot -p<root's password >
grant all privileges on druid.* to 'druid'@'%' identified by 'druid';
mysql> CREATE DATABASE druid DEFAULT CHARACTER SET utf8;
mysql> grant all privileges on druid.* to 'druid'@'%' identified by 'druid';
mysql> flush privileges;
Query OK, 0 rows affected (0.01 sec)
mysql>quit;
3.1.2 拷贝hadoop配置文件
本次安装用hadoop的hdfs作为数据存放地,故要求把Hadoop配置XML文件(core-site.xml,hdfs-site.xml,yarn-site.xml,mapred-site.xml)从hadoop集群中拷贝到 各个druid主机的/opt/druid-0.12.0/conf/druid/_common/下面。
针对这个配置的解释,见官方文档连接如下:http://druid.io/docs/latest/tutorials/cluster.html
3.1.3 连接hadoop配置
vi /opt/druid-0.12.0/conf/druid/middleManager/runtime.properties
druid.indexer.task.hadoopWorkingPath=/tmp/druid-indexing3.1.4 根据安装计划,指定主机地址(IP或者域名)
在本次安装中,修改如下:
vi /opt/druid-0.12.0/conf/druid/broker/runtime.properties
druid.host=10.70.27.12
vi /opt/druid-0.12.0/conf/druid/coordinator/runtime.properties
druid.port=10.70.27.8
vi /opt/druid-0.12.0/conf/druid/overlord/runtime.properties
druid.port=10.70.27.8
vi /opt/druid-0.12.0/conf/druid/historical/runtime.properties
druid.port=10.70.27.10
vi /opt/druid-0.12.0/conf/druid/middleManager/runtime.properties
druid.port=10.70.27.10
3.1.4 调节性能参数
如果你是按cluster方式安装的,则必须确保druid的各个服务器 JVM 启动参数满足下面的条件。
官方文档见:http://druid.io/docs/0.12.0/tutorials/cluster.html
官方文档提示:要调节一下下面的参数,特别是下面的MaxDirectMemory,
- Keep -XX:MaxDirectMemory >= numThreads*sizeBytes, otherwise Druid will fail to start up..。
该参数指定了DirectByteBuffer能分配的空间的限额,如果没有显示指定这个参数启动jvm,默认值是xmx对应的值。
- 另外,即使各个druid服务器软件能起来,在跑任务也有可能出现DirectMemory内存不足问题。
下面的log就是 Running Tasks碰到的坑,通过overlord console gui 比如 http://[overload server ip ]:8090/console.html看到的error log
"
2018-03-22T12:44:53,405 ERROR [main] io.druid.cli.CliPeon - Error when starting up. Failing. com.google.inject.ProvisionExcept
ion: Unable to provision, see the following errors:
Not enough direct memory. Please adjust -XX:MaxDirectMemorySize, druid.processing.buffer.sizeBytes, druid.processing.numThreads, or druid.processing.numMergeBuffers: maxDirectMemory[1,908,932,608],”
memoryNeeded[3,758,096,384]=druid.processing.buffer.sizeBytes[536,870,912]*(druid.processing.numMergeBuffers[2]+druid.processing.numThreads[4] + 1)"。
注意蓝色字体,说明index server的direct memory 不足,故要修改下面选项的参数。
注意MaxDirectMemorySize的数值是由你自己的设置决定的
计算公式为:MaxDirectMemorySize=druid.processing.buffer.sizeByte *(druid.processing.numMergeBuffers + druid.processing.numThreads + 1)
修改参数方式:
vi /opt/druid-0.12.0/conf/druid/middleManager/runtime.properties
然后加入下面绿色的选项,
druid.indexer.runner.javaOpts=-server -Xmx6g -XX:MaxDirectMemorySize=4g -Duser.timezone=UTC -Dfile.encoding=UTF-8 -Djava.util.loggi
保存文件,重启middleManager,就可以搞定问题。
三、启动集群命令
把上面的整个/opt/druid-0.12.0目录打成包,然后传到每个节点,再展开。 然后分别到每个节点(master, slave1,slave2)去启动相应的服务,命令如下:
on master,启动 coordinator 和 overlord 服务
#cd /opt/druid-0.12.0
# bin/init
然后执行下面的命令:
-
java `cat conf/druid/coordinator/jvm.config | xargs` -cp "conf/druid/_common:conf/druid/coordinator:lib/*" io.druid.cli.Main server coordinator
-
java `cat conf/druid/overlord/jvm.config | xargs` -cp "conf/druid/_common:conf/druid/overlord:lib/*" io.druid.cli.Main server overlord
on slave1,启动 historical 服务 和 middleManager 服务
#cd /opt/druid-0.12.0
# bin/init
然后执行下面的命令:
-
java `cat conf/druid/coordinator/jvm.config | xargs` -cp "conf/druid/_common:conf/druid/coordinator:lib/*" io.druid.cli.Main server coordinator
-
java `cat conf/druid/overlord/jvm.config | xargs` -cp "conf/druid/_common:conf/druid/overlord:lib/*" io.druid.cli.Main server overlord
on slave2, 启动broker 服务
# bin/init
然后执行下面的命令
java `cat conf/druid/broker/jvm.config | xargs` -cp conf/druid/_common:conf/druid/broker:lib/* io.druid.cli.Main server broker四、验证集群
1. http://10.70.27.8:8090/console.html (overlord node)
2. http://10.70.27.8:8081(coordinator node)
3. 登陆到hadoop namenode,去检查druid信息。
#/opt/hadoop-2.9.0/bin/hadoop fs -ls /druid
Found 1 items
drwxr-xr-x - root supergroup 0 2018-03-22 15:00 /druid/indexing-logs
五、push 方式数据源输入设置
5.1 代码下载
Tranquility 代码下载: http://druid.io/downloads.html
本次选择的是 tranquility-distribution-0.8.2.tgz.
选择一个机器,比如broker运行的那个机器,copy 上面的那个tranquility-distribution-0.8.2.tgz 到/op 目录下。
#tar zxvf tranquility-distribution-0.8.2.tgz
5.2 用 Tranquility server 接受数据并转发到druid里面
官方教材:http://druid.io/docs/0.12.0/tutorials/tutorial-streams.html
基本思路通过http post请求,把数据以jason格式发给Tranquility server,然后Tranquility server会转发给后面的druid。
1) 修改配置
# cd /opt/tranquility-distribution-0.8.2/conf
# cp kafka.json.example kafka.json; cp server.json.example server.json
然后改变kafka.json 和 server.json 里面的 "zookeeper.connect" 为如下的数值。
"properties" : {
"zookeeper.connect" : "10.70.27.8:2181,10.70.27.10:2181,10.70.27.12:2181",
"zookeeper.timeout" : "PT20S",
"druid.selectors.indexing.serviceName" : "druid/overlord",
"druid.discovery.curator.path" : "/druid/discovery",
"kafka.zookeeper.connect" : "localhost:2181",
"kafka.group.id" : "tranquility-kafka",
"consumer.numThreads" : "2",
"commit.periodMillis" : "15000",
"reportDropsAsExceptions" : "false"
}
2) 启动 Tranquility server
# bin/tranquility server -configFile conf/server.json5.3 从kafka 里面消费数据,然后push到druid
基本思路设置Tranquility kafka server好后,启动它,它就是从指定的kafka中去消费数据,然后转发给后面的druid。
这里就不详细说了,请参见官方文档: http://druid.io/docs/0.12.0/tutorials/tutorial-kafka.html
对连接过程的理解:
我们向tranquility发post HTTP请求来添加数据,而tranquility收到数据后,则向overlord发送任务模板,overlord接收到任务模板后,会根据任务分配策略发送给某个MiddleManager,MiddleManager启动一个java进程, 即peon。peon可以理解为一个http server。最后tranquility是向这个http server直接发送数据,而不再依赖overlord和MiddleManager节点。可以理解为我们通过集成tranqulity可以和每个peon创建一个连接。
一些人的误区主要体现在: consumer将数据发送给了overlord,是通过overlord转发数据给peon,这样理解是错误的。iddleManager启动一个java进程, 即peon。peon可以理解为一个http server。最后 consumer是向http server直接发送数据,而不再依赖overlord和MiddleManager节点。可以理解为我们通过集成tranqulity可以和 每个peon创建一个连接。
一些人的误区主要体现在: consumer将数据发送给了overlord,是通过overlord转发数据给peon,这样理解是错误的。
七 分布式环境下的task resume和middle node重启讨论
给overlord设置如下参数,可以开启task重启模式
-
druid.indexer.runner.type=remote
-
druid.indexer.storage.type=metadata
-
druid.indexer.task.restoreTasksOnRestart=true
http://druid.io/docs/latest/configuration/indexing-service.html
https://www.cnblogs.com/xd502djj/p/6408979.html
八 参考文档
- 1: 关于Hive和druid (0.9.x及其以后)的集成
- 集成 jira: https://issues.apache.org/jira/browse/HIVE-14217
- 集成介绍的官方page: https://cwiki.apache.org/confluence/display/Hive/Druid+Integration
2:参考文件:
http://blog.csdn.net/fenghuibian/article/details/53216141
druid.io_druid.io本地集群搭建 / 扩展集群搭建
